Partie 5 - Exploiter un BO - pile exécutable – contrôle de EIP/RIP (2/4)
Exploiter un stack buffer overflow : pile exécutable – contrôle de EIP/RIP (2/4)
Nous avons précédemment réussi à contrôler eip en faisant attention à bien ajuster notre payload. Dans cette partie, nous allons réaliser une exécution de code arbitraire ; plus précisément, nous allons tenter d’ouvrir un terminal à l’aide d’un shellcode.
Les shellcodes
Un shellcode (ou code encoquillé 🥖) est un ensemble d’instructions généralement injecté et exécuté dans le cadre d’une exploitation de vulnérabilités. Il tient son nom du fait qu’il est généralement utilisé pour ouvrir un shell car cela permet d’exécuter des commandes bash et donc de réaliser pas mal de choses (lire des fichiers, en écrire, en supprimer, ouvrir des connexions …).
Il est bien plus pratique d’ouvrir et d’afficher /etc/shadow avec cat /etc/shadow que de réaliser l’équivalent en assembleur. C’est pourquoi l’objectif de ces bouts d’assembleurs est très souvent d’ouvrir un shell mais il est également possible d’en faire autre chose.
Un autre avantage du shellcode est qu’une fois dedans, il est possible d’exécuter pas mal de fonctions de la libc grâce aux appels système. Vous le savez peut-être déjà mais plusieurs fonctions de la libc (execve, read, open, close …) ne sont que des surcouches d’appels système. Ainsi, en exécutant directement l’appel système execve, nous n’avons même pas besoin de savoir à quelle adresse est localisée la fonction.
Un shellcode n’est ni plus ni moins que de l’assembleur que l’on fait exécuter à un programme vulnérable.
Vous pouvez en trouver une multitude d’exemples sur le site shell-storm permettant d’exécuter différentes commandes et ce, pour diverses architectures. Bah oui ! Vu que le shellcode est de l’assembleur, il faudra l’adapter en fonction de l’architecture : x86, x86_64, ARM etc.
Vous pouvez trouver sur le site syscall.sh la liste de tous les appels système Linux ainsi que leur convention d’appel en fonction des différentes architectures.
L’écriture d’un shellcode
L’écriture d’un shellcode est tout un art 🖌️. Plus sérieusement, lorsque l’on écrit un shellcode il faut souvent faire attention à trois choses :
- certains caractères sont indirectement interdits : par exemple, si votre shellcode est copié en mémoire avec une fonction du type
strncpy, la copie s’arrête au premier octet nul. Si votre shellcode contient des opcodes contenant des octets nuls, il ne sera pas totalement copié en mémoire ; - la taille du shellcode : en fonction de la manière dont il sera possible d’injecter le shellcode, il va falloir attention au nombre d’octets que l’on pourra injecter en mémoire ;
- certains appels système peuvent être bloqués : par mesure de sécurité, il est possible d’interdire l’exécution de certains syscalls dans un programme à l’aide de seccomp. Après tout, pourquoi laisser la possibilité d’exécuter le syscall
execvedans un programme qui ne fait que dire Bonjour 😏 ?
Nous nous intéresserons plus loin à seccomp grâce à un chapitre dédié.
Nous concernant, quelles sont les limitations auxquelles nous allons devoir faire face ?
1️⃣ Concernant les caractères interdits, le manuel de gets nous dit qu’il arrête de lire l’entrée lorsqu’il lit un saut de ligne (0x0a en ASCII). Nous pouvons donc utiliser sans problème des octets nuls. En revanche, notre shellcode ne devra pas contenir de sauts de lignes.
2️⃣ Pour ce qui est de la taille, ça dépend où est-ce que l’on compte écrire notre shellcode. Nous allons voir cela un peu plus tard.
3️⃣ Enfin, comme le programme n’a pas été protégé par seccomp, nous pouvons utiliser n’importe quel appel système 🥳.
Où l’écrire ✏️
Une question naturelle se pose : où écrire le shellcode ?
Étant donné qu’il est nécessaire de l’écrire dans une zone mémoire ayant les droits rwx, nous n’avons pas 36000 solutions. En l’occurrence, seule la pile satisfait ces contraintes dans le programme que l’on souhaite exploiter.
Même lorsque la pile n’est pas exécutable, il est souvent envisageable d’utiliser un shellcode. Il suffit de pouvoir créer une zone mémoire avec les droits
rwx.Toutefois, pour être honnête avec vous, cette astuce est plus facile à dire qu’à faire. En effet, il faut avoir assez de marge dans l’exploitation pour réaliser un appel à
mprotectet parfois mêmemmap.
Nous savons que nous voulons injecter nos instructions dans la pile, mais comment ?
On peut pas simplement le mettre dans notre payload puis sauter dedans ?
C’est une très bonne idée ! Nous avons la main sur l’entrée utilisateur donc autant en profiter. Comme le contenu du padding de AAAA..A n’est pas important, nous pouvons y mettre les opcodes de notre shellcode. De plus, nous pourrons déterminer via gdb l’adresse de la première instruction. Ainsi, nous mettrons cette adresse dans eip afin de sauter dans notre “code”.
Nous avons environ 256 octets de marge pour y insérer nos instructions, vous verrez que c’est largement suffisant.
Et si le buffer était beaucoup trop petit, on aurait fait comment ?
Si nous n’avons pas assez de marge pour saisir tous les opcodes depuis l’entrée utilisateur, il reste une autre solution : les variables d’environnement !
Les variables d’environnement
J’ai longuement hésité pour savoir où placer ce sous-chapitre. Finalement je l’ai laissé ici.
Bien que nous n’allions pas directement utiliser les variables d’environnement, vous verrez que nous allons vite nous y confronter. Les comprendre ici nous permettra de les appréhender plus facilement la prochaine fois que nous y ferons face.
Si vous êtes adepte du monde Linux, vous en avez sûrement déjà utilisées. Les variables d’environnement sont utilisées pour divers usages, mais ce n’est pas notre sujet !
Ce qui nous intéresse en pwn est de savoir comment les utiliser afin d’en tirer profit lors de l’exploitation d’une vulnérabilité. Énoncé ainsi, je suis sûr que certains d’entre vous froncent déjà les sourcils et se demandent quel est le rapport entre notre programme et les variables d’environnement.
Tout d’abord, il existe principalement deux manières de trouver et afficher ces variables dans gdb :
- via l’argument
envpdemain(plus pénible) ; - via la variable globale de la libc
environ(plus facile).
Via main
Pour la première méthode, il faut savoir que main prend en réalité 3 arguments : argc, argv et envp.
Celui qui nous intéresse est char **envp qui est un tableau de pointeurs vers des chaînes de caractères (comme argv) qui sont, justement, nos variables d’environnement !
Vous pouvez lister vos variables d’environnement dans bash avec la commande
env.
Vous pouvez donc mettre un point d’arrêt à la première instruction de main et afficher le 3ème argument qui est envp :
 Quand on affiche quelques valeurs de
Quand on affiche quelques valeurs de envp on tombe sur plusieurs pointeurs tous situés … sur la pile ! Voyez par vous-mêmes :

En affichant la première chaîne de caractère on tombe bien sur une variable d’environnement :

En ajoutant une variable d’environnement, par exemple, avec export SHELLCODE=$(printf '\xef\xbe\xad\xde'), on pourra écrire 0xdeadbeef dans notre pile. De manière analogue, il est possible d’y mettre les opcodes de notre shellcode pour qu’il se retrouve dans la pile.
Nous utiliserons cette méthode en détails un peu plus tard. Pour l’instant, utilisons simplement l’entrée utilisateur pour y insérer les opcodes.
Via environ
L’autre manière d’afficher les variables d’environnement (plus précisément envp) est d’afficher le contenu de la variable globale environ :

Une manière plus esthétique d’afficher les variables d’environnement est d’utiliser, par exemple, la commande gdb suivante :

Quand l’ASLR est activée, réussir à afficher
environpermet de savoir vers quelles adresses se situe la pile.
Finalement, voici comment est agencée la pile :
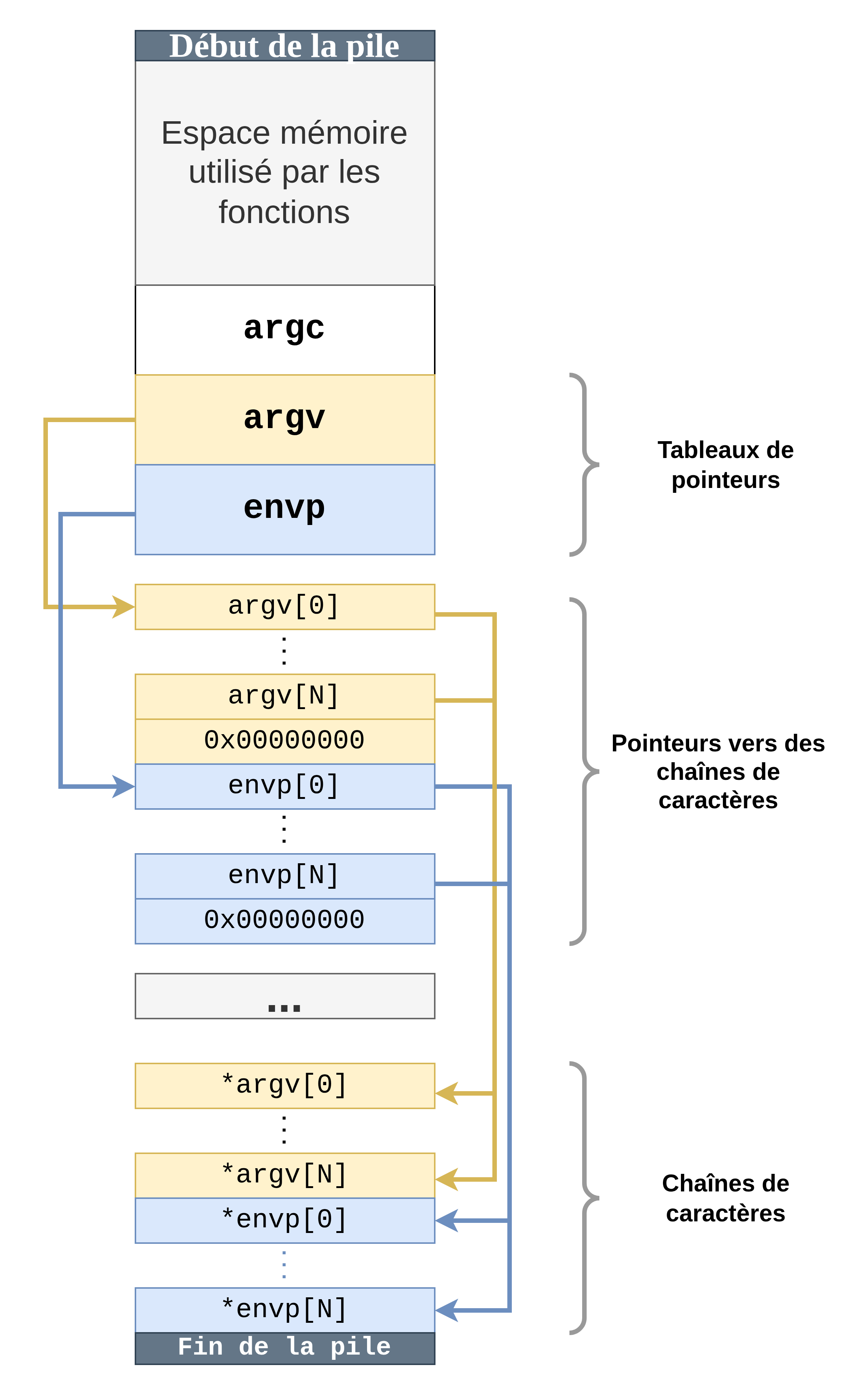
Nous avons jusqu’à présent principalement utilisé la partie haute de la pile qui est utilisée par les fonctions du programme. C’est en quelque sorte ici que se promènent esp et ebp. Pour ce qui est de la fin de la pile, elle est située immédiatement après la dernière variable d’environnement.
Comment l’écrire ?
Tout d’abord, rappelons l’objectif que nous souhaitons atteindre avec cette exécution de code : ouvrir un shell.
L’une des manière les plus simples est d’utiliser l’appel système execve avec les arguments suivants : execve("/bin/sh",NULL,NULL) car nous n’avons besoin ni argv ni de envp.
D’après la doc’, voici l’ordre des arguments de execve :

Ainsi que la convention d’appel x86 sous Linux :
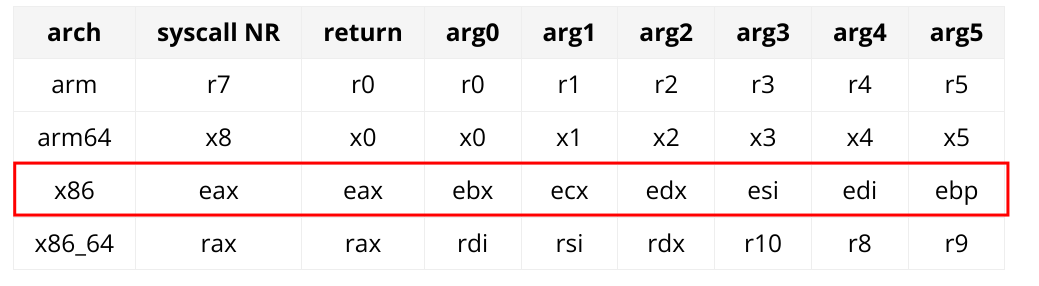
Il faut donc que l’on mette :
- l’adresse de
"/bin/sh"dansebx(filename) ; 0dansecx(argv) ;0dansedx(envp) ;0xbdanseaxqui est le numéro du syscallexecve.
Une fois que cela sera fait, il suffira d’exécuter l’instruction int 0x80, qui est l’équivalent de l’instruction syscall en x86, pour que l’appel système soit exécuté.
Pour ce qui est de la chaîne de caractères "/bin/sh", nous pouvons également la mettre dans le buffer prenom. Nous avons donc au final une entrée utilisateur de la forme suivante : "/bin/sh\x00" + shellcode + "AA...A" + reste_du_payload.
Pour trouver l’adresse de /bin/sh\x00 il suffit de trouver l’adresse de prenom via gdb étant donné que cette chaîne de caractères est placée au début de l’endroit ou est stockée l’entrée utilisateur, son adresse est donc la même que celle de prenom. Pour ma part, l’adresse en question est 0xffffc690, dans votre cas cette adresse sera sûrement différente.
Le shellcode que nous allons utiliser est le suivant :
1
2
3
4
5
mov ebx, 0xffffc690 ; Adresse a adapter
mov ecx, 0
mov edx, 0
mov eax, 0x0b
int 0x80
Veillez à bien adapter les adresses que vous utilisez dans votre payload final, notamment dans le shellcode. Si vous ne le faites pas, il y a de grandes chances que l’exploit ne fonctionne pas 🙄.
Vous avez vu ? Rien de bien compliqué au final. Vérifions tout de même sa taille et l’absence du caractère 0x0a (saut de ligne). Nous pouvons utiliser defuse.ca pour désassembler ces instructions et en récupérer les opcodes.
Voici notre shellcode : \xBB\x90\xC6\xFF\xFF\xB9\x00\x00\x00\x00\xBA\x00\x00\x00\x00\xB8\x0B\x00\x00\x00\xCD\x80 ! Il fait 22 caractères et ne contient pas de sauts de lignes 😎.
En réalité, le fait de ne pas être contraint d’éviter les octets nuls nous permet d’écrire un shellcode assez trivialement, sans trop de difficulté. Il suffit seulement de savoir ce que l’on doit mettre dans chacun des registres et le tour est joué.
L’exécuter !
Nous avons (presque) tous les éléments clés en main pour ouvrir exploiter le programme afin d’ouvrir un terminal. Pour cela, il va falloir exécuter notre shellcode, rien de plus simple que d’y plonger en retournant depuis le main.

Déterminons ensemble l’adresse à laquelle sauter. Ce n’est pas très compliqué sachant que le shellcode est situé immédiatement après /bin/sh\x00 qui comporte 8 caractères. Dans mon cas l’adresse sera donc 0xffffc690 + 8 = 0xffffc698 (⚠️ à adapter selon vos adresses).
Voici le payload final :
1
/bin/sh\x00\xbb\x90\xc6\xff\xff\xb9\x00\x00\x00\x00\xba\x00\x00\x00\x00\xb8\x0b\x00\x00\x00\xcd\x80AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBCCCCDDDD\xc0\xc7\xff\xffEEEEFFFFGGGGHHHHIIIIJJJJKKKK\x98\xc6\xff\xff
Ici trois adresses sont à adapter :
\x90\xc6\xff\xff;\xc0\xc7\xff\xff;\x98\xc6\xff\xff.
Lorsque l’on lance le programme en utilisant cette entrée dans gdb on observe ceci :
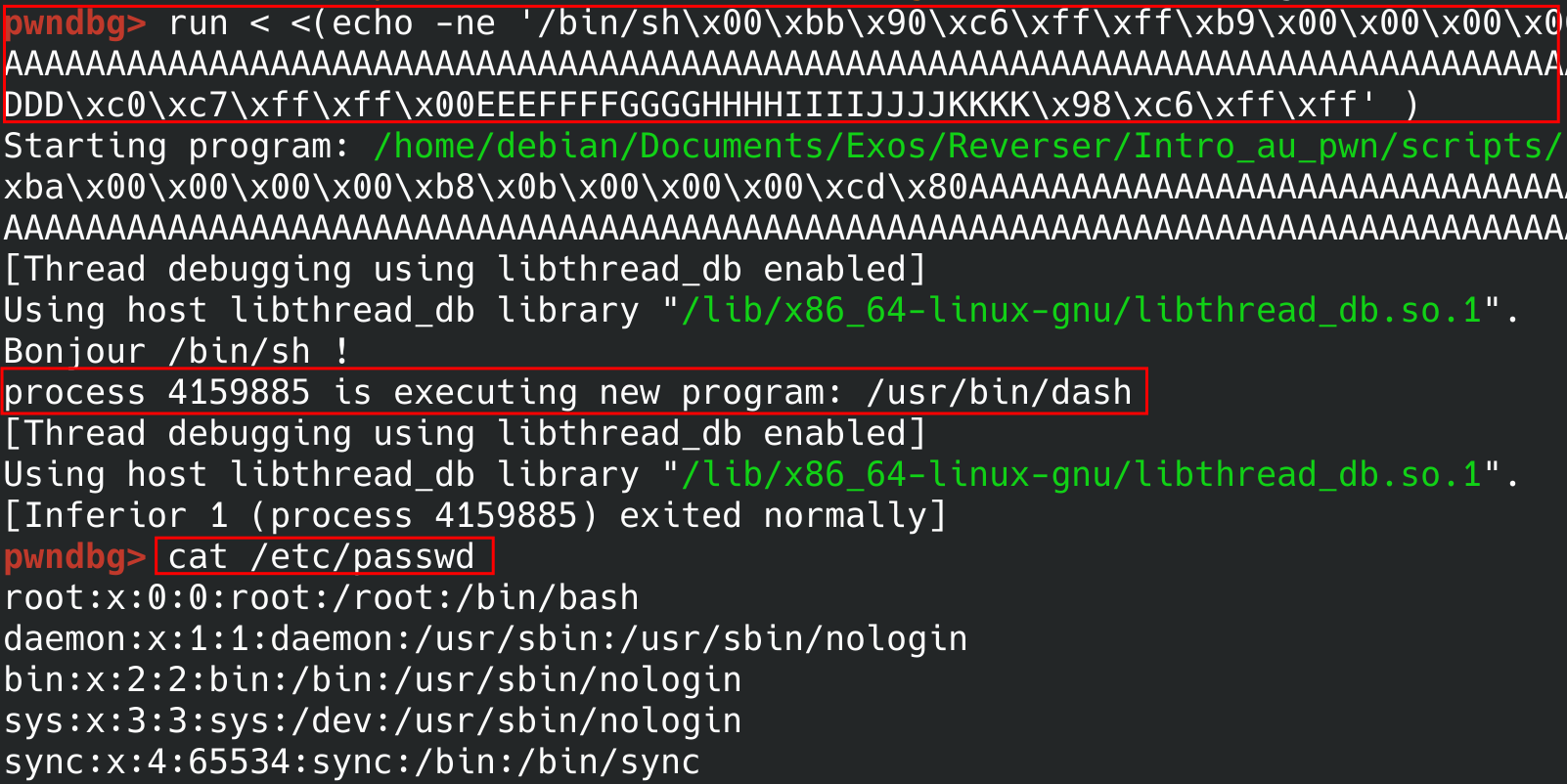
Nous avons réussi à ouvrir un shell ! Pour preuve, la commande cat /etc/passwd a bien fonctionné !
Si la commande
cat (...)ne fonctionne pas dans gdb mais que vous voyez bien le messageprocess XXXXXXX is executing new program: (...)c’est que le payload est correct.
Le programme réellement exécuté est
/usr/bin/dashcar/bin/shest un lien symbolique vers ce programme.Vous pouvez le constater en exécutant la commande :
ls -l /bin/sh.
Exécution sans l’aide d’un débogueur
Nous avons réussi à exploiter la vulnérabilité … à travers gdb. Qu’en est-il dans la “vraie vie” ?
Essayons avec echo -ne '[VOTRE_PAYLOAD]' | ./vuln :

Aïe 🤕. Ce n’est vraiment pas ce à quoi on s’attendait … Affaire à suivre 🧐.
📋 Synthèse
Bon, c’est tout pour ce chapitre, nous investiguerons la cause de ce SIGSEGV dans le prochain chapitre.
Voici une synthèse de ce que nous avons vu au cours de ce chapitre :
- lors du précédent chapitre, nous avions réussi à contrôler
eip; - ensuite, nous avons vu une technique permettant de réaliser une exécution de code arbitraire : le shellcode ;
- cette technique peut, ici, être déployée de deux manières :
- en utilisant l’entrée utilisateur, c’est la méthode que nous avons choisi d’utiliser ;
- en utilisant des variables d’environnement ;
- il y a souvent plusieurs contraintes auxquelles il est nécessaire de faire attention lors de l’écriture d’un shellcode :
- certains caractères ne doivent pas y être présents ;
- sa taille est limitée ;
- certains appels système peuvent être bloqués ;
- nous avons utilisé l’appel système
execvequi nous permet d’ouvrir un terminal en lançant le programme/bin/sh; - on a réussi à ouvrir un shell … dans le débogueur, prochaine étape : ouvrir un shell sans l’aide de ce dernier !