Partie 3 - Comprendre la vulnérabilité du stack Buffer Overflow
Comprendre la vulnérabilité du stack buffer overflow
Je sais à quel point ça peut être pénible d’enchaîner les notions théoriques sans pratiquer. Toutefois ces rappels et informations supplémentaires sont nécessaires afin de comprendre l’environnement dans lequel s’exécutent les programmes que nous allons exploiter.
Comme promis, nous n’allons pas nous taper que de la théorie et nous allons jongler avec un peu de pratique. Préparez-vous à réaliser votre premier pwn !

Stack buffer overflow
Le stack buffer overflow (dépassement de mémoire tampon sur la pile 🇫🇷) est généralement la première vulnérabilité que l’on découvre et exploite car elle est assez accessible dans des programmes peu protégés.
Ne pas confondre stack buffer overflow et stack overflow (d’où le nom du site éponyme) qui sont deux bugs différents. Le point commun est qu’il s’agit dans les deux cas d’un dépassement de mémoire dans la pile.
Un stack overflow survient lorsque la pile d’exécution dépasse l’espace mémoire qui lui est alloué. Cela peut arriver, par exemple, en appelant une fonction récursive sans condition d’arrêt.
Quant au stack buffer overflow, nous allons voir ci-après en quoi cela consiste 😉.
Comme son nom le précise, cette vulnérabilité se situe dans la pile. En effet, il est possible d’avoir des buffer overflow dans le tas, .bss, .data. Selon le lieu où a lieu le dépassement, la manière d’exploiter ne sera pas la même.
Voici le programme vulnérable que nous allons utiliser :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include "stdio.h"
void goal()
{
puts("Hop hop hop, comment êtes vous arrivés ici ?");
return;
}
int main()
{
char prenom[32] = {0};
gets(prenom);
printf("Bonjour %s !\n",prenom);
return 0;
}
Un programme simple comme bonjour, c’est le cas de le dire. Notre objectif sera d’appeler la fonction goal sachant qu’elle n’est appelée à aucun moment dans notre programme.
Pour le compiler nous utilisons gcc -no-pie -fno-stack-protector main.c -o vuln .
Vous pouvez également le télécharger ci-dessous si vous avez une distribution différente de Ubuntu / Debian ou que vous souhaitez avoir exactement le même environnement d’exécution.
- ⬇️ Téléchargement : pwn-stack-vuln.zip
- 🔎 SHA256 & Analyse Virus Total : ed1892516dfb89d56069445ddd5c3ed4144ebc93128f64839435a39e69c38159
L’archive contient un Dockerfile afin que vous puissiez avoir un terminal dans le conteneur et y exécuter le programme sans soucis avec :
1
2
3
4
5
# Construction
docker build -t pwn-stack-vuln .
# Lancement
docker run -it --rm --cap-add=SYS_PTRACE --security-opt seccomp=unconfined pwn-stack-vuln
Pour plus d’informations sur les exercices et challenges utilisables via Docker, c’est par ici.
Même après la compilation, la fonction
goalreste présente dans le code bien qu’elle ne soit jamais appelée. Vous pouvez d’ailleurs la voir en désassemblant le programme avecobjdump.En revanche, si on active les options d’optimisation de gcc tels que
-O3, elle sera supprimée du programme car il s’agit de code mort qui ne sera (en théorie 😏) jamais exécuté.
Concernant les options utilisées :
-no-pie: nous l’avons déjà utilisée à maintes reprises, cela permet de désactiver le fait que notre code (ses instructions) puisse être chargé à des adresses différentes et aléatoires d’une exécution à une autre ;-fno-stack-protector: nous désactivons une autre protection appelée stack cookie ou canaris en français. C’est une protection au niveau de la pile, nous la désactivons, pour l’instant, afin d’exploiter plus facilement le programme.
Au fur et à mesure que nous allons avancer dans ce cours, nous allons activer petit à petit toutes ces protections afin d’apprendre à les contourner.
Si vous n’avez pas encore trouvé la vulnérabilité présente dans ce programme, normalement gcc vous donne un indice lors de la compilation : main.c:(.text+0x39): avertissement : the 'gets' function is dangerous and should not be used..
Pourquoi tant nous faire peur ? On a pourtant utilisé correctement gets qui va lire le prénom et l’afficher, rien de plus. Exécutons notre programme :
1
2
3
./vuln
azerty
Bonjour azerty !
Bah voilà il y a rien de problématique en apparence. Essayons avec un nom assez long :
1
2
3
./vuln
Jean Louis David
Bonjour Jean Louis David !
Toujours pas de soucis. Essayons avec un nom plus long, mais genre vraiment plus long comme celui-ci.
1
2
3
4
./vuln
Uvuvwevwevwe Onyetenyevwe Ugwemuhwem Osas
Bonjour Uvuvwevwevwe Onyetenyevwe Ugwemuhwem Osas !
[1] 555062 segmentation fault ./vuln
Et là, c’est le drame ! On voit une erreur du type segmentation fault (aussi appelée SIGSEGV). Le souci avec ce type d’erreur en C est que l’on ne sait pas réellement quelle en est la cause.
SIGSEGV est un signal qui est envoyé à un programme généralement lorsqu’il accède à une adresse invalide ou à laquelle il n’a pas le droit d’accéder (lire, écrire, exécuter …). En exécutant man 7 signal, nous pouvons voir la liste des signaux dont celui qui nous intéresse : SIGSEGV P1990 Core Invalid memory reference.
Comme ce signal n’est pas géré explicitement par notre programme (avec sigaction par exemple), il applique l’action par défaut Core qui est, toujours selon le manuel de signal : Core Default action is to terminate the process and dump core (see core(5)).
Il est intéressant de noter qu’un core dump peut être généré. Il s’agit d’un fichier contenant des informations sur le processus qui a planté. D’ailleurs il est possible d’ouvrir ce core dump dans gdb pour voir où a eu lieu exactement le plantage.
Néanmoins, la génération de core dump n’est pas toujours activée par défaut. Vous pouvez l’activer avec la commande bash
ulimit -c unlimited. Relancez ensuite le programme en le faisant planter, désormais vous devriez avoir un fichiercore.XXXXXqui a été généré.Vous pouvez ensuite l’ouvrir dans gdb pour voir ce qui s’est passé avec la commande :
gdb ./vuln core.XXXXX.
Bon, c’est vrai que le nom renseigné est un peu trop long. Il fait 41 caractères alors que notre buffer prenom ne peut en contenir que 32. On a donc dépassé le nombre de caractères que peut contenir notre tableau de caractères, c’est bien ce que l’on appelle buffer overflow.
On remarque d’ailleurs que notre programme a tout de même affiché le prénom bien que celui-ci soit plus grand que notre buffer. Cela signifie qu’il a bien été copié dans prenom et que le crash n’a eu lieu qu’après avoir appelé printf.
Exploitation
🔎 Diagnostique du plantage
Nous savons comment faire planter notre programme vulnérable mais nous ne savons pas comment l’exploiter ni par où commencer. Voyons si nous ne pouvons pas avoir plus d’informations dans gdb car le message d’erreur segmentation fault n’est pas très explicite.
Ouvrons le programme dans gdb et lançons-le avec run. Utilisons cette entrée AAAAAAAABBBBBBBBCCCCCCCCDDDDDDDDEEEEEEEEFFFFFFFF :
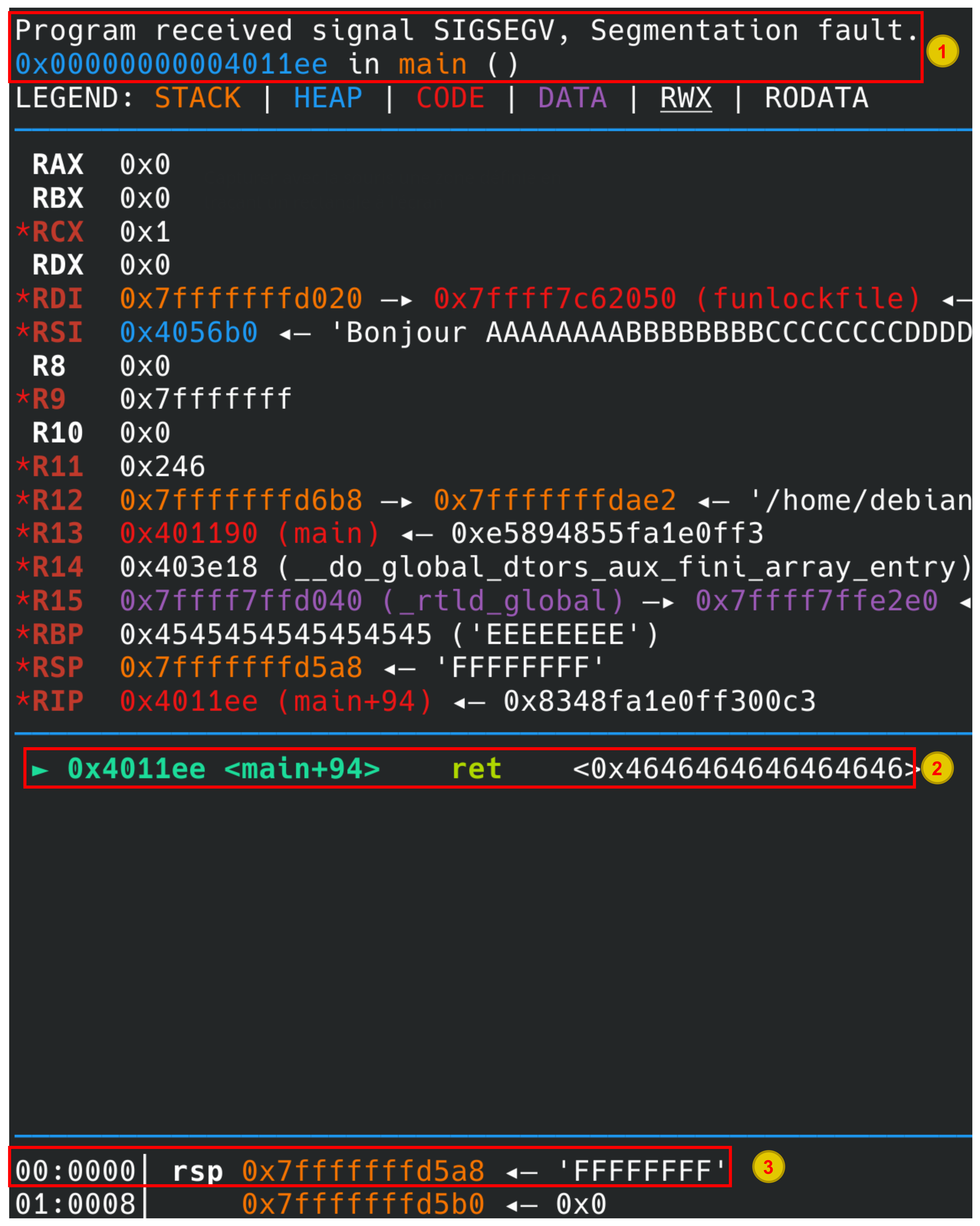
Mais que s’est-il donc passé ? A partir de ce que qu’affiche gdb nous devrions être en mesure de comprendre l’origine exacte du crash :
- Tout d’abord, gdb nous dit qu’il s’agit d’un plantage de type
SIGSEGV. De plus, nous savons maintenant lors de l’exécution de quelle instruction cela a eu lieu : dans lemainà l’adresse0x4011ee. - On voit également quelle est l’instruction à l’adresse
0x4011ee. Il s’agit de l’instructionret. - Enfin, on constate que l’élément en tête de la pile est
'FFFFFFFF'ce qui équivaut en hexadécimal à0x4646464646464646.
Comment le plantage a pu avoir lieu seulement au moment du
retalors que le buffer a été dépassé bien avant ?
Voici l’état de la pile avant que leave ; ret ne soit exécuté, avant et après l’appel à gets :
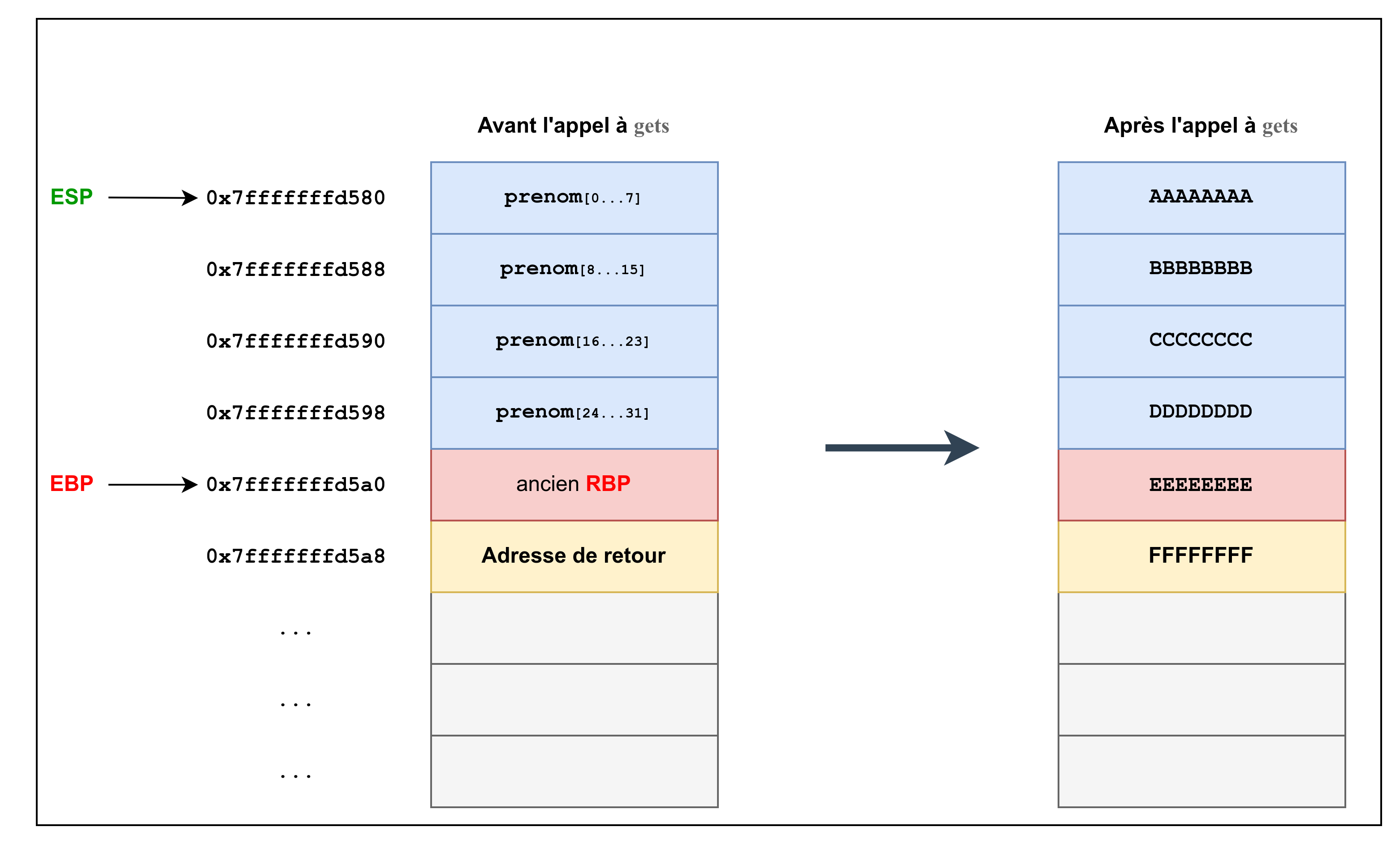
Ça vous rappelle des souvenirs 😏 ? Si vous vous penchez sur ce que fait l’épilogue leave ; ret, vous devriez comprendre exactement l’erreur affichée dans gdb.
Pour rappel, leave ; ret est strictement équivalent à faire :
1
2
3
4
mov rsp, rbp
pop rbp
pop rip
Je vous conseille de faire un schéma à la main pour décortiquer ces différentes instructions.
Dans gdb, voici ce que contient la pile :

Vous l’aurez compris, lorsque ret est exécutée, la valeur 0x4646464646464646 (représentation ASCII de "FFFFFFFF") est stockée dans rip car il la considère comme étant l’adresse de retour. Or, comme cette adresse n’appartient à aucune zone mémoire exécutable, cela génère un SIGSEGV.
On sait exactement dans notre string quels sont les caractères qui vont être stockés dans rip, maintenant, “y a plus qu’à”.
Nous n’avons pas choisi la string
AAAAAAAABBBBBBBBCCCCCCCCDDDDDDDDEEEEEEEEFFFFFFFFau hasard. En regroupant les caractères 8 par 8 dans un programme x64 ( ou 4 par 4 en x86), on peut savoir à partir de quel offset les caractères dans notre string vont nous permettre de contrôlerrip.
Le nerf de la guerre : contrôler rip
Maintenant que nous savons exactement quelle est l’influence de notre entrée utilisateur sur le programme, nous pouvons enfin contrôler rip. Pour y parvenir, nous allons adapter notre payload.
Le payload (ou charge utile 🇫🇷) est les données que nous allons envoyer afin d’exploiter la vulnérabilité comme bon nous semble.
Notre objectif étant d’exécuter la fonction goal, il nous faut d’abord savoir quelle est son adresse en mémoire. Il y a deux manières de le faire :
- en statique : avec la commande
objdump -d -Mintel vuln | grep goal; - en dynamique : avec la commande
p goaldans gdb. Comme la protection PIE n’est pas activée, l’adresse affichée dans gdb sera la même d’une exécution à une autre.
Dans mon cas, l’adresse de goal est 0x401176, il se peut que vous ayez une adresse différente si vous avez compilé le programme vous-mêmes. Cela ne posera pas de problème tant que vous adaptez les prochaines commandes et scripts avec vos adresses. Il va donc falloir envoyer l’adresse 0x401176 de telle sorte à ce que ce soit l’adresse de retour.
Plus précisément, il va falloir envoyer 0x0000000000401176 afin d’être sûrs que les octets de poids forts soient égaux à 0. En effet, si on envoie seulement 0x401176, gets ne va écraser que les 3 octets de poids faible de l’adresse de retour. Il se trouve que dans notre cas l’adresse de retour est dans la libc (__libc_start_call_main), par exemple : 0x7ffff7c29d90. Si on envoie que les 3 octets de poids faible le résultat (après appel à gets) : 0x7ffff7401176 et cela n’est pas l’adresse que l’on veut envoyer …
Comme l’adresse 0x0000000000401176 ne contient pas que des caractères ASCII, nous ne pouvons pas simplement saisir caractère par caractère avec le clavier notre payload. Nous verrons plus tard comment communiquer de manière efficace avec un processus, pour l’instant faisons cela à la main avec echo :
1
2
3
4
5
6
7
echo -ne 'AAAAAAAABBBBBBBBCCCCCCCCDDDDDDDDEEEEEEEE\x76\x11\x40\x00\x00\x00\x00\x00' | ./vuln
Bonjour AAAAAAAABBBBBBBBCCCCCCCCDDDDDDDDEEEEEEEEv@ !
Hop hop hop, comment êtes vous arrivés ici ?
[2] 563551 done echo -ne |
563552 segmentation fault (core dumped) ./vuln
On est bien arrivés dans la fonction goal ! Le programme a ensuite certes planté, mais on y est passés !
En fait, comme on est entrés dans goal sans passer par un appel conventionnel du type call goal, la stack frame à la sortie de goal ne permet pas de retourner dans une potentielle fonction appelante.
Y a un truc que je pige pas 🤔…
On a modifié
ripavec une valeur correcte mais lors de l’exécution de l’instructionleave, avant leret,rbpva avoir la valeur'EEEEEEEE'. Pourquoi cela n’a pas posé de problème alors querbppointe vers0x4545454545454545et que cela n’est pas une adresse valable ?
Très bonne remarque ! Effectivement rbp ne pointe pas vers une adresse valide mais comme nous rentrons dans les premières instructions de goal, nous exécutons le prologue push rbp; mov rbp, rsp. On a donc :
- avant d’entrer dans
goal:rsp=0x7fffffffd5b0rbp=0x4545454545454545
- dans
goal:rsp=0x7fffffffd5b0rbp=0x7fffffffd5b0
- à la sortie de
goal(avantret):rsp=0x7fffffffd5b0rbp=0x4545454545454545
Ainsi, lorsque l’on entre dans une fonction en exécutant son prologue, nous n’avons pas besoin d’avoir une valeur valide pour rbp. Avoir une adresse valide dans rbp est nécessaire dans le cas où rbp est utilisé tel quel dans le bout de code ou fonction exécutée.
📝 Exercice
Pour ceux qui veulent pratiquer encore un peu et pour ceux qui ne se sont contentés que de lire ce cours sans pratiquer de leur côté (je vous vois 🧐), ci-dessous un petit exercice assez facile : il s’agit du même programme sauf que la taille du tableau a été réduite à 13 octets.
Accès au conteneur Docker :
- 🎯 Objectif : appeler
goalen contrôlantrip - ⬇️ Téléchargement : pwn-stack-vuln-2.zip
- 🔎 SHA256 & Analyse Virus Total : ecca998d4ef495249ec80ca10363ff5688b90179dbe9ef09efe60f6fe30a3d51
- ⚙️ Construction et lancement du conteneur :
1
2
3
docker build -t pwn-stack-vuln-2 .
docker run -it --rm --cap-add=SYS_PTRACE --security-opt seccomp=unconfined pwn-stack-vuln-2
Vous devrez, évidemment, adapter le payload en conséquence.
📋 Synthèse
Pour conclure, retenons les points essentiels abordés dans ce chapitre :
- Une vulnérabilité de type stack buffer overflow permet d’écraser l’adresse de retour stockée sur la pile et donc de contrôler
rip; - un plantage (signal
SIGSEGVpar exemple) est souvent un indicateur, mais comprendre où et pourquoi il survient est essentiel pour exploiter correctement la vulnérabilité ; - l’exploitation peut entraîner des effets de bord (par exemple une valeur invalide de
rbp) qui ne sont pas toujours bloquants ; - dans la pratique, un payload contient rarement uniquement des caractères ASCII, ce qui nécessite des méthodes adaptées pour l’injecter.