Partie 2 - Fonctionnalités de base
Autres fonctionnalités de base
Le chapitre précédent a abordé les bases de l’exécution symbolique ainsi que les principaux composants qu’angr utilise afin de faire de l’exécution symbolique dans un programme.
Si vous avez réussi le challenge donné en exercice, vous devriez avoir compris les principaux principes de l’exécution symbolique. Toutefois, nous n’avons vu que les composants élémentaires d’angr.
L’objectif de ce chapitre n’est pas de devenir un pro d’angr mais de connaître les principales fonctionnalités que l’on peut être amené à rencontrer ou à utiliser dans un programme.
IPython
Avant d’aller plus loin dans les fonctionnalités d’angr, je tenais à vous partager ce module extrêmement utile lorsque l’on utilise angr ou, de manière général, lorsque l’on code en Python.
J’ai justement découvert ce module Python en apprenant à utiliser angr et depuis, je l’utilise quasiment systématiquement dans mes programmes Python. Je dirais que c’est même le premier module que j’importe quand je commence à écrire du code Python.
Mais à quoi sert IPython ?
IPython est un module qui vous permet, entre autres, d’avoir accès à un shell interactif alors que le script Python est en cours d’exécution. Il permet également d’avoir un shell Python “amélioré”, de la même manière que zsh apporte plus d’ergonomie à bash.
Utilisation en ligne de commandes
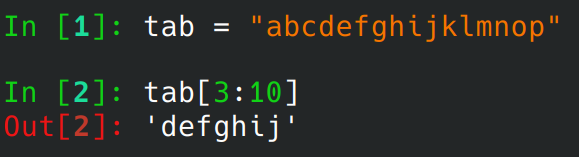
Il suffit de lancer ipython (ou ipython3) dans un terminal pour y avoir accès. A partir de là on peut exécuter du code Python. Pratique lorsque l’on se rappelle plus si tab[3:10] inclut la troisième valeur ou non sans passer par internet ou ouvrir un IDE.
Je dirais que les fonctionnalités les plus intéressantes de IPython par rapport au shell Python classique est le fait de pouvoir afficher les membres et attributs d’un objet simplement avec TAB et de pouvoir avoir un historique “à la zsh” des commandes saisies.
Cela est très pratique lorsque l’on a la flemme de lire la doc et que ce que l’on cherche a un nom bien explicite : 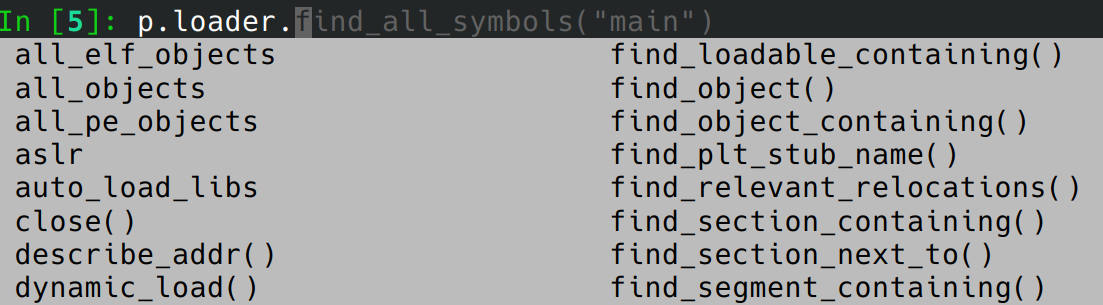
Utilisation dans un script
Pour utiliser IPython directement dans un script Python il suffit de :
- importer le module via
import IPython - ouvrir un shell interactif via la
IPython.embed()
Reprenons le script final du précédent chapitre. Nous allons le modifier pour y utiliser IPython.
Premièrement, importez le module puis ajouter la ligne suivante dans le script du précédent chapitre :
1
2
3
4
5
6
7
8
else :
print("[+] Détermination de l'input valide")
# Ajoutez la ligne suivante :
IPython.embed()
# Récupération de l'état qui est arrivé dans le bon bloc
found = sm.found[0]
res = found.solver.eval(arg_symb)
print("[+] Le bon input est : ",hex(res))
Exécutez le script et vous verrez qu’un shell IPython s’est ouvert. Il est possible d’y exécuter des commandes Python, voir la valeur de certaines variables, modifier ou créer de nouvelles variables :
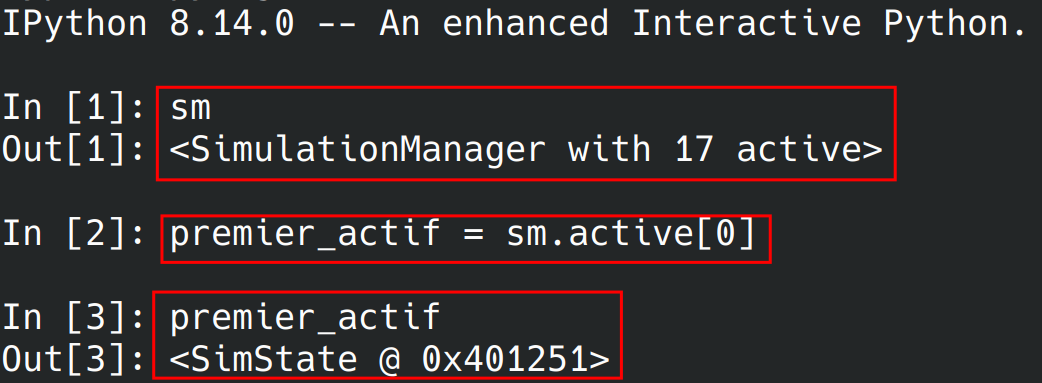 C’est tellement pratique pour jeter un œil aux différents états, voir la valeur de certains registres etc. sans avoir à insérer des
C’est tellement pratique pour jeter un œil aux différents états, voir la valeur de certains registres etc. sans avoir à insérer des print et des boucle for dans tous les sens.
La question à 1 million
Une question que tout le monde se pose quand il utilise angr : Comment voir où mon script angr est bloqué ?
En fait, il s’agit d’un problème récurrent car à cause d’une mauvaise configuration, à cause de l’explosion de chemins ou autre, il arrive qu’un script angr tourne en rond et consomme excessivement de la mémoire sans terminer.
On aimerait bien voir et comprendre pourquoi le programme ne fonctionne pas correctement. Mais à gros coups de print on n’a pas toujours les détails que l’on cherche.
La solution, vous vous en doutez … pouvoir ouvrir un terminal IPython de manière arbitraire !
Effectivement c’est possible, il suffit juste d’ajouter ce bout de code, par exemple après la liste des imports :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import angr
import IPython
import os
import signal
def kill():
current_pid = os.getpid()
os.kill(current_pid, signal.SIGTERM)
def sigint_handler(signum, frame):
print('Pour tuer le processus, saisir : kill()')
IPython.embed()
signal.signal(signal.SIGINT, sigint_handler)
En mettant ce bout de code au début de votre script, lorsque vous exécuterez votre script et que vous enfoncerez Ctrl+C, un terminal IPython s’ouvrira.
Et comme on l’a vu un peu plus haut, cela permet de voir la liste des états actifs, finis, les analyser, savoir à quelle adresse dans le programme, l’état est situé …
Etant donné qu’habituellement Ctrl+C est utilisé pour tuer un processus et que l’on intercepte le signal en question, ce raccourcis ne permettra plus de tuer le processus. C’est pourquoi il faudra saisir kill() dans IPython pour terminer le programme Python.
A utiliser sans modération 😇!
La lecture et écriture en mémoire 📝
Si vous avez en tête le précédent chapitre, vous devriez vous rappeler de la manière dont on a pu accéder aux registres. Par exemple, pour accéder au registre rax, nous pouvons utiliser state.regs.rax.
De manière analogue il est possible d’accéder à n’importe quel autre registre, que ce soit en 32 bits ou 64 bits, ARM, x86 ou MIPS.
Nous avons pas encore vu comment accéder aux zones mémoire en lecture et écriture. Après tout, angr simule une exécution, il devrait bien y avoir un moyen d’accéder à la mémoire ?
Voici comment cela se fait :
- 📄 Lecture en mémoire :
state.memory.load(adresse, taille)où :adresseest un entier qui représente l’adresse à partir de laquelle angr va liretailleest un entier qui représente la taille des données en octets que l’on souhaite lire- Retour : le retour de la fonction est un BitVector, symbolique ou non ( par exemple, si la zone mémoire contient les 4 octets
0xdeadbeef, le résultat retourné sera :<BV32 0xdeadbeef>)
- ✏️ Ecriture en mémoire :
state.memory.store(adresse,données)où :adresseest un entier qui représente l’adresse à partir de laquelle angr va liredonnéespeut être de typebytes,BVV(données concrètes) ouBVS(données symboliques)
C’est aussi simple que cela ! Enfin presque !
Tout d’abord, concernant la lecture et écriture en mémoire, il faut savoir que cela se fait par défaut en big endian. Cela peut être gênant car le boutisme que l’on rencontre le plus souvent est le little endian. Toutefois, il est possible de spécifier le paramètre endness=archinfo.Endness.LE afin que l’opération de lecture ou écriture se fasse en little endian.
Par exemple, lire 8 octets sur la stack :
1
data = s.memory.load(s.regs.rsp,8, endness=archinfo.Endness.LE)
C’est assez lourd dans le sens où il faut à chaque fois le préciser lorsque l’on veut lire ou écrire en mémoire. Je n’ai, actuellement, pas trouvé d’autres alternatives. Si vous en trouvez une, faites moi signe ;) !
La version pour écrire des données en mémoire en little endian :
1
state.memory.store(s.regs.rsp,b'data',endness=archinfo.Endness.LE)
Contrairement à la taille spécifiée dans les BVV et BVS claripy, le paramètre “taille” pour la lecture en mémoire est en octets !
En effet, les BVV et BVS utilisent une taille en bits. Il faut donc redoubler de vigilence car la confusion entre bits / octets est fréquente !
Mais pourquoi aurions-nous besoin de lire/écrire en mémoire alors que l’on a pas eu besoin de le faire jusqu’à présent ?
Dans des programmes plus compliqués que de simples crackmes triviaux, il faut généralement mettre la main dans le cambouis afin qu’angr puisse s’exécuter correctement.
Un exemple basique est tout simplement la gestion des programmes 32 bits x86 dont la convention d’appel est basée sur l’utilisation de la pile. De cette manière, si vous souhaitez gérer les arguments lors de l’appel d’une fonction, il faut savoir écrire des données en mémoire (plus précisément dans la stack).
Egalement, comme les données que l’on écrit en mémoire ne doivent pas nécessairement être concrètes, il est possible d’utiliser des variables symboliques en mémoire. Pratique lorsque l’input est stocké et/ou récupéré en mémoire.
Exercice
Maintenant que vous savez comment lire et écrire en mémoire, je vous conseille d’écrire une petite fonction read_from_stack(state,n) qui affiche les n première valeurs ( de 64 bits par ex) sur la stack de l’état state.
Ça vous sera utile quand vous souhaiterez déboguer un programme avec angr.
Gérer l’input ⤵️ et l’output ⤴️
Parfois, il peut être plus simple d’utiliser directement l’entrée (input) et sortie (output) standards au lieu de hooker certaines fonctions et complexifier le script de résolution.
Par exemple, dans l’exercice du précédent chapitre, on sait que si l’output est Win ! alors c’est que l’entrée est valide.
Lecture de l’output ⤴️
La lecture de l’output depuis un état se fait de la sorte :
1
output = state.posix.dumps(sys.stdout.fileno())
Evidemment, n’oubliez pas d’importer le module sys pour que cela fonctionne correctement. Les données retournées par cette fonction sont des bytes. Par exemple, sur le précédent exercice, si l’entrée est correcte, la valeur contenue dans la variable output serait b"Win !\n".
Mais comment pouvons-nous avoir des données affichées dans la sortie standard alors que dans le précédent exercice, nous avons hook les fonctions du type
puts,printf…
Justement ! En utilisant directement l’output, vous n’aurez plus besoin de hooker les fonctions qui affichent des données dans la sortie standard telles que puts et printf.
En fait, pour ce genre de fonctions basiques, angr arrive à les hooker proprement tout seul sans modifier leur fonctionnement “global”. Ainsi, comme ces fonctions de base sont censées afficher des données dans la sortie standard, angr écrit bien ces données dans la sortie standard que l’on peut récupérer via state.posix.dumps(...). C’est pour cela que l’on ne les voit pas directement dans le terminal.
Ce qui est pas mal une fois que l’on sait gérer la sortie standard est que l’on peut l’utiliser pour établir une condition de “réussite” lors de la recherche de chemin.
Par exemple, en utilisant une fonction is_output_good, il est possible de spécifier directement une condition sur l’output afin de avoir si on a bien trouvé la destination recherchée ou non. De la même manière il est possible d’utiliser l’output pour spécifier une condition que l’on souhaite éviter (avoid) :
1
2
3
4
5
6
7
8
9
10
11
12
def is_output_good(state):
# Est-ce que "Win !" est présent dans l'output ?
output = state.posix.dumps(sys.stdout.fileno())
return b'Win !' in output
def is_output_bad(state):
# Est-ce que "Loose !" est présent dans l'output ?
output = state.posix.dumps(sys.stdout.fileno())
return b'Loose !' in output
# (...)
sm.explore( find = is_output_good, avoid = is_output_bad)
L’utilisation de l’output n’est pas toujours la meilleure solution. En fait, tout dépend du contexte. Il n’y a pas toujours une seule bonne méthode pour arriver à destination. Cependant, cela peut être utile dans un programme obfusqué où vous ne savez pas trop à quelle adresse vous devez aller mais où vous voyez dans les chaînes de caractères du programme une string intéressante.
Dans un tel cas cela peut être intéressant d’utiliser l’output car vous savez ce que le programme devrait afficher. Mais généralement, il vaut mieux savoir exactement où on doit aller et comment on doit le faire. La méthode des strings est généralement efficace dans des programmes simples et basiques mais demande plus de réflexion le cas échéant.
Utilisation de l’input ⤵️
Assez parlé de l’output, passons à l’input (ou entrée standard) !
Généralement voici les différentes manières dont un programme en ligne de commande peut récupérer une entrée (par exemple mot de passe à checker) saisi par l’utilisateur :
- En demandant directement à l’utilisateur de saisir le mot de passe via
stdin(cela est généralement fait avecread,scanfetc.) - En lisant dans un fichier ( dont le nom est généralement codé en dur)
- Dans les arguments du programme lancé avec
argv
Utilisation de stdin
De la même manière dont on a pu gérer le cas de argv avec un hook, il est possible de le faire avec l’input en réalisant un hook de la fonction qui lit l’input : read,scanf,gets etc. C’est sans doute ce que vous avez fait lorsque du précédent exercice ?
Néanmoins cela implique :
- de savoir quelle fonction lit l’input et à quel endroit dans le code
- de devoir programmer des fonctions de hook
Cela peut se faire en un temps raisonnable mais il y a bien plus rapide ! Surtout si le programme est en x86 (32 bits donc), il faut savoir à quelle adresse écrire le buffer symbolique … compliquée cette histoire !
Il suffit tout simplement d’utiliser l’argument stdin lors de la création du projet angr.
Par exemple, pour créer un input contenant 12 octets symboliques, on peut faire :
1
2
mdp = claripy.BVS('mdp', 12*8)
first_state = p.factory.blank_state(addr= 0xdeadbeef,stdin=mdp)
Voilà !
Il faut savoir que si le programme n’est censé lire que 12 octets, le précédent bout de code fonctionnera très bien. Par contre, si le programme est censé lire 12 octets, puis n autres, il faut faire différemment car ce code contraint l’input à exactement 12 octets.
Lorsque l’on ne souhaite fournir que les premiers octets de l’input et gérer les n autre octets plus tard, il faut utiliser un SimFileStream.
Le nom peut paraître un peu compliqué mais il est relativement simple de l’utiliser :
1
2
3
mdp = claripy.BVS('mdp', 12*8)
first_state = p.factory.blank_state(addr= 0xdeadbeef, stdin=angr.SimFileStream(name='stdin', content=mdp, has_end=False))
Souvent, le mot de passe demandé est constitué uniquement de caractères ASCII. Ainsi, ce serait pas mal de pouvoir contraindre notre input à ne contenir que des caractères ASCII afin de réduire de temps d’exécution du script avec angr.
Cela peut se faire, par exemple, comme cela :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import angr
import claripy
p = angr.Project("...")
state = p.factory.entry_state()
flag = [claripy.BVS('flag_%d' % i, 8) for i in range(12)]
# Ajout de contraintes au solveur
# afin que le flag soit obligatoirement
# de l'ASCII
for elt in flag:
state.solver.add(elt >= ord(' '))
state.solver.add(elt <= ord('~'))
Ici, on a déclaré flag en tant que tableau de BVS car un seul et même BVS de plusieurs octets n’est pas itérable directement. Mais il existe une méthode pour tout de même utiliser un seul et même BVS pour se simplifier la tâche et ne pas avoir à passer par un tableau chelou :
1
2
3
4
5
6
flag = claripy.BVS('flag', 8*12)
# 1 ocet = 8 bits, d'où le paramètre
for elt in flag.chop(8):
state.solver.add(elt >= ord(' '))
state.solver.add(elt <= ord('~'))
Exercice
Vous pouvez tester la gestion de stdin en compilant un programme basique en C qui lit, par exemple, 8 octets et vérifie qu’il s’agit du bon mot de passe.
Utilisez ensuite angr afin de trouver le mot de passe automatiquement sans avoir à hook les fonctions qui lisent depuis stdin.
Si vous êtes à court d’idées, vous pouvez réutiliser le code C de l’exercice du précédent chapitre car l’input y était lue avec
read. Mais cette fois-ci, va falloir le résoudre sans hookerread!
Utilisation de argv
Nous avons déjà rencontré argv précédemment et si vous vous souvenez bien, nous avions utilisé un hook de la fonction atoi afin de retourner directement un buffer symbolique.
Mais il y a une méthode plus simple pour utiliser un buffer symbolique dans argv.
Par exemple, si argv doit contenir deux mots de passe de 12 octets, on peut déclarer deux mots de passe symboliques dans argv de la sorte :
1
2
3
4
mdp_1 = claripy.BVS('mdp_1', 12*8)
mdp_2 = claripy.BVS('mdp_2', 12*8)
state = proj.factory.entry_state(args=['./nom_du_programme', mdp_1,mdp_2])
Cela revient à lancer le programme de la sorte : ./programme mdp_1 mdp_2.
Finalement, c’est plus ou moins la même méthode que pour spécifier l’input : on utilise directement les arguments disponibles lors de la création de l’état initial.
Ici la taille est de 12 octets pour chacun des mots de passe. Evidemment, libre à vous de choisir une taille adaptée au programme analysé. Aussi, on a utilisé des buffers symboliques pour stdin et argv mais il est tout à fait possible d’utiliser un buffer “concret”. Par exemple : b'mon_mot_de_passe'.
Dans ce bout de code, le tableau
argvest représenté par le tableauargs. Il ne faut donc pas oublier que le premier argument d’un programme est … le “nom” (ou chemin vers) du programme !
Mais pourquoi utilise-t-on
entry_stateau lieu deblank_stateici ? Quelle est la différence entre les deux ?
En fait, un blank_state est un état assez basique qui contient un nombre limité d’arguments. L’entry_state est un état initial un peu plus “complet” et peut être initialisé avec plus de paramètres, dont args (qui représente argv). C’est pourquoi on l’utilise ici.
Si vous voulez en savoir plus sur les différents types d’états, voici un peu de lecture (en anglais).
Utilisation des fichiers avec les SimFile
On a vu comment gérer les deux principales méthodes permettant de récupérer l’input auprès de l’utilisateur à savoir : stdin et argv. Une autre possibilité est, comme cité précédemment, via la lecture de fichier.
Ce n’est pas forcément la méthode la plus commune dans les challenges / crackmes etc., mais elle peut être pas mal pour de la recherche de vulnérabilités afin de déclencher un bug ou fuzzer de manière symbolique des fonctions qui traitent des données issues d’une lecture de fichier.
Pour simuler un fichier il est possible d’utiliser des SimFiles. L’utilisation des SimFiles est généralement réalisée de cette manière :
- Création des données du fichier
- Création du
SimFile - Attribution du
SimFileau filesystem de l’état (initial)
Pour ce qui est de la création des données, vous vous en doutez sûrement mais on peut choisir de mettre des données concrètes, données symboliques … ou les deux !
Voici un exemple où le contenu contient des données à la fois symboliques et concrètes :
1
2
3
4
data_symb = claripy.BVS('donnees_symboliques', 4 * 8)
data_conc = b"donnees_concretes"
simfile = angr.storage.SimFile("mon_fichier.bin", content=data_symb.concat(data_conc))
Et voilà ! On vient de faire notre premier SimFile. Mais ce n’est pas fini. En effet, un SimFile doit être lié à un état afin de pouvoir être utilisé. Sinon, vous risquez de vous prendre des NoneType exceptions en essayant de lire ou écrire dedans.
Pour attacher un SimFile à un état, on peut faire ça de deux manières :
- Directement lors de l’initialisation du
state:1
state = proj.factory.entry_state(fs={ "mon_fichier.bin" : simfile})
- En ajoutant “à la main” le fichier dans le filesystem d’un état existant :
1
state.fs.insert("mon_fichier.bin", simfile)
Ainsi, lorsque le programme ouvrira et lira le fichier mon_fichier.bin, angr se chargera d’utiliser le SimFile que nous venons de créer.
De cette manière, pas besoin de hook les fonctions du type fopen, fread etc. si le nom du fichier du SimFile correspond bien au nom du fichier ouvert par le programme.
Pratique !
Autres types de fichiers et flux
Il existe d’autres manières de gérer les fichiers ou flux avec :
SimPacketsqui permet de gérer les flux de données (ex : flux réseau …) envoyé en tant que chunks de données asynchrones. UnSimPacketne peut pas être utilisé à la fois pour la lecture et l’écriture.SimFileStream: Il s’agit d’un type proche desSimFilemais qui s’utilise comme un flux. Il n’y aura donc pas les mêmes fonctionnalités de gestion de la position du curseur ( qui n’a pas réellement de sens dans un flux)
Ce sont des objets assez avancés que l’on ne traitera pas ici. Si vous souhaitez en savoir davantage, je vous invite à la lire la doc !
Exercice
Le programme suivant lit depuis un fichier des données afin de les valider ou non. A vous de trouver le contenu adéquat grâce à angr !
Cet exercice vous permettra de comprendre le fonctionnement global des SimFiles.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
#include <stdint.h>
int main() {
FILE *file = fopen("mdp.bin", "rb");
if (file == NULL) {
perror("Erreur lors de l'ouverture du fichier");
return 1;
}
uint64_t win_value = 0xdeadbeefcafebabe;
uint64_t read_value;
// Lecture de 8 octets depuis le fichier
size_t bytes_read = fread(&read_value, 8, 1, file);
if (bytes_read != 1) {
perror("Erreur lors de la lecture du fichier");
fclose(file);
return 1;
}
// Fermeture du fichier
fclose(file);
if (read_value == win_value) {
printf("Win\n");
} else {
printf("Loose\n");
}
return 0;
}
Pour le compiler : gcc -no-pie main.c -o exe.
Indice : aucun hook n’est nécessaire pour la réussite de cet exercice 😉 !