Partie 1 - Introduction
Au nom de Dieu, le Tout Miséricordieux, le Très Miséricordieux.
Introduction
Bienvenue dans ce cours d’exploitation du tas !
Initialement, ce cours devait faire partie du cours d’introduction au pwn. Sachant que cela l’aurait alourdit (~50 chapitres), nous avons choisi de les séparer afin que tout ce qui est relatif à l’exploitation du tas soit présent dans un cours dédié.
Il est primordial d’avoir bien entamé le cours d’introduction au pwn avant de commencer celui-ci.
Pour rappel, le tas (ou heap) est la zone mémoire qui permet d’allouer dynamiquement de la mémoire avec
malloc,new, etc.
Que diriez-vous de changer de sujet et de voir autre chose que la pile ? D’autant plus qu’il s’agit d’un mécanisme qui a souvent été au cœur de nombreuses vulnérabilités, entraînant l’évolution constante des protections qui lui sont associées.
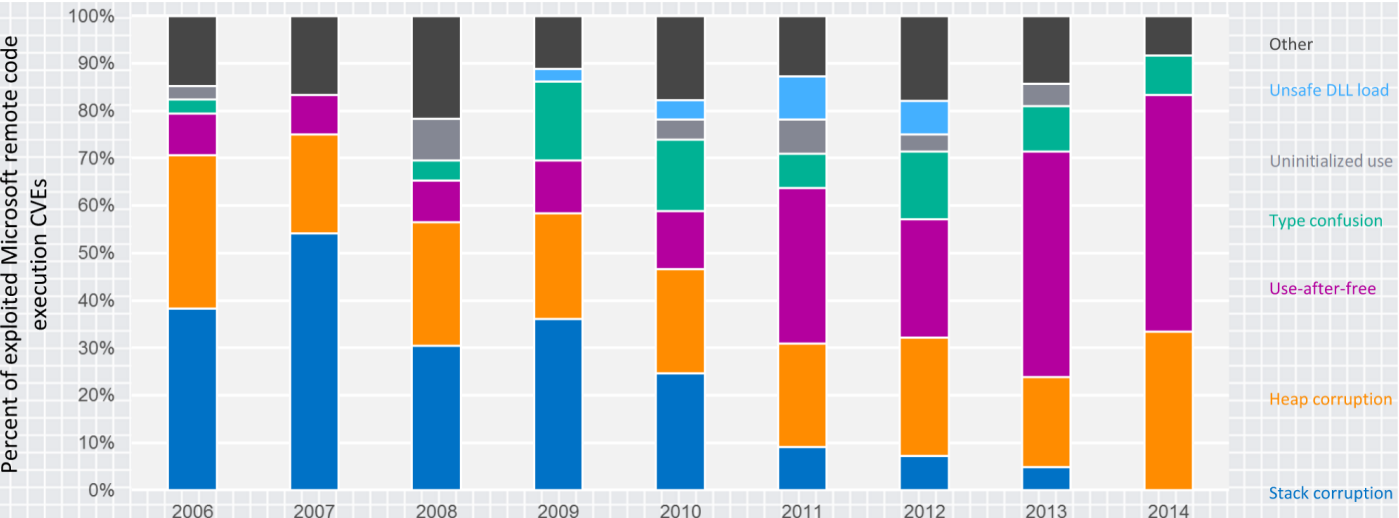
L’exploitation du tas est de plus en plus prisée notamment, au vu des protections de plus en plus contraignantes implémentées pour la pile. Vous remarquerez ci-dessous l’évolution des vulnérabilités exploitées au fil du temps côté Microsoft (le use-after-free est une vulnérabilité du tas):
Nous avions brièvement parlé du tas dans le cours de reverse lorsque nous nous étions intéressés à la localisation des variables dynamiques.
Si vous ne voyez pas où est, à peu près, situé le tas en mémoire, ou que vous avez des lacunes, n’hésitez pas à jeter un œil à la gestion des variables dynamiques.
Concrètement, pour certains usages, il est très pratique de pouvoir allouer dynamiquement de la mémoire. Par exemple : nous souhaitons faire un programme qui, à un moment, doit lire le contenu d’un fichier en mémoire. Néanmoins, nous ne savons pas à l’avance la taille de ce fichier. Comment choisir une taille de buffer adéquate permettant de gérer n’importe quelle taille de fichier ?
En utilisant une taille statique, déterminée à la compilation, nous limitons la taille maximum du fichier que nous souhaitons traiter. De plus, nous utilisons plus de mémoire que nous n’en avons besoin. Pourquoi créer un buffer de 2 Go sur la pile alors que nous allons lire des fichiers de quelques Mo dans 99% des cas ?
En revanche, en utilisant une fonction comme malloc(taille_du_fichier), nous pouvons adapter cette taille dynamiquement, c’est-à-dire, lors de l’exécution. De cette manière, nous allouons seulement ce dont on a besoin et nous sommes même capables de gérer les 1% de fichiers de grande taille.
Par rapport aux chapitres précédents, nous rentrerons parfois bien plus en détails sur certains aspects de l’exploitation dans le tas, notamment lorsque l’on s’intéressera à l’exploitation via les différentes corbeilles disponibles.
Si vous n’avez pas forcément besoin de ces informations au moment où vous lirez ces pages, vous pourrez les mettre de côté jusqu’au jour où vous souhaiterez en savoir plus.
L’exploitation dans le tas n’est pas difficile, c’est juste qu’il y a beaucoup de nouvelles informations et si on ne laisse pas au cerveau le temps de les assimiler, on pourrait croire que cela est trop compliqué. D’où la nécessité de faire de temps en temps des pauses.
La structure du tas
Encore une fois, le tas dont nous parlons ici n’a rien à voir avec la structure de données du même nom. Le tas est implémenté de manière à optimiser l’allocation dynamique de mémoire. Cela signifie qu’il doit être rapide mais également limiter la consommation de mémoire.
Prenons le chemin inverse : essayons de comprendre le fonctionnement du tas à partir des problématiques dont il doit tenir compte.
C’est vrai que le tas est hyper compliqué à comprendre 😰 ?
En fait, le tas en soi n’implique pas des notions hyper pointues que seuls les initiés peuvent comprendre. Par contre, il faut avouer que le fonctionnement du tas est plus complexe que le fonctionnement de la pile car la structure du tas implique plusieurs mécanismes :
- système de bins (poubelles/corbeilles/bac 🥖) permettant d’optimiser les allocations ;
- des structures de données comme les listes chaînées et doublement chaînées ;
- des métadonnées qui stockent les informations d’un bloc de mémoire alloué.
Toutes ces notions, prises une à une, ne sont pas complexes. Ce qui est important est de prendre le temps de faire le lien entre elles et de comprendre comment elles fonctionnent ensemble.
Ainsi, ce n’est qu’en étudiant plusieurs fois le fonctionnement de la heap et de pratiquer que cela finit par se graver dans la mémoire 😉. Je vous propose donc d’y aller crescendo : nous allons faire abstraction de divers mécanismes au début, puis nous les évoquerons au fur et à mesure que nous avançons.
Terminologie
Avant d’aller plus loin, précisons certains termes essentiels qui seront utilisés tout au long de ce chapitre. Nous expliciterons les autres termes petit à petit :
| 🇫🇷 | 🇬🇧 | Description |
|---|---|---|
| tas | heap | Zone mémoire où sont réalisées les allocations dynamiques |
| bloc | chunk | bloc de mémoire allouée par malloc pour une taille donnée. Le tas est constitué de plusieurs blocs. |
| libérer | free | Action de libérer un bloc précédemment alloué. malloc considère alors que l’adresse du bloc ne pointe plus vers de la mémoire allouée. |
| corbeille | bin | Système de recyclage qui contient une liste de pointeurs vers des blocs libérés. Son intérêt est de pouvoir réutiliser, lors d’une allocation, des blocs qui ont été récemment libérés. |
⤵️ L’allocation : malloc
Tous les mécanismes implémentés dans la heap tournent autour de deux principales actions :
- l’allocation de mémoire ;
- la libération de mémoire.
Intéressons-nous dans un premier temps à l’allocation.
L’allocateur de mémoire
Lorsque nous évoquons le fonctionnement du tas, nous devrions plutôt parler du fonctionnement de l’allocateur de mémoire utilisé par malloc. Bien que la fonction malloc fasse partie du standard C, le standard ne spécifie pas la manière d’implémenter l’allocateur sous-jacent. Ce dernier dépend de la bibliothèque standard C utilisée et peut varier d’un système à un autre.
De ce fait, un programme C utilisant malloc pourra être compilé sous Linux et Windows et malloc remplira la même fonction : elle prend en paramètre une taille et retourne un pointeur vers une zone mémoire ayant au moins la taille spécifiée. Toutefois, libre à Linux et Windows de gérer les optimisations et la sécurité de l’allocation de mémoire.
Voici quelques allocateurs connus :
| Allocateur | Utilisé par |
|---|---|
| ptmalloc | Linux |
| dlmalloc | ptmalloc est basé sur dlmalloc |
| jemalloc | FreeBSD |
| tcmalloc | |
| PartitionAlloc | Chromium |
| libumem | Solaris |
| mimalloc | Microsoft |
En ce qui nous concerne, nous nous focaliserons sur ptmalloc qui est utilisé dans la glibc. Par la suite, lorsque l’on évoquera malloc en tant qu’allocateur, cela signifiera automatiquement que nous parlons de l’allocateur ptmalloc.
Déroulement de l’allocation
Le rôle de malloc, et des fonctions du même type, est d’allouer de la mémoire (merci Sherlock 🕵️♂️). Voici le paramètre et le retour de cette fonction :
- paramètre : une taille
nen octets ; - retour : un pointeur vers un bloc.
Tout d’abord, malloc n’alloue pas exactement n octets. Deux principaux facteurs sont à prendre en compte :
- la taille minimale d’un bloc qu’il est possible d’allouer ;
- les contraintes d’alignement.
Voici un résumé de ces facteurs en 32 et 64 bits :
| 32 bits | 64 bits | |
|---|---|---|
| Taille minimale d’un bloc | 0x10 octets | 0x20 octets |
| Contrainte d’alignement | La taille d’un bloc doit toujours être un multiple de 0x10 octets | La taille d’un bloc doit toujours être un multiple de 0x10 octets |
Par exemple, malloc(1) dans un programme 32 bits retourne un pointeur vers un bloc de 0x10 octets.
Dans d’anciennes versions de la glibc, telle que la 2.5, la contrainte d’alignement est de 8 octets.
Que se passe-t-il si on exécute
malloc(0xf)en 32 bits ?
La logique voudrait qu’un bloc de 0x10 octets soit alloué, car suffisant. Néanmoins, la taille du bloc alloué sera de 0x20. En effet, lorsque malloc retourne un bloc de taille n, seuls n-4 octets (ou n-8 en 64 bits) sont utilisables. Or 0x10 - 4 == 0xc et comme 0xf > 0xc, un bloc de taille totale 0x10 ne sera pas suffisant pour contenir 0xf octets.
Les 4 (ou 8) octets inutilisables (par l’utilisateur) d’un bloc sont utilisés par l’allocateur pour stocker des métadonnées. Pour l’instant, gardons juste en tête que des métadonnées sont présentes dans les blocs, nous nous y pencherons bien en détails un peu plus tard.
Pour savoir quelle est la taille réellement demandée à
malloc, il suffit d’ajouter 4 (ou 8 en 64 bits) à la tailleninitialement demandée. Ensuite, en faisant attention à la taille minimale et à la contrainte d’alignement de0x10octets, vous pouvez en déduire la taille exacte du bloc retourné parmalloc.
Voyons ce qui se passe dans le tas lorsque ces différentes allocations sont réalisées (en 32 bits) :
1
2
3
4
5
6
7
8
9
10
11
#include <stdlib.h>
int main()
{
malloc(1);
malloc(0x10);
malloc(0x1f);
malloc(0xc);
return 0;
}
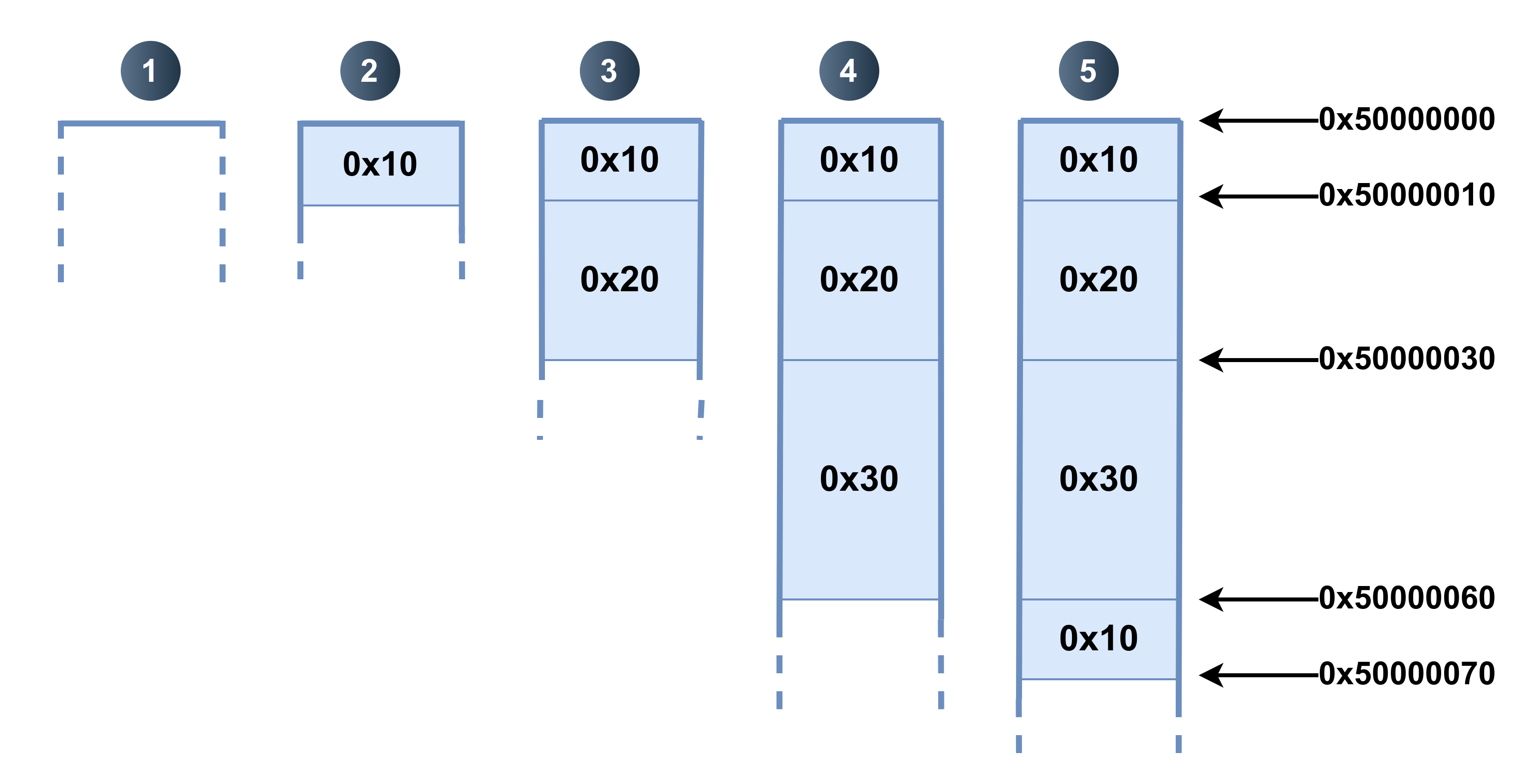
- Initialement le tas est vide ;
malloc(1): pour utiliser1 + 4 = 5octets en mémoire, les0x10minimum pour un bloc suffisent.mallocretourne0x50000000;malloc(0x10): pour utiliser0x10 + 4 = 0x14octets, un bloc de0x10ne suffit pas ; un bloc de0x20est alors utilisé.mallocretourne0x50000010;malloc(0x1f): pour utiliser0x1f + 4 = 0x23octets, un bloc de0x30octets suffit.mallocretourne0x50000030;malloc(0xc): pour utiliser0xc + 4 = 0x10octets, un bloc de0x10suffit.mallocretourne0x50000060.
Nous remarquons plusieurs choses :
- contrairement à la pile, le tas se remplit de haut en bas, des adresses basses vers les adresses hautes ;
- les blocs sont alignés de manière contiguë en mémoire. Cela n’est pas toujours le cas dans la réalité.
⤴️ La libération : free
Après avoir vu comment l’allocation de mémoire est grosso modo réalisée, il est temps de voir comment les blocs sont libérés. Autant l’allocation est simple à comprendre, voire triviale, autant la libération, c’est une autre histoire 😅.
Prenons, à titre d’exemple, un programme de ce type :
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdlib.h>
int main()
{
for(unsigned long long i =0; i < 1000000000; i++)
{
void *falestine = malloc(1);
free(falestine);
}
return 0;
}
Théoriquement, ce programme alloue un milliard de fois 1 octet, tout en libérant sa mémoire. Dans le cas d’un allocateur naïf et non optimisé, on pourrait supposer qu’à chaque allocation, une zone mémoire différente est allouée. Ce qui signifie que pour exécuter la boucle dans son entièreté, il faudrait que le programme dispose d’au moins 16 Go (un milliard de blocs de 0x10 octets).
Or en pratique, il suffit moins de 0x10 octets car le bloc qui a été alloué, puis libéré sera réutilisé lors du prochain appel à malloc car c’est toujours la même taille qui est allouée. Autant le recycler ♻️.
🗑️ Le système de bins
Ce que vous ne savez pas, c’est que malloc, il est très écolo ; s’il peut réutiliser un bloc qui a été précédemment libéré afin d’éviter d’allouer un nouveau bloc de mémoire, il le fera !
Afin d’optimiser les allocations dynamiques, il existe un système de bins (corbeilles) permettant de garder dans un coin, les différents blocs qui ont été libérés. De cette manière, si un bloc de taille n doit être retourné par malloc et qu’un bloc libéré de taille n est disponible, alors ce dernier est retourné et aucune nouvelle zone mémoire n’est allouée.
Encore une fois, en début de chapitre, nous étudions ces différents aspects de manière “macro”, sans rentrer dans les détails ni les spécificités de chaque mécanisme. Il vaut mieux comprendre ces différents principes de manière globale avant de sombrer, euh plonger 😅, dans les abysses de la heap.
Reprenons le précédent exemple et libérons certains blocs :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <stdlib.h>
int main()
{
void *a = malloc(1);
void *b = malloc(0x10);
void *c = malloc(0x1f);
void *d = malloc(1); // Ajoutons un bloc de 16 octets
void *e = malloc(0xc);
// Ce qui nous intéresse est ce qui se passe ci-dessous
free(a);
free(c);
free(d);
return 0;
}
Comment voir dans gdb ce qui se passe dans le tas avec ce programme ?
Pour l’instant, je vous déconseille de jeter un œil à ce qui se passe réellement dans gdb, vous risquez de ne pas y comprendre grand-chose. Promis, nous verrons ensemble comment naviguer dans la heap lorsque l’on débogue dans gdb 😇.
Pour l’instant, concentrons-nous sur le fonctionnement global de malloc. Voici l’état du tas lorsque ce programme sera exécuté :
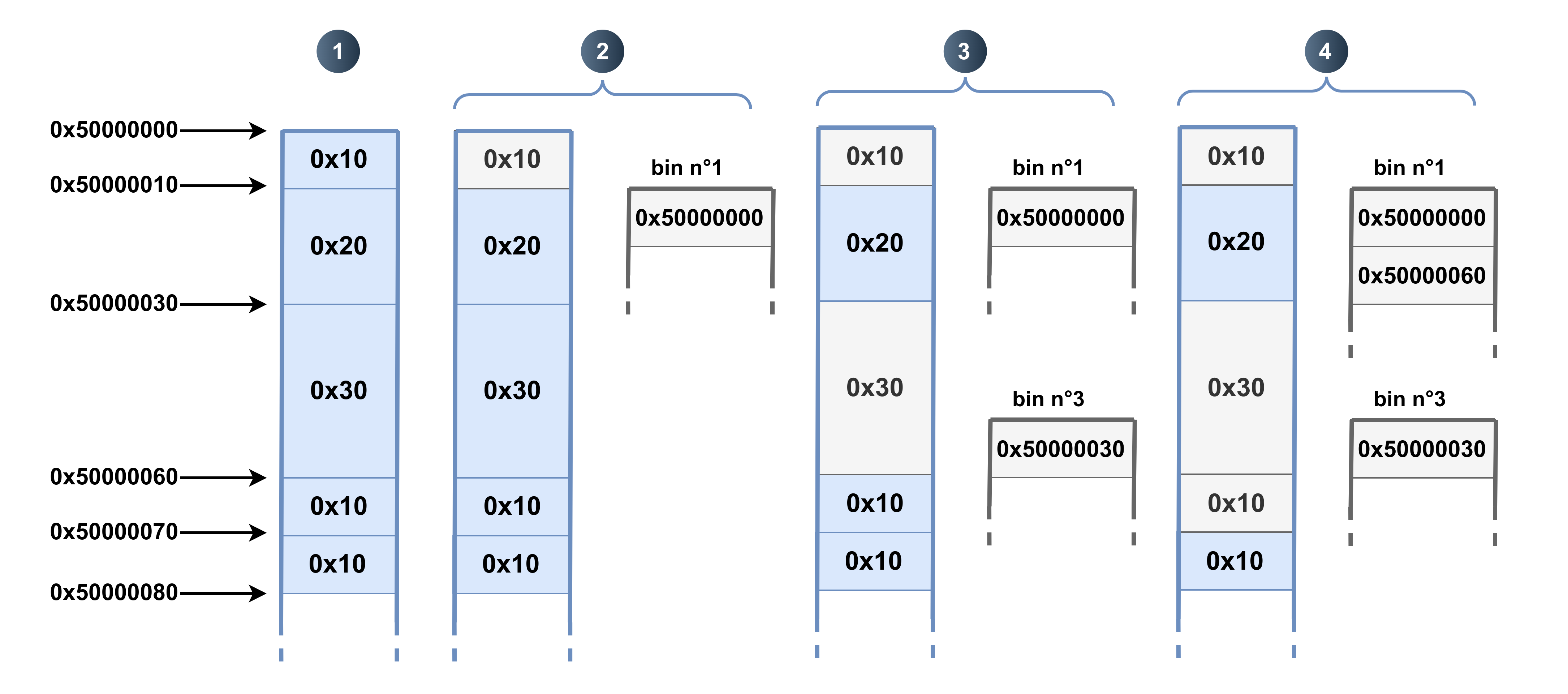
- état initial avec
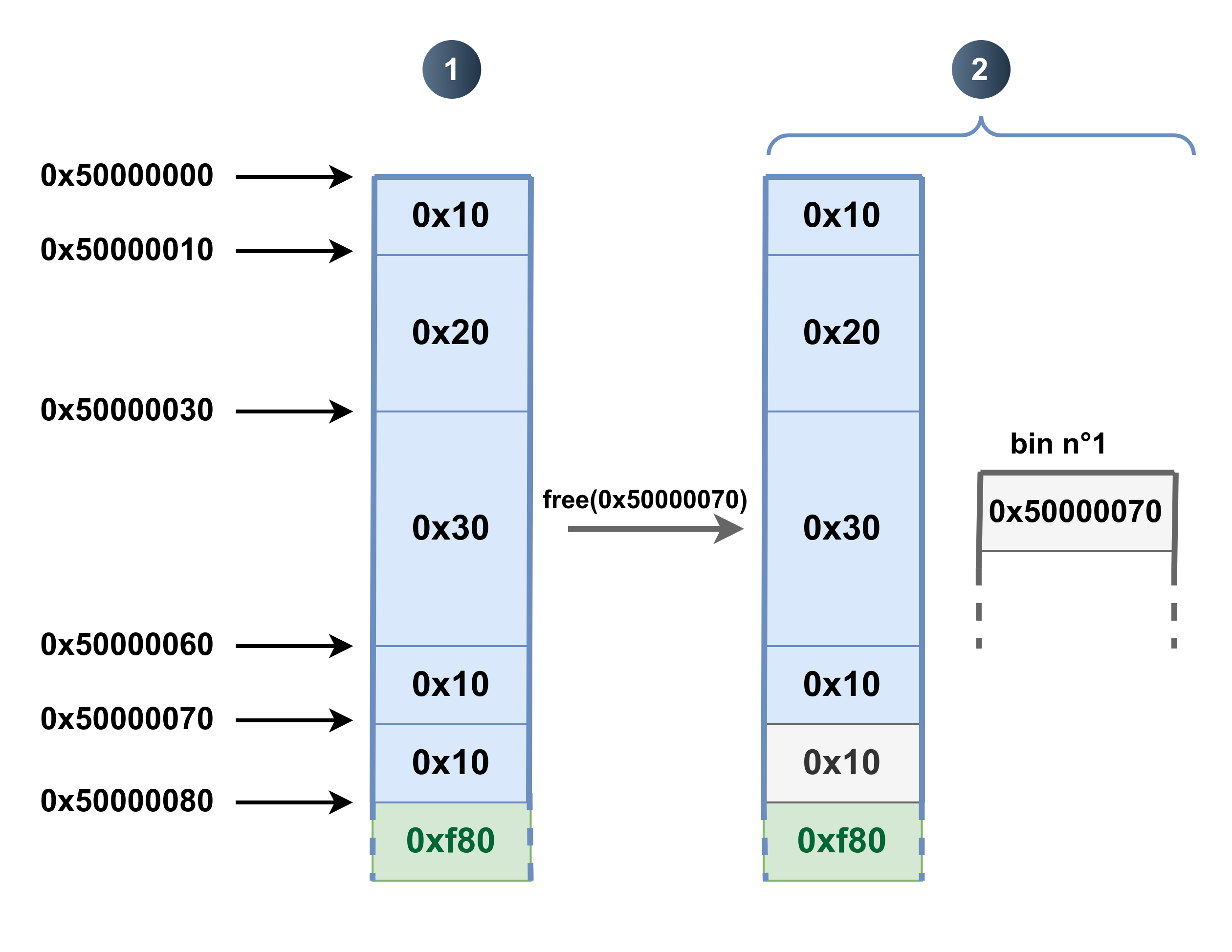
malloc(1)en plus par rapport au précédent exemple ; free(a)(oufree(0x50000000)) : le premier bloc est libéré et est mis dans la bin n°1, celle qui gère les blocs libres de0x10octets ;free(c)(oufree(0x50000030)) : le troisième bloc est libéré. Cette fois-ci il n’est pas placé dans la bin n°1 mais dans la bin n°3, celle qui gère les blocs de0x30octets. Idem ici, c’est l’adresse du bloc qui est insérée ;free(d)(oufree(0x50000060)) : le quatrième bloc est libéré. Comme il est de taille0x10, il est ajouté à la bin n°1.
Quelques remarques :
- contrairement à ce que l’on pourrait croire, le bloc n’est pas copié du tas vers la bin ; c’est l’adresse du bloc libéré qui y est insérée ;
- il existe plusieurs bins et chacune gère une taille de bloc donnée. En réalité, le système de corbeilles est un peu plus complexe que cela car il en existe plusieurs types dont certaines qui ne sont pas restreintes à une seule taille en particulier ;
- le contenu d’un bloc libéré n’est déplacé nulle part, il reste là où il était. Dans les faits, les premiers octets peuvent être écrasés lors de l’appel à
freepour indiquer où se situe la corbeille idoine. Nous reviendrons sur ce mécanisme lorsque nous entamerons la gestion des métadonnées dans le tas.
Pourquoi les blocs
c(0x50000030) etd(0x50000060) n’ont pas été fusionnés pour former un bloc libre, plus gros, de0x40octets ?
La fusion de blocs libres dans le tas est désignée par consolidation. La consolidation de deux blocs libres n’est pas toujours réalisée. Pour simplifier, malloc considère que :
- pour de petits blocs : il n’y a pas besoin de les consolider, il est plus intéressant de les mettre dans une bin ;
- pour des blocs plus larges : il est intéressant de les consolider lorsque certaines conditions sont respectées.
En réalité, sous certaines conditions, il est possible que de petits blocs soient consolidés entre eux. Nous en reparlerons lorsque l’on s’intéressera aux
fastbins.
🏔️ Le top chunk (ou bloc du sommet 🥖)
En parlant de consolidation, il est temps d’introduire un bloc assez particulier, le top chunk. Paradoxalement, le bloc du sommet n’est pas présent en haut du tas mais plutôt en bas si nous reprenons la convention d’affichage du tas avec les adresses basses en haut et les adresses hautes en bas. C’est donc bien le bloc du sommet, mais à l’envers 🙃.
Le bloc du sommet est en quelque sorte un bloc toujours libre sans pour autant être présent dans une bin en particulier. Il s’agit d’un bloc initialement présent dans la heap et qui sera toujours présent dans le tas, au cours de l’exécution du programme, en étant toujours le dernier bloc du tas, en partant du haut.
Ce bloc a une taille fixe au démarrage du programme, par exemple 0x1000, et à chaque fois qu’une allocation dynamique est réalisée, malloc va réduire la taille du top chunk afin d’allouer un bloc suffisamment large pour contenir n octets spécifiés en paramètre à malloc.
Pour vous donner une image, le bloc du sommet c’est un peu comme un gros morceau de cachir que l’on découpe rondelle par rondelle.
Et on fait comment quand y en a plus ? 🤤
Eh bien on en rachète ! Ainsi, lorsque qu’il ne reste plus assez d’espace dans le top chunk, sa taille est augmentée afin de satisfaire de prochaines allocations.
L’allocation avec le bloc du sommet
Reprenons les précédentes allocations en tenant compte, cette fois-ci, de la présence du bloc du sommet :
1
2
3
4
5
void *a = malloc(1);
void *b = malloc(0x10);
void *c = malloc(0x1f);
void *d = malloc(1);
void *e = malloc(0xc);
Cela donne :
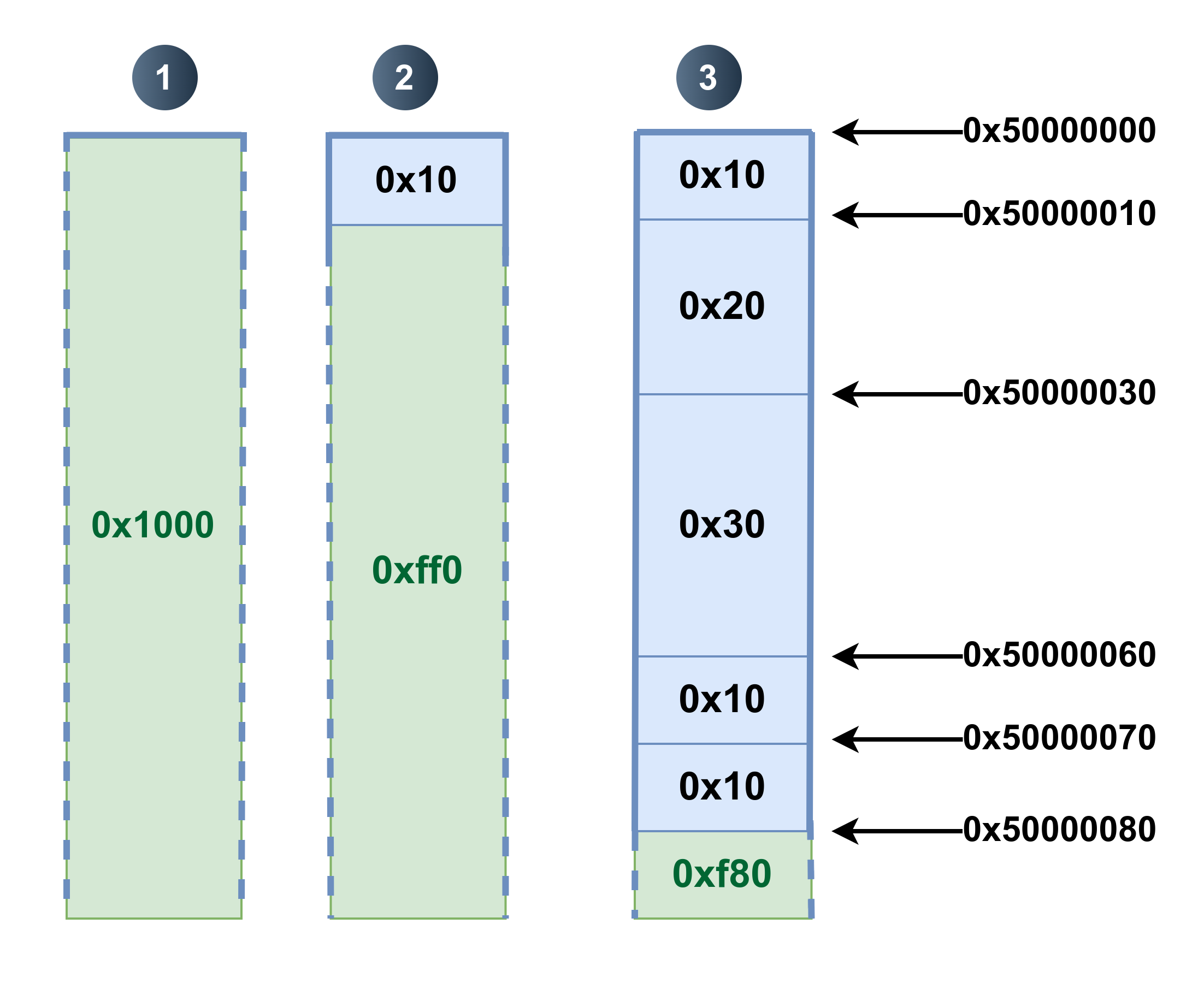
- initialement, seul le top chunk est présent ;
- lorsque le premier bloc de
0x10octets est alloué, ce sont en réalité 16 octets qui sont séparés du bloc du sommet 🟢 ; - ainsi de suite, pour chaque bloc alloué, sa taille en octets est retirée du bloc du sommet. Comme nous avons alloué au total
0x80octets, la taille du bloc du sommet en est diminuée tout autant.
La libération avec le bloc du sommet
Comprendre comment fonctionne l’allocation avec le bloc du sommet, c’est facile. Qu’en est-il avec la libération de blocs ? Le fonctionnement est presque le même. En effet, la différence va être le fait qu’un bloc libéré peut être consolidé, ou non. Le choix concernant la consolidation va principalement dépendre de la taille du bloc.
Prenons tout d’abord l’exemple d’un petit bloc libéré :
- état initial ;
free(0x50000070): le dernier bloc alloué est libéré. Comme il s’agit d’un bloc de petite taille, il n’est pas consolidé (fusionné) avec le top chunk.
Que se serait-il passé si un bloc de grande taille avait été libéré ?
- état initial : dans cet exemple, le dernier bloc, avant le bloc du sommet, est de plus grande taille ;
free(0x50000010: lorsque le gros bloc est libéré, il est consolidé avec le bloc du sommet.
Ainsi, voici comment se résume la libération de blocs contigus au bloc du sommet :
- bloc de petite taille : le bloc libéré est placé dans la corbeille idoine ;
- bloc de grande taille : le bloc libéré est consolidé avec le bloc du sommet.
D’accord, mais comment on sait si un bloc est de petite ou grande taille ? Quelle est la limite entre les deux ?
Cela dépend essentiellement de deux choses :
- la version de la glibc : la gestion des corbeilles évolue au fil du temps. De plus, certaines versions introduisent de nouvelles bins comme la
2.26qui introduit le tcache, une bin dont on aura le temps de parler de détails lors des prochains chapitres ; - l’architecture (
x86oux86_64).
Voici comment la dichotomie entre de petit et gros bloc est réalisée :
- en 32 bits :
| glibc < 2.26 | glibc ≥ 2.26 | |
|---|---|---|
| Petit bloc | ≤ 0x40 | ≤ 0x400 |
| Grand bloc | > 0x40 | > 0x400 |
- en 64 bits :
| glibc < 2.26 | glibc ≥ 2.26 | |
|---|---|---|
| Petit bloc | ≤ 0x80 | ≤ 0x410 |
| Grand bloc | > 0x80 | > 0x410 |
Ces valeurs ne sont pas totalement exactes. Toutefois, elles permettent d’avoir une idée de l’ordre de grandeur de ce que l’on considère comme un petit bloc / gros bloc.
A la fin des chapitres liés au tas nous aurons l’occasion de bien détailler ce qui est considérer comme petit / gros bloc.
📋 Synthèse
Dans ce chapitre, nous avons introduit les bases du tas et son rôle dans l’allocation dynamique de mémoire.
Le tas repose sur deux actions principales :
- l’allocation via
malloc:- taille ajustée (alignement + taille minimale) ;
- présence de métadonnées dans les blocs ;
- utilisation d’un allocateur (comme
ptmalloc) ;
- la libération via
free:- les blocs sont placés dans des corbeilles pour être réutilisés ;
- cela évite de nouvelles allocations coûteuses.
Nous avons également vu :
- les bins (corbeilles) : recyclent les blocs libres selon leur taille ;
- la consolidation : fusionne certains blocs libres ;
- le top chunk (bloc du sommet) : réserve de mémoire utilisée en dernier recours.
Le tas repose sur plusieurs mécanismes simples, mais leur interaction rend son fonctionnement plus complexe. Les prochains chapitres détailleront ces mécanismes.