Partie 20 - Les large bins - fonctionnement et cas d’usage (1/2)
Les large bins : fonctionnement et cas d’usage (1/2)
Passons enfin au dernier type de corbeilles : les large bins !
Que ce soit pour les
small binsoularge bins, nous n’entrerons pas en détails dans la manière de les exploiter, cela ferait beaucoup pour un cours d’introduction, sachant qu’elles ne sont pas les corbeilles les plus utilisées dans le tas.
Utilisation
Nous en avons déjà parlé, les large bins sont utilisées afin de récupérer les blocs de grande taille non utilisés provenant de la unsorted bin. Ainsi, leur fonctionnement général demeure semblable à celui des small bins : recycler les blocs issus de la unsorted bin.
Là où il va y avoir du changement, c’est au niveau de l’organisation des blocs au sein d’une corbeille de type large bin. Eh oui, nous allons enfin voir et comprendre à quoi servent les champs fd_nextsize et bk_nextsize des métadonnées d’un bloc :
1
2
3
4
5
6
7
8
9
10
11
12
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
Gestion des blocs libres
Taille des blocs gérés
Lors du précédent chapitre, nous avons vu que les 127 corbeilles présentes dans le tableau bins de l’arène sont réparties comme suit :
- 1
unsorted bin; - 62
small bins; - 64
large bins;
À partir des tailles maximales gérées par les small bins, on en déduit celles prises en charge par les large bins :
Version de la libc <= 2.25
| Version | Nombre de large bins | Taille min (incluse) |
|---|---|---|
| 32 bits | 64 | 0x200 |
| 64 bits | 64 | 0x400 |
Version de la libc > 2.25
| Version | Nombre de large bins | Taille min (incluse) |
|---|---|---|
| 32 bits | 64 | 0x3f0 |
| 64 bits | 64 | 0x400 |
Nous avons volontairement omis d’indiquer les tailles maximales des
large binscar cela ne vous sera probablement d’aucune utilité 😄.
Organisation des corbeilles
Espacement entre les corbeilles
La principale différence entre les small bins et large bins est que les corbeilles des small bins peuvent gérer, chacune, seulement une taille de bloc en particulier, par exemple : 0x80, 0x100, 0x180 …
Tandis que les corbeilles des large bins peuvent gérer un intervalle de tailles de blocs. Par exemple : [0x400 ; 0x440[, [0x440 ; 0x480[, [0xe00 ; 0x1000[ …
Euh j’vois pas trop où tu veux en venir avec cette histoire d’intervalles 🤨 ?
Bon, une image vaut mille mots 😉 :
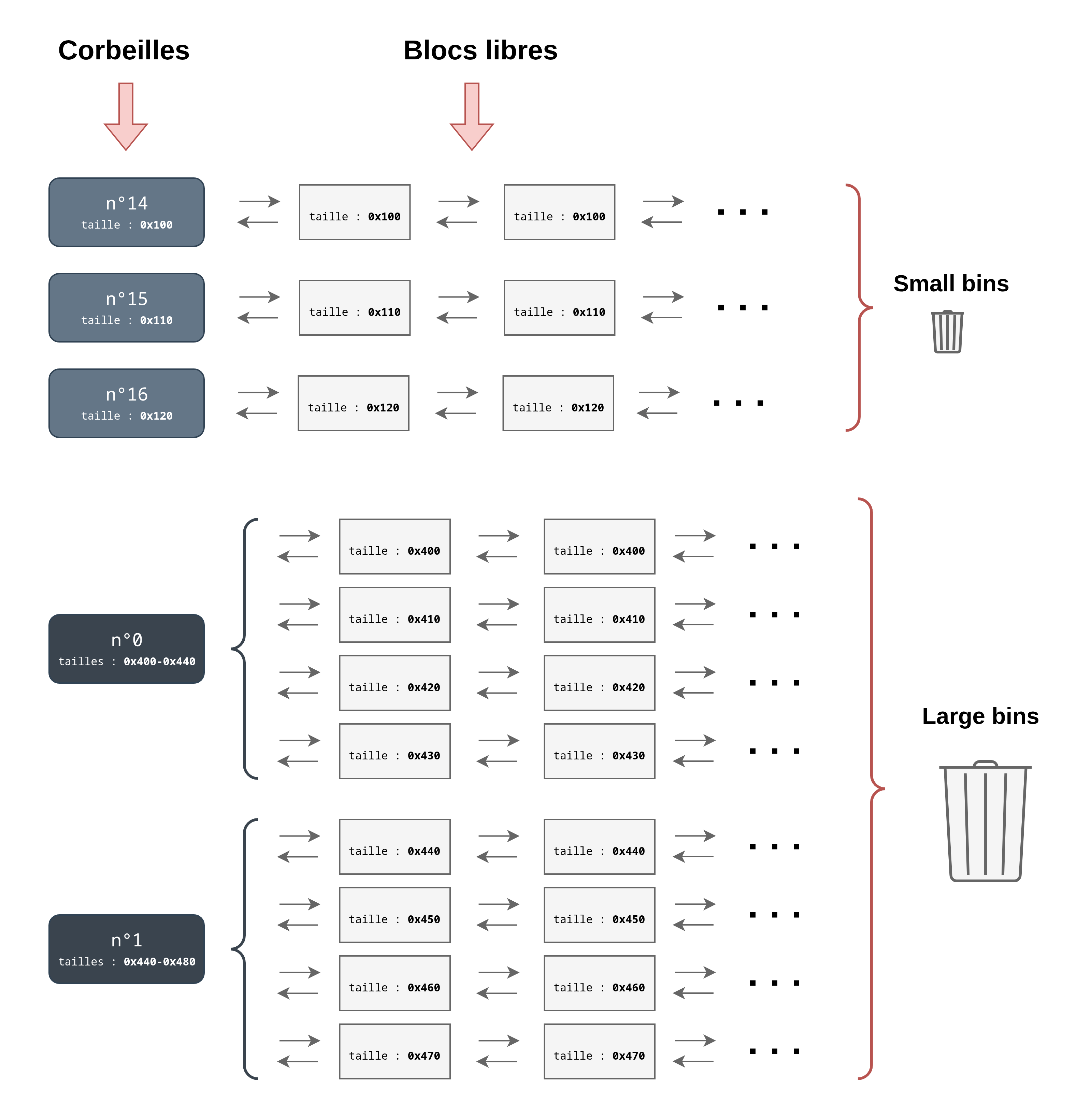
Les différents liens visibles sur le précédent schéma ne reflètent pas exactement l’organisation sous forme de listes doublement chaînées des
small binsetlarge bins. Cela permet d’alléger le schéma et de pouvoir se focaliser sur les tailles de blocs dans chaque corbeille.
Vous remarquerez que l’intervalle de tailles d’une large bin n’inclut jamais la dernière valeur. Par exemple pour la première large bin qui gère les tailles [0x400 ; 0x440[, la taille 0x440 n’est pas incluse.
De plus, la taille de l’intervalle d’une corbeille de type large bin n’est pas toujours de 0x40 octets. En effet, d’après la documentation les intervalles sont de plus en plus grands au fur et à mesure que l’on avance dans les indices des large bins :
1
2
3
4
5
6
7
8
9
10
11
/*
Larger bins are approximately logarithmically spaced:
64 bins of size 8 <- ce sont les small bins
32 bins of size 64
16 bins of size 512
8 bins of size 4096
4 bins of size 32768
2 bins of size 262144
1 bin of size what's left
*/
Les 64 premières sont les small bins (même s’il y en a en réalité 62) tandis que les autres sont les large bins.
Voici quelques exemples d’intervalles de tailles, chacun étant géré par une seule corbeille :
- 32 corbeilles de type
large binqui traitent des intervalles des tailles espacées de 64 octets (0x40) :[0x400 ; 0x440[;[0x440 ; 0x480[;- …
[0xc00 ; 0xc40[.
- puis 16 corbeilles espacés de 512 octets (
0x200) :[0xc40 ; 0xe00[(l’intervalle n’est pas espacé de0x200octets, je ne sais pas pourquoi 😅)[0xe00 ; 0x1000[[0x1000 ; 0x1200[- …
et ainsi de suite.
Puisque le pas entre deux tailles de blocs est de 0x10 (en 64 bits) chaque corbeille traite autant de tailles de blocs que son intervalle de tailles lui permet.
Par exemple :
large binn°0 ➡️[0x400 ; 0x440[4 tailles de blocs gérées :0x4000x4100x4200x430
large binn°33 ➡️[0xe00 ; 0x1000[32 tailles de blocs gérées :0xe000xe10- …
0xfe00xff0
En somme, une large bin gère un intervalle de tailles de blocs, ce qui signifie qu’une même corbeille peut gérer 4 tailles, 32 tailles ou davantage en fonction de son index.
fd_nextsize et bk_nextsize
Afin de s’y retrouver dans l’intervalle de tailles, chaque bloc des large bins comporte deux champs dédiés, à savoir : fd_nextsize et bk_nextsize. Vous vous demandez sans doute ce à quoi servent ces champs.
Pour comprendre, analysons de plus près la problématique suivante : nous avons précédemment vu qu’une large bin peut gérer plusieurs tailles de blocs. Si nous prenons la première large bin, celle-ci gère les tailles 0x400, 0x410, 0x420 et 0x430.
Désormais, imaginons le scénario suivant :
- la première
large bincontient déjà :- 1000 blocs de taille
0x400; - 1000 blocs de taille
0x410; - 1000 blocs de taille
0x430.
- 1000 blocs de taille
- nous souhaitons insérer dans cette
large binun bloc de taille0x420.
Une méthode naïve serait de parcourir la liste des blocs et de comparer la taille du bloc courant avec 0x420. Le souci, c’est qu’il va falloir parcourir au moins 1000 blocs avant de trouver une place pour le bloc de taille 0x420 et ce, que la liste soit parcourue en partant des plus petits blocs (0x400) ou des plus grands (0x430).
Comme vous pouvez le constater, ce n’est pas très optimisé, surtout lorsque la large bin contient beaucoup de blocs. C’est là que fd_nextsize et bk_nextsize interviennent : ces deux champs vont permettre de savoir quand est-ce que l’on passe d’une taille à une autre sans avoir à parcourir tous les blocs.
Mais pourquoi l’arène ne stocke pas les informations liées à la taille des blocs au sein d’une
large bin?
Tout simplement parce que, comme pour la unsorted bin et la small bin, les large bins ne sont accessibles que via le tableau bins de l’arène qui ne contient, pour chaque corbeille, qu’un champ fd et bk. Les large bins n’échappent pas à cette règle.
Ok mais ça marche comment concrètement ?
Tout d’abord, il est important de savoir que tous les blocs libres d’une large bin ne contiennent pas les champs fd_nextsize et bk_nextsize. En effet, seul le bloc libre qui démarre une nouvelle taille contient ces métadonnées. Tous les autres blocs de la même taille, eux, ne contiendront pas fd_nextsize et bk_nextsize.
En d’autres termes, pour chaque taille qu’une large bin peut gérer, un bloc “tête de liste” sera désigné (toujours le premier bloc inséré de cette taille) et aura les champs fd_nextsize et bk_nextsize tandis que tous les autres blocs de la même taille n’auront pas ce privilège 🙃.
⤵️ Insertion de 4 blocs de tailles différentes
Intéressons-nous, à présent, à la manière dont sont liés les blocs au sein d’une large bin. Bien que les liens reposent sur un système de liste doublement chaînées, vous constaterez que cela ne se fait pas de la même manière qu’avec une small bin ou la unsorted bin.
Pour cela, je vous propose de partir du programme suivant et le lui faire subir quelques modifications :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#include "stdlib.h"
#define NB_BINS 4
void *allocs[NB_BINS];
unsigned int global_idx = 0;
void insert_into_large_bin(int size)
{
free(allocs[global_idx]);
malloc(0x5000 - (size));
malloc(0x2000); malloc(0x2000);
global_idx++;
}
void init()
{
// Allocations permettant d'eviter les potentielles
// consolidations
for(int i = 0; i < NB_BINS; i++)
{
allocs[i] = malloc(0x5000);
malloc(1);
}
}
int main()
{
init();
insert_into_large_bin(0x400);
insert_into_large_bin(0x410);
insert_into_large_bin(0x420);
insert_into_large_bin(0x430);
return 0;
}
C’est pas sorcier 🧙♂️ : 4 blocs de tailles différentes sont alloués. Ils seront traités par la première large bin. Par souci de clarté, deux schémas seront utilisés pour comprendre le fonctionnement des deux liste doublement chaînées :
- la première : celle qui est basée sur
fdetbkdont le fonctionnement est semblable à celui dessmall bins; - la seconde : basée sur
fd_nextsizeetbk_nextsizequi diffère quelque peu de la première.
Les schémas suivants seront disposés d’une autre manière, par rapport à ce qui a été fait jusque-là, afin de mieux visualiser l’organisation des blocs dans une
large bin.
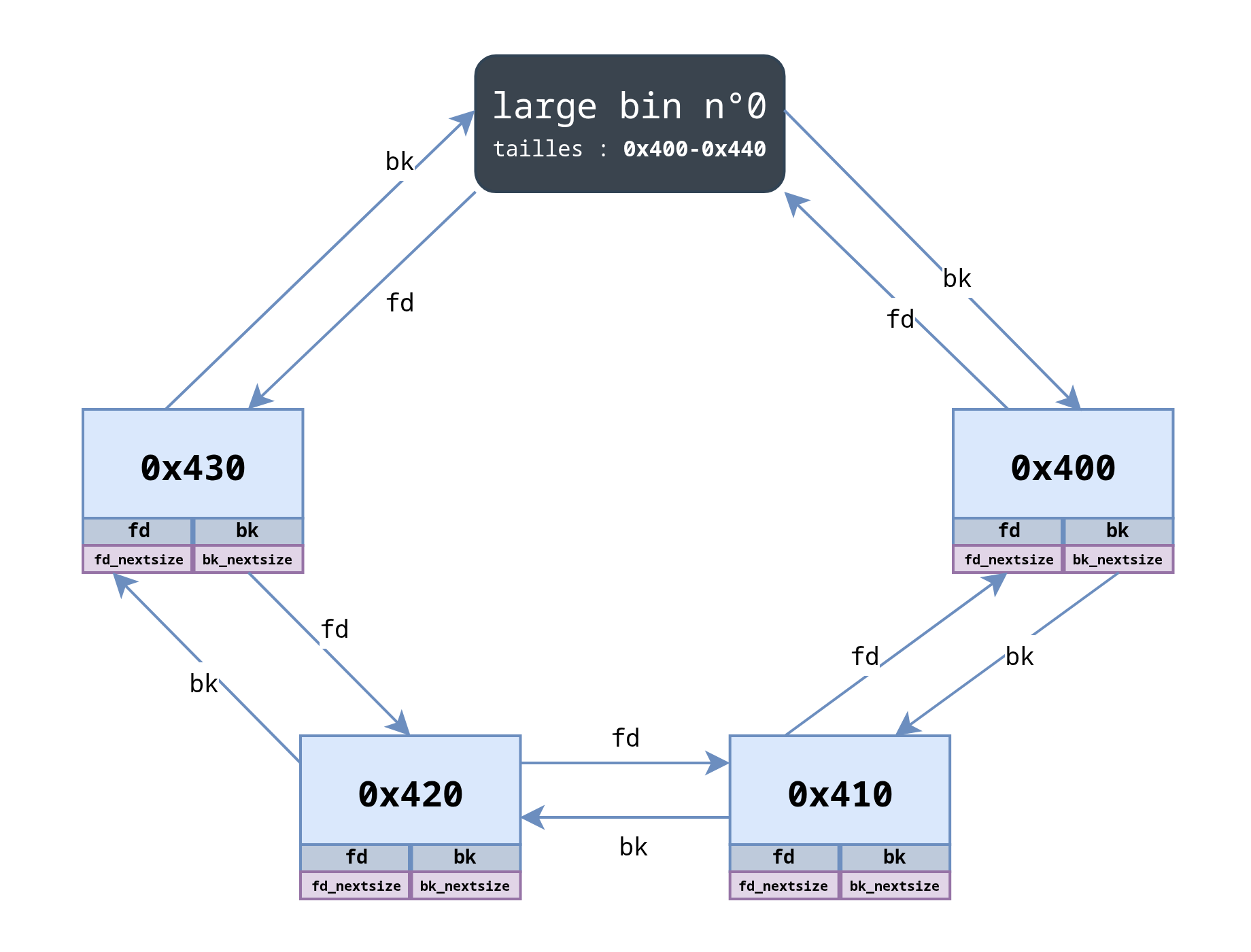
Nous remarquons les choses suivantes :
- même si les blocs n’ont pas la même taille, ils sont organisés en liste doublement chaînée circulaire, exactement comme dans une
small bin(pour l’instant 🤓); - le champ
fdde la premièrelarge bin(situé dans le tableaubinsde l’arène) pointe vers le bloc de plus grande taille (0x430) tandis quebkpointe vers le bloc de plus petite taille (0x400) ; - comme chacun de ces blocs est le premier de sa taille, ils possèdent tous un champ
fd_nextsizeetbk_nextsize.
Bien, jusque-là, rien de bien nouveau, voyons maintenant comment sont organisés les liens fd_nextsize et bk_nextsize :
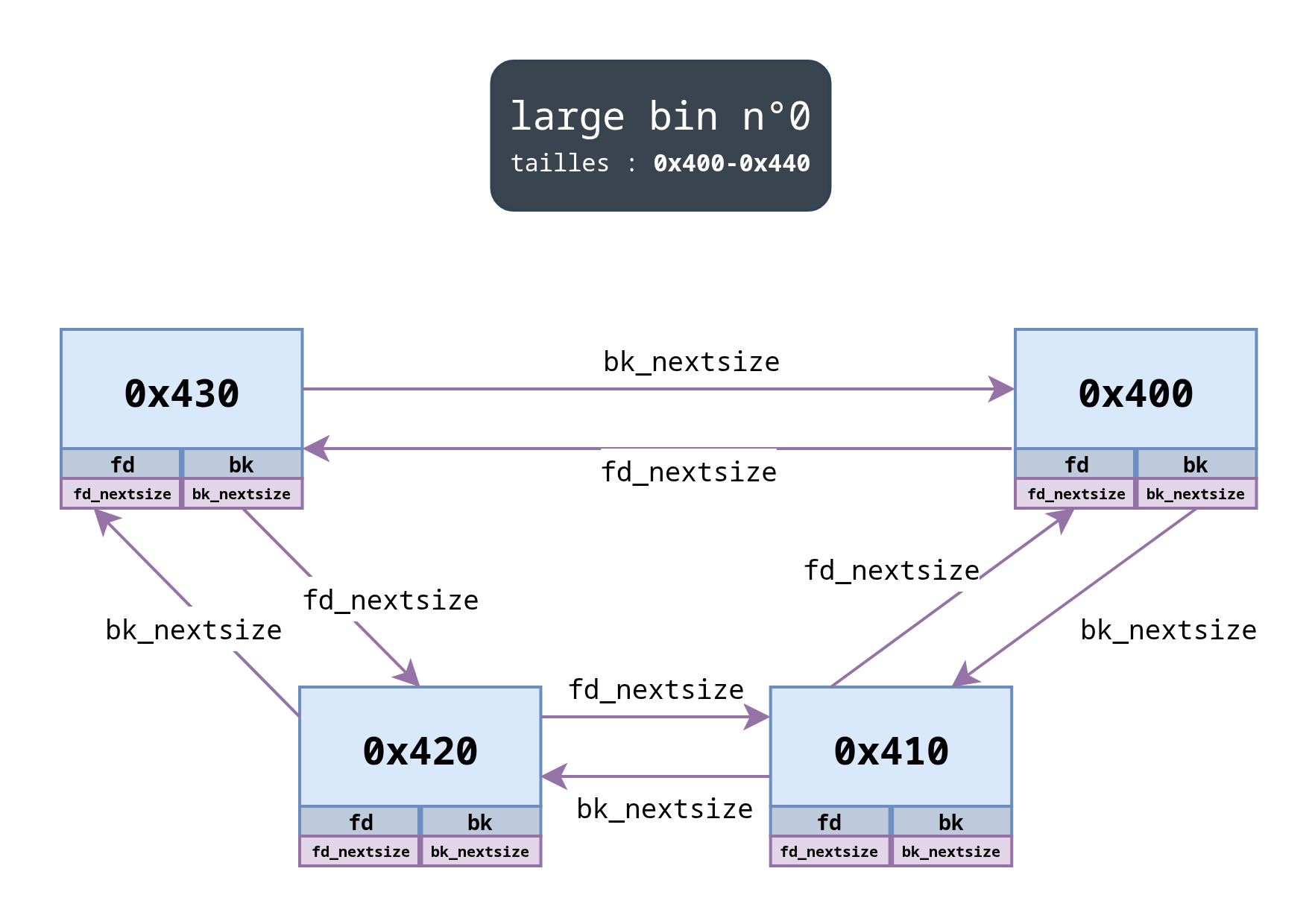
Du fait que l’arène ne dispose que des pointeurs fd et bk, il n’y a aucun lien depuis ni vers elle. Deux points sont toutefois à noter :
fd_nextsizepointe toujours vers le prochain bloc ayant une plus petite taille sauf s’il n’y a pas de bloc plus petit, alors il pointe vers le bloc le plus grand ;bk_nextsizepointe toujours vers le prochain bloc ayant une plus grande taille sauf s’il n’y a pas de bloc plus grand, alors il pointe vers le bloc le plus petit.
⤵️ Insertion de 4x3 blocs
Pour l’instant je ne vois pas tellement de différence entre les deux listes chaînées si ce n’est que, dans la deuxième, il n’y a pas de pointeurs
fd_nextsizeetbk_nextsizedans l’arène.
A ce stade, il n’y pas beaucoup de différences, je vous l’accorde. Je vous propose de modifier la fonction main du précédent programme comme suit :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
/*
(...)
*/
// #define NB_BINS 12
int main()
{
init();
insert_into_large_bin(0x400); // A0
insert_into_large_bin(0x400); // B0
insert_into_large_bin(0x400); // C0
insert_into_large_bin(0x410); // A1
insert_into_large_bin(0x410); // B1
insert_into_large_bin(0x410); // C1
insert_into_large_bin(0x420); // A2
insert_into_large_bin(0x420); // B2
insert_into_large_bin(0x420); // C2
insert_into_large_bin(0x430); // A3
insert_into_large_bin(0x430); // B3
insert_into_large_bin(0x430); // C3
return 0;
}
Voici que cela donne (seulement les liens fd et bk) :
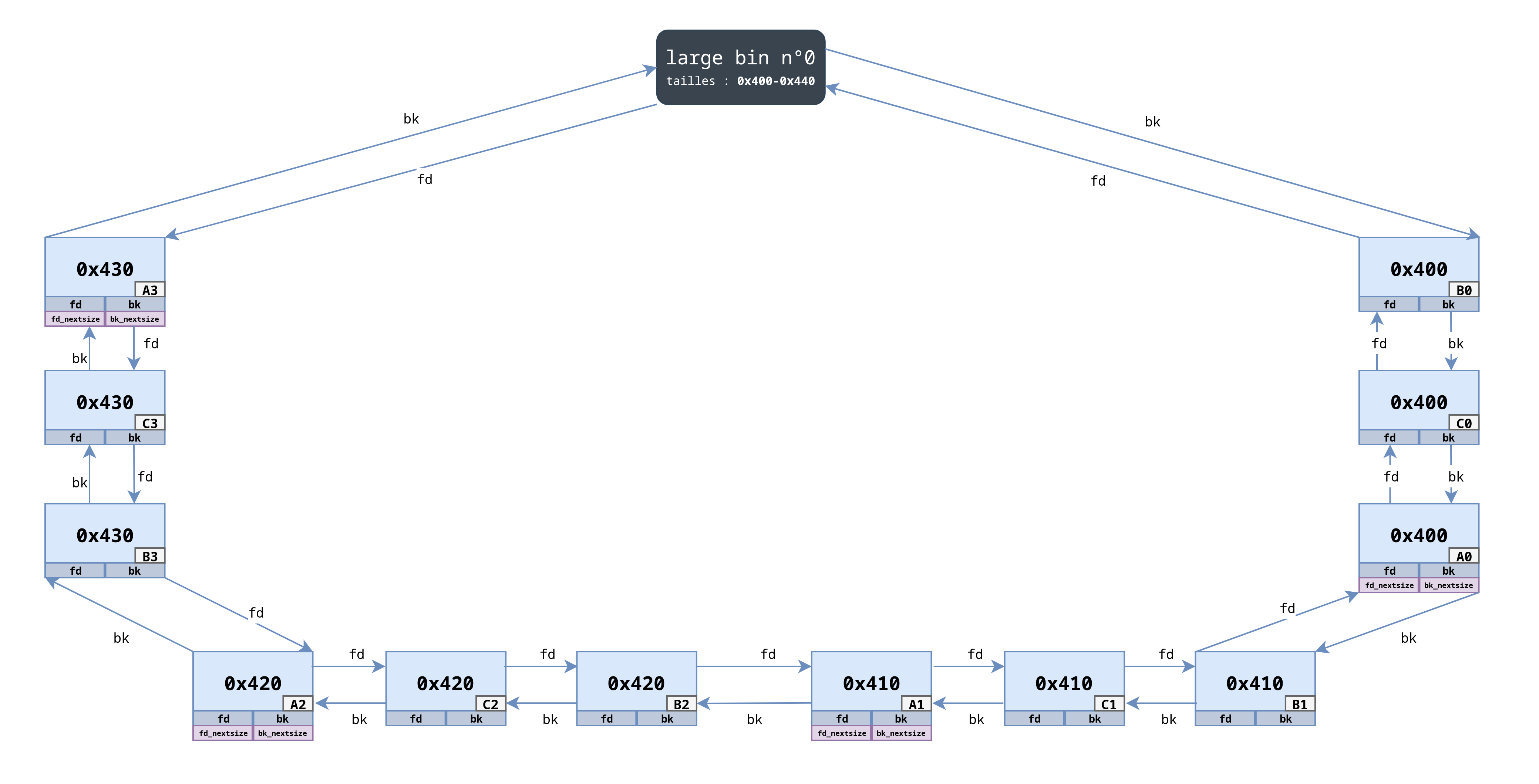
Nous constatons, encore une fois, que :
- les pointeurs
fdparcourent lalarge bindans l’ordre décroissant de tailles ; - les pointeurs
bkparcourent lalarge bindans l’ordre croissant de tailles ; - une fois arrivé à une extrémité, on repart vers l’autre.
Pourquoi les blocs sont liés dans l’ordre
A➡️C➡️Balors qu’ils ont été alloués dans l’ordre :A➡️B➡️C.
C’est l’une des spécificités du fonctionnement de la large bin : lorsqu’un bloc de taille n est inséré alors qu’il y a déjà un ou plusieurs autres blocs de taille n, il est toujours inséré en deuxième position. Cela permet notamment d’éviter de devoir modifier à chaque fois la liste doublement chaînée des pointeurs fd_nextsize et bk_nextsize.
Ainsi, en insérant dans l’ordre les 4 blocs suivants A➡️B➡️C➡️D, le résultat, une fois insérés dans la large bin, sera : A➡️D➡️C➡️B.
Par ailleurs, en parlant de fd_nextsize et bk_nextsize, voici la liste doublement chaînée qui en découle :
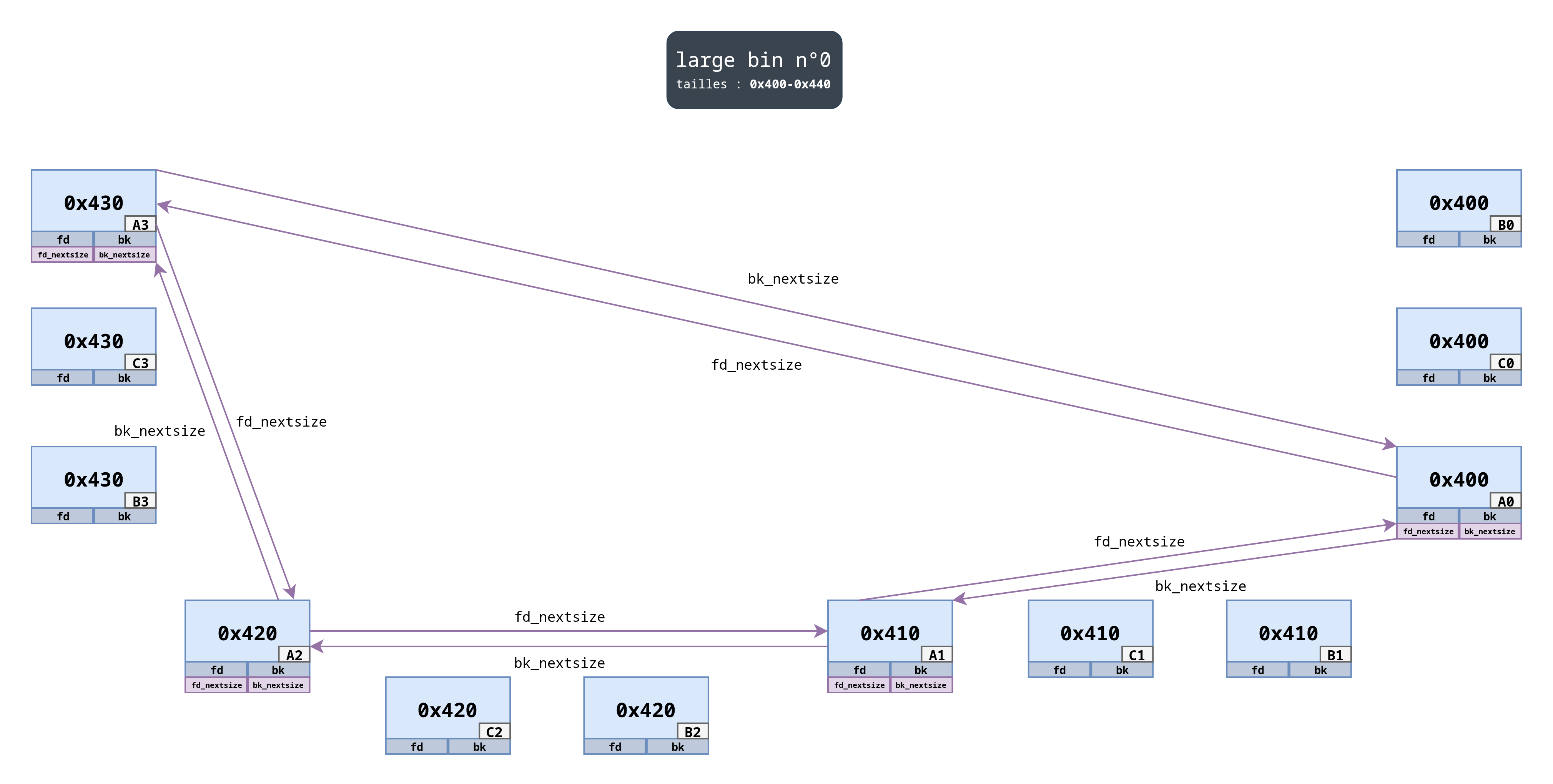
On observe que :
- seuls les premiers blocs de chaque taille (
A1,A2etc.) disposent des pointeursfd_nextsizeetbk_nextsize; - les pointeurs
fd_nextsizeparcourent lalarge bindans l’ordre décroissant de tailles ; - les pointeurs
bk_nextsizeparcourent lalarge bindans l’ordre croissant de tailles ; - une fois arrivé à une extrémité, on repart vers l’autre.
En d’autres termes, fd_nextsize et bk_nextsize pointent vers les différentes têtes de liste (premier bloc d’une taille inséré) afin d’identifier le début d’une nouvelle catégorie de taille.
⤴️ Ordre de recyclage des blocs libres
Pour une taille de bloc donnée (ex : 0x400), le recyclage des blocs libres se fait de manière LIFO ( dernier arrivé premier servi ). Cela signifie que les blocs sont recyclés dans l’ordre inverse de leur insertion dans une large bin.
Prenez par exemple le programme suivant :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main()
{
init();
insert_into_large_bin(0x400); // A
insert_into_large_bin(0x400); // B
insert_into_large_bin(0x400); // C
insert_into_large_bin(0x400); // D
malloc(0x400-0x10); // retourne -> D
malloc(0x400-0x10); // retourne -> C
malloc(0x400-0x10); // retourne -> B
malloc(0x400-0x10); // retourne -> A
return 0;
}
Il est possible de constater, via gdb, que les blocs libres de la large bin ont été recyclés dans le sens inverse de leur insertion, pour une taille donnée.
Bon, j’espère que ces différents schémas et cas de figure vous ont permis de mieux appréhender le fonctionnement des large bins qui est un peu plus complexe que celui des autres types de corbeilles 🥵.
Et il se passe quoi dans le cas où il n’y a qu’un seul bloc libre de
0x430octets et que l’on réalise une allocation de0x400octets ?
Dans ce cas, malloc retourne un pointeur vers un bloc de 0x400 octets tandis que le bloc de 0x30 octets restants retourne au goulag, euh dans la unsorted bin.
Structure et métadonnées d’un bloc issu d’une large bin
Lorsqu’il s’agit du premier bloc d’une taille donnée inséré dans une large bin :
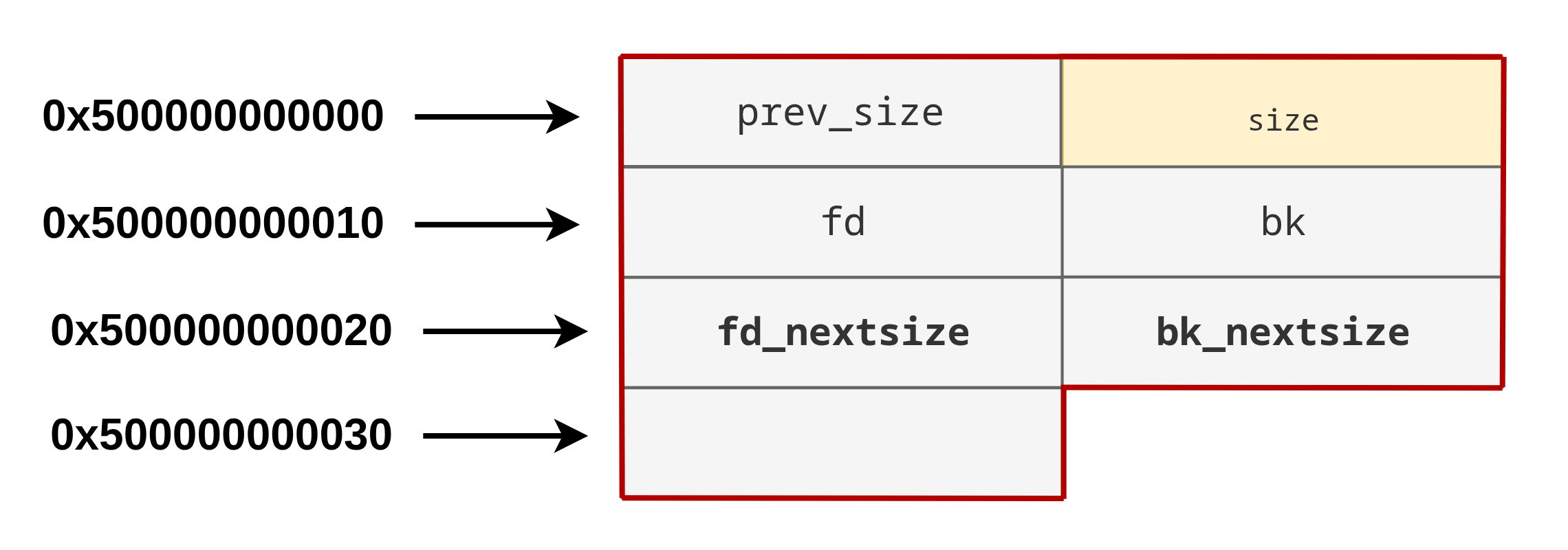
Sinon :

📋 Synthèse
Je sais, nous avons vu pas mal d’informations lors de ce chapitre 😅, je vous propose donc un petit résumé sur l’essentiel du fonctionnement des large bins :
- il y a 64
large bins; - à l’instar des
small bins, leslarge binsstockent les blocs libres de grande taille de launsorted binqui n’ont pas pu être réutilisés ; - chaque corbeille de type
large bingère un intervalle de tailles ( ex :[0x400 ; 0x440[,[0xe00 ; 0x1000[…) ; - cela implique de devoir classer et trier les blocs en fonction de leur taille grâce aux champs
fd_nextsizeetbk_nextsizeprésents uniquement sur le premier bloc de chaque taille ; - les blocs libres sont toujours insérés en seconde position (lorsqu’il y a déjà un bloc de cette taille)
- le fonctionnement est basé sur deux listes doublement chaînées circulaires :
- une première basée sur
fdetbkqui permet de lister tous les blocs d’une corbeille donnée ; - une deuxième basée sur
fd_nextsizeetbk_nextsizequi permet d’identifier, de manière optimisée, le début de chaque nouvelle taille de blocs ;
- une première basée sur
- les blocs libres sont recyclés de manière LIFO : dernier arrivé, premier servi.