Partie 8 - Analyse statique d'un mini-programme - les affectations de valeurs, la lecture et écriture en mémoire (4/5)
Analyse statique d’un mini-programme : les affectations de valeurs, la lecture et écriture en mémoire (4/5)
Je sais que ça fait un petit moment que l’on a laissé IDA ouvert sans avoir pris le temps d’avancer sur notre reverse, mais maintenant que vous avez les bases dans la gestion de la pile et des registres, nous pouvons y revenir !
A présent que nous savons ce que sont les registres et comment fonctionne la pile, nous en devrions pas avoir trop de mal à comprendre ce qui se passe dans la fonction main.
Ce sera également l’occasion de revoir certaines notions et d’en aborder de nouvelles :
- le passage des arguments lors d’un appel de fonction
- la gestion des variables locales
- les boucles
- les conditions
- etc.
Rappels de la fonction main
Pour rappel, voici à quoi ressemblait notre fonction main :
1
2
3
4
5
6
7
int main()
{
int a = 2;
int b = 3;
return a+b;
}
Et son code désassemblé par IDA :

Tout d’abord, intéressons nous à ce qui est affiché entre le main proc near et ; __unwind {. IDA a fait le choix de remplacer certains offsets (ou décalage mémoire) avec des noms tels que var_4, argc etc.
En reverse on utilise énormément la notion d’offset par rapport à l’utilisation d’une adresse “fixe”.
Par exemple, on préfère dire que la première variable est située à l’adresse
ebp-8(-8étant l’offset) que de dire qu’elle est située à l’adresse0x7fffff10.Pourquoi ? Tout simplement car de nos jours, les adresses utilisées dans un programme sont aléatoires ce qui signifie que d’une exécution à une autre, l’adresse de la variable locale peut changer tandis que
ebp-8pointera toujours vers la variable en question.
Les offsets des variables et arguments
En fait, parmi les offset qu’IDA renomme, nous pouvons en distinguer 2 catégories :
- ceux qui ont un offset positif ➕ : ce sont les arguments. En effet, il sont situés en dessous de
ebpcomme vu avez pu le constater au précédent chapitre sur la pile. - ceux qui ont un offset négatif ➖ : ce sont les variables locales. Elles sont situées au dessus de
ebp.
Pour rappel, comme les adresses basses sont vers le haut, tous les éléments situés au-dessus d’
ebpont donc une adresse plus petite : c’est pourquoi les variables locales ont un offset négatif.De la même manière, les arguments étant situés en-dessous d’
epb, ces derniers ont un offset positif.
Le fait que les variables locales aient un offset négatif n’est vrai que lorsque l’on utilise l’offset par rapport à
ebp. En effet, dans certains cas, il est possible d’utiliser un offset par rapport àesppour accéder à ces variables. Cet offset sera donc positif dans ce cas.Idem pour les arguments qui ont un offset positifs relativement à
ebp, si on utiliseesp, les offsets seront négatifs.
IDA préfère en général utiliser des noms de variables pour désigner les variables locales ou les arguments. L’avantage est que l’on sait directement que ebp+var_8 pointe vers la variable qu’IDA a nommé var_8 car elle se situe à l’offset -8 par rapport à ebp.
Vous vous demandez peut-être pourquoi il n’a pas appelé les deux variables a et b comme c’est le cas dans le code source. Et bien c’est très simple ! IDA ne sait tout simplement pas comment elles s’appellent. Rappelez-vous, lors de la compilation les noms des variables locales ne sont pas conservés. Ainsi, lorsque IDA désassemble le programme, il voit seulement que les zones mémoire ebp-8 et ebp-4 sont utilisées. IDA en déduit alors qu’il s’agit de variables locales qu’il renomme var_8 et var_4.
argc, argv et envp
On avait bien deux variables locales dans notre programme. Mais pourquoi IDA liste 3 arguments que sont
argc,argvetenvpalors que notre fonctionmainne prend aucun argument ?
En fait argc, argv et envp sont les 3 arguments que l’on peut donner, ou non, à une fonction main avec :
argc: le nombre d’arguments donnés lors du lancement du programme. Par exemple, si le programme est lancé ainsi :./exe arg1 arg2alorsargcvaudra 3 et non pas 2. En effet, rappelez-vous, le premier argument d’un programme en C est le nom du programme tel qu’il a été lancé.argv: un tableau de chaînes de caractères où chaque élément représente un argument. Le premier élément, à l’index 0, est donc le nom du programme.envp: un tableau de caractères où chaque élément est une paireclé=valeurqui correspond aux variables d’environnement. Par exemple :HOME=/home/username
Il faut également savoir une chose, bien que dans le code source aucun argument n’est donné à notre fonction int main()eh bien argc, argv et envp seront tout de même présents en mémoire car ils y sont toujours insérés au lancement du programme. C’est peut-être la raison pour laquelle IDA crée toujours automatiquement 3 variables à leur nom.
Le code désassemblé
Nous venons de voir ce que signifiaient les informations situées au-dessus du code assembleur. Entrons désormais dans le vif du sujet : le code assembleur !
Nous n’allons pas revenir en détail sur ce que font les instructions suivantes :
1
2
3
push ebp
mov ebp, esp
sub esp, 0x10
Il s’agit du prologue qui permet d’avoir une stack frame assez grande pour y stocker les variables locales.
Une fois le prologue terminé, nous avons les deux instructions suivantes :
1
2
mov [ebp+var_8], 2
mov [ebp+var_4], 3
Avant d’aller plus loin, je vous propose que l’on comprenne de quoi est composé une instruction en assembleur avant de nous intéresser plus spécifiquement à l’instruction mov.
Les différentes syntaxes : Intel et AT&T
J’ai choisi d’éviter le sujet jusqu’à présent afin de ne pas vous surcharger d’informations qui n’étaient pas nécessaires mais celle-ci a son importance afin de ne pas être perturbé lors de l’utilisation de certains désassembleurs.
Comme vous le savez, après la compilation d’un programme, on obtient un exécutable qu’il est nécessaire de désassembler pour pouvoir lire le code assembleur. Néanmoins, pour l’assembleur x86 il y a deux manières de lire (ou syntaxes) l’assembleur : Intel et AT&T.
Je vous propose de voir concrètement la différence entre les deux. Allez dans le dossier où se trouve le programme exe que nous analysons et lancez la commande suivante afin de désassembler via objdump le programme avec la syntaxe Intel : objdump -M intel -d exe.
Nous obtenons ceci pour la fonction main:
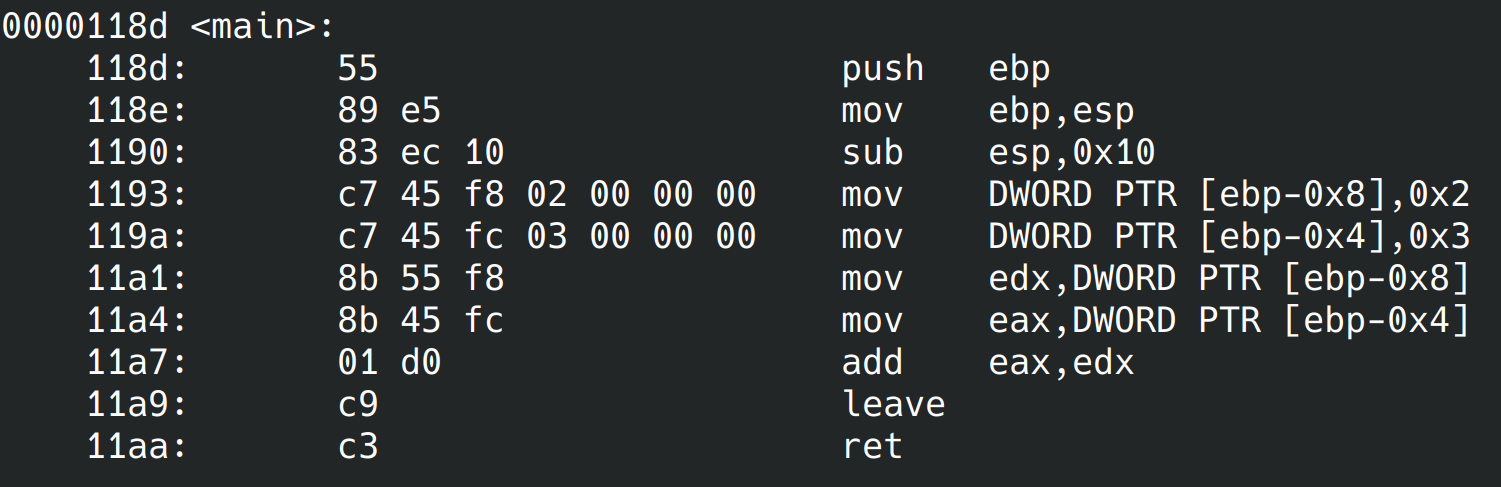
Rien de nouveau, c’est également comme ça qu’IDA a désassemblé notre fonction main. Maintenant désassemblons-le avec la syntaxe AT&T via la commande : objdump -d exe.
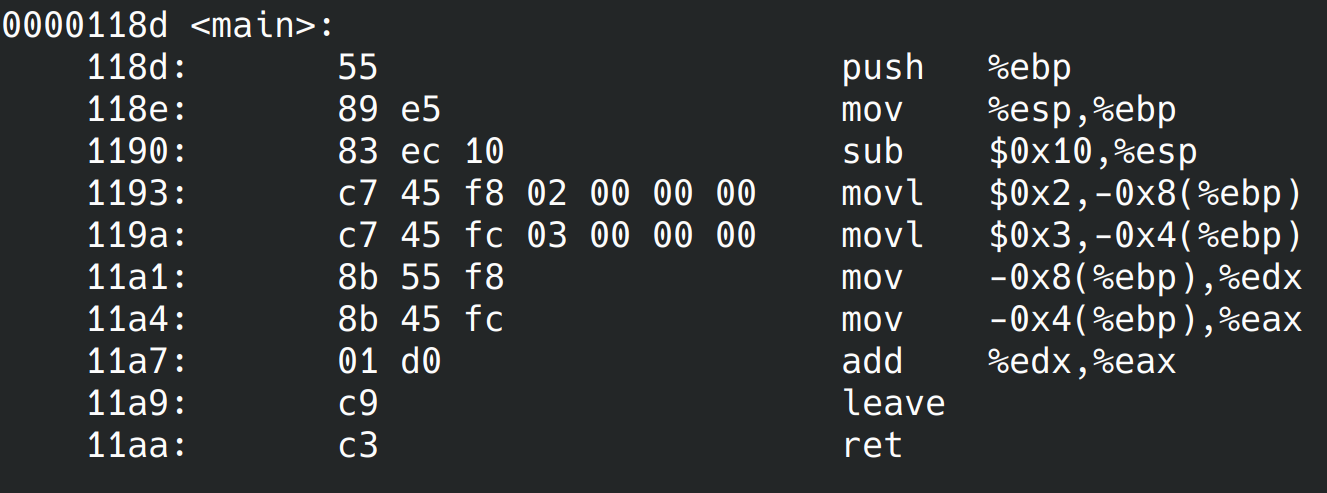
Comme vous pouvez le constater, il s’agit toujours de la même fonction mais celle-ci a été désassemblée, disons, différemment 😅. En fait, il s’agit tout simplement d’une manière différente de représenter le code assembleur.
Avant d’expliciter les différences entre ces deux syntaxes, un peu de vocabulaire :
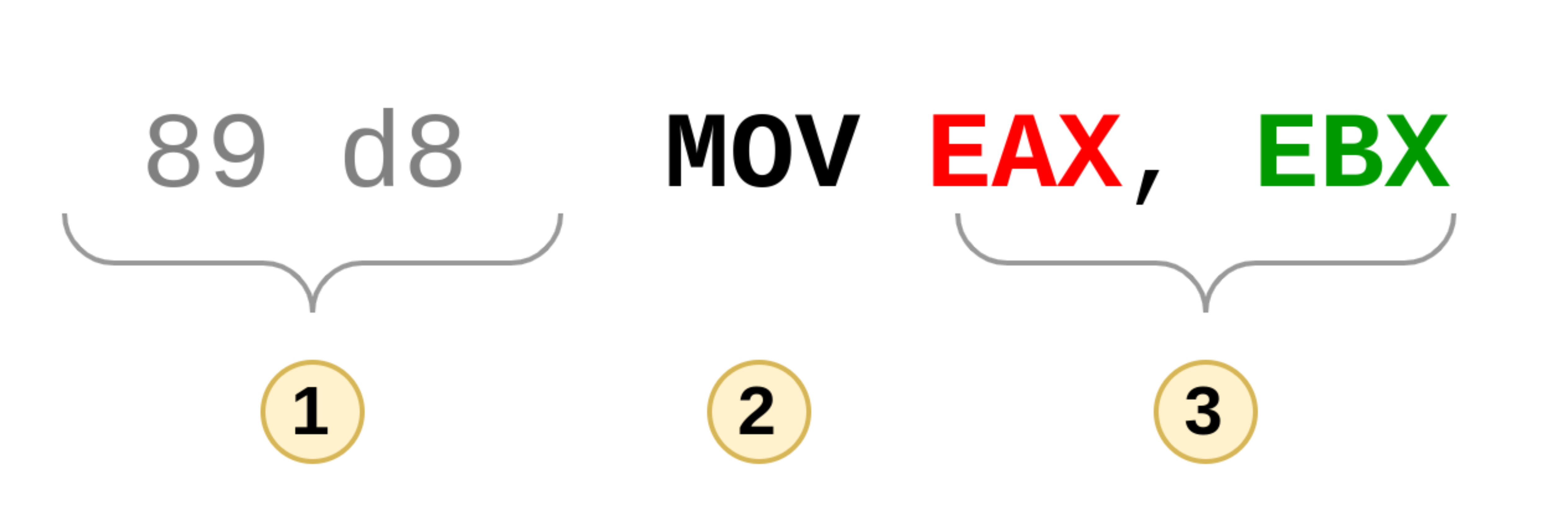
- opcode : il s’agit des octets tels qu’ils sont lus par le processeur et qui aboutit à l’exécution de l’instruction assembleur associée
- mnémonique : c’est en quelque sorte le nom de l’instruction exécutée
- opérandes : registres, pointeur ou valeurs concrètes utilisées par l’instruction
Il est important de garder ces définitions en tête car cela fait partie du jargon en reverse.
Comme convenu, voici les principales différences entre ces deux syntaxes :
- Ordre de la destination et de la source :
- Intel : l’opérande de gauche est la destination tandis que l’opérande de droite est la source
- AT&T : l’inverse. l’opérande de droite est la destination tandis que l’opérande de gauche est la source
- Préfixes utilisés :
- Intel : Pas de préfixes en particuliers
- AT&T : Les registres sont préfixés par
%et les constantes par$
- Format des pointeurs :
- Intel : Les pointeurs vers une zone mémoire sont placés entre crochets avec leur offset. Exemple :
[ebp+8] - AT&T : Les pointeurs vers une zone mémoire sont placés entre parenthèses et les offsets sont placés avant la première parenthèse. Exemple :
8(%ebp)
- Intel : Les pointeurs vers une zone mémoire sont placés entre crochets avec leur offset. Exemple :
Personnellement mon cœur penche vers la syntaxe Intel qui est, selon moi, bien plus lisible que celle d’AT&T avec des & et % partout 😵💫. Ce choix est évidemment subjectif. De tout manière, comme vous avez pu le voir, chaque outil utilise par défaut la syntaxe qu’il préfère. Ainsi objdump utilise par défaut la syntaxe AT&T tandis qu’IDA utilise la syntaxe Intel.
L’instruction mov
Revenons à nos moutons 🐏 !
L’instruction mov tire son nom de move qui signifie déplacer en anglais. Ainsi, cette instruction va permettre de réaliser le déplacement d’une valeur d’un endroit à un autre. A proprement parler il s’agit plus d’une copie que d’un déplacement. Il ne faut donc pas s’imaginer que la zone “source” est mise à zéro par mov : elle garde son contenu inchangé.
Voyons ensemble les différentes manières d’utiliser mov car il y en a pas mal ! Je préfère que nous les voyons ensemble afin que vous sachiez où retrouver ces informations lorsque vous tomberez nez-à-nez avec une de ces formes.
De plus, selon l’usage, une forme sera utilisée plutôt qu’une autre. Par exemple, il y a une forme permettant d’écrire ✏️ en mémoire et une autre d’y lire 📄.
Toutes les instructions que nous voyons en détails dans ce cours sont présentes dans une page Annexes.
mov reg_d, value
Opérandes
reg_d: registre de destinationvalue: valeur immédiate (ou concrète, constante).
Détails
Cette forme est la plus simple : elle affecte la valeur value au registre de destination reg_d.
C’est une manière de réaliser des affectations de valeurs concrètes (immédiates).
Exemple
Imaginons que eax vaille 0xaabbccdd puis que l’on exécute l’instruction mov eax, 0xdeadbeef. Alors la valeur de eax sera 0xdeadbeef.
Équivalent en C
Je vous propose de voir quelques équivalents en C (quand c’est possible) des différentes instructions étudiées, cela sera peut-être plus simple pour la comprendre.
1
2
3
4
5
// Initilisation du registre
int x = 0xaabbccdd; // eax
// Equivalent de : mov eax, 0xdeadbeef
x = 0xdeadbeef;
mov reg_d, reg_s
Opérandes
reg_d: registre de destinationreg_s: registre source
Détails
Le contenu du registre source reg_s est copié dans le registre de destination reg_d.
C’est une manière d’affecter le contenu d’une variable à une autre.
Utilisation d’un debugger
Je vous propose d’utiliser un debugger d’assembleur pour exécuter pas à pas des instructions x86. Le site asmdebugger.com est assez simple et permet de réaliser ce que nous voulons faire.
Il y en a un autre, assez simple d’utilisation, mais qui a plusieurs inconvénients :
- Il n’est pas possible de modifier la valeur initiale des registres à la main, nous devrons donc le faire via des instructions du type
mov reg, value. (Même problème chez asmdebugger.com) - Il n’est pas possible dans lancer le code directement en mode pas à pas, mais il y a une astuce pour y parvenir : lancer l’exécution et rapidement appuyer sur “pause”, vous aurez alors accès
- Les valeurs des registres ne sont affichés qu’en décimal
Exemple
Alors voici le code assembleur que je vous propose d’exécuter pas à pas sur asmdebugger.com :

Cliquez ensuite sur Restart. Vous pourrez alors cliquer sur Next instruction pour exécuter le code assembleur pas à pas.
Comme il n’est pas possible de donner des valeurs initiales à la main aux registres, nous le faisons via les deux premières instructions.
Vous pourrez ainsi constater qu’à l’issue de l’exécution de la dernière instruction mov ebx, eax, ebx vaut désormais 0xaabbccdd.
Question : que se passe-t-il si on exécute le code suivant :
1
2
3
4
mov eax, 0xdd
mov ebx, 0x11223344
mov ebx, eax
Est-ce que seule l’octet de poids faible de ebx va changer ? Je vous propose de tester vous-même sur le debugger. Nous aurons amplement le temps de répondre à cette question en détails ultérieurement.
N’hésitez pas à faire plusieurs tests au fur et à mesure que nous apprenons de nouvelles instructions assembleur.
De cette manière vous serez actifs et cela vous facilitera l’apprentissage et la compréhension de l’assembleur.
Équivalent en C
1
2
3
4
5
6
// Initilisation des registres
int a = 0xaabbccdd; // eax
int b = 0x11223344; // ebx
// Equivalent de : mov ebx, eax
b = a; // b = 0xaabbccdd
📄 mov reg_d, [reg_p]
Opérandes
reg_d: registre de destinationreg_p: registre pointant vers une zone mémoire
Détails
Cette forme est un peu plus complexe que les précédentes car elle fait appel à la notion de pointeur.
Ici reg_d est le registre de destination qui recevra une valeur, jusque-là rien de bien nouveau. Par contre, reg_p ne contient pas la valeur qui sera copiée mais un pointeur vers la valeur en question.
Ainsi, c’est la valeur pointée par reg_p qui est copiée dans reg_d.
C’est une manière de lire des données depuis la mémoire.
Exemple
Imaginons que je veuille exécuter ces instructions :
1
2
3
4
mov eax, 0x700000F0
mov ebx, 0xcafebabe
mov ebx, [eax]
On suppose également que l’adresse 0x700000F0 pointe vers l’entier de 4 octets 0x1a2b3c4d.
Malheureusement les deux sites évoqués précédemment ne permettent pas d’initialiser ou manipuler facilement la mémoire, nous allons donc nous contenter de schémas, à défaut de pouvoir utiliser des debuggers plus puissants.
Mais ne vous inquiétez pas, une partie dédiée à l’utilisation d’un “vrai” debugger arrive !
L’état des registres avant l’exécution de mov ebx, [eax] est le suivant :
Lorsque la dernière instruction mov ebx, [eax] sera exécutée, alors ebx vaudra 0x1a2b3c4d. Vous voyez la logique ?
Légères variantes
Il existe quelques variantes où un offset (positif ou négatif) est ajouté au registre reg_p, par exemple :
1
2
mov edx, [eax + 8]
mov ecx, [esi - 0x2000]
Équivalent en C
Cette forme est très similaire à l’utilisation de pointeurs en C :
1
2
3
4
5
6
7
8
9
// Initilisation des registres
int *a = 0x700000f0; // eax
int b = 0xcafebabe; // ebx
// Initilisation de la mémoire
*a = 0x1a2b3c4d;
// Equivalent de : mov ebx, [eax]
b = *a; // b = 0x1a2b3c4d
Vous comprenez maintenant pourquoi connaître le C est un prérequis avant d’entamer le reverse 🤓 ? Ça nous facilite pas mal la compréhension des instructions assembleur !
✏️ mov [reg_p], reg_s
Opérandes
reg_p: registre pointant vers une zone mémoirereg_s: registre source
Détails
Normalement, si vous avez bien saisi le principe de l’instruction mov reg_d, [reg_p] vous devriez deviner le fonctionnement de celle-ci.
En fait il s’agit de l’inverse de la précédente instruction. En effet, ici on copie la valeur du registre reg_s vers la zone mémoire pointée par reg_p.
C’est une manière d’écrire des données en mémoire.
Exemple
Reprenons le précédent exemple, nous avions initialement :
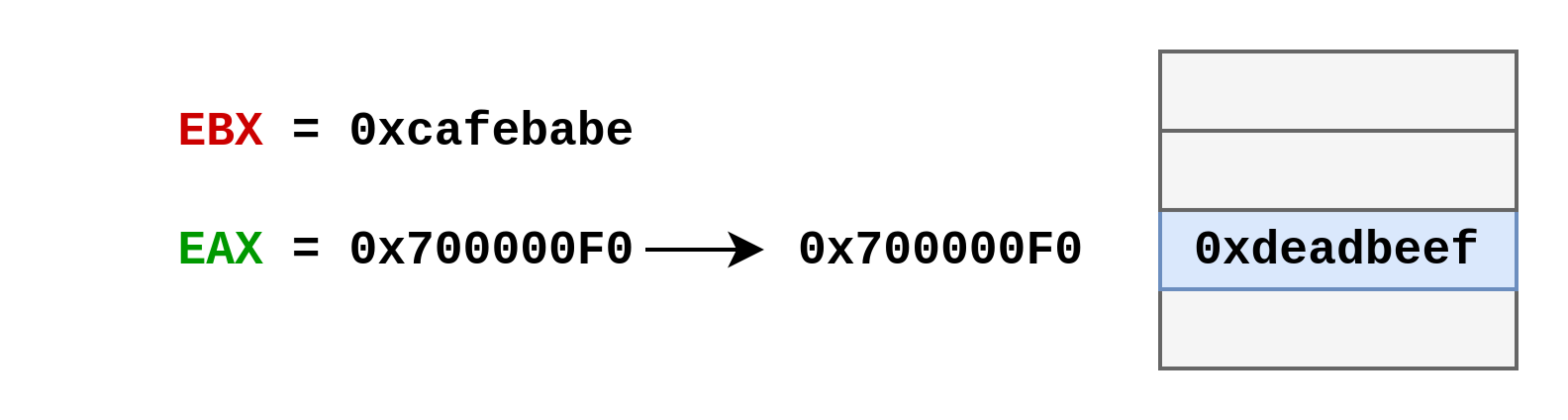
Que se passe-t-il si j’exécute désormais mov [eax], ebx ?
Eh bien après l’exécution de cette instruction, ces deux registre et cette zone mémoire seront dans cet état :
Légères variantes
Il existe quelques variantes où un offset (positif ou négatif) est ajouté au registre reg_p. Il est également possible de remplacer reg_s par une valeur immédiate. Par exemple :
1
2
mov [ebp + 8], edi
mov [esi - 0x200], 0xdeadbeef
Équivalent en C
1
2
3
4
5
6
7
8
9
// Initilisation des registres
int *a = 0x700000f0; // eax
int b = 0xcafebabe; // ebx
// Initilisation de la mémoire
*a = 0x1a2b3c4d; // 0x700000f0 -> 0x1a2b3c4d
// Equivalent de : mov [ebx], eax
*a = b; // 0x700000f0 -> 0xcafebabe
Il n’existe pas d’instruction permettant directement de déplacer des données d’une zone mémoire à une autre du type :
mov [reg_p_d],[reg_p_s].Pour plus d’informations, c’est par ici (en 🇬🇧).
Il existe d’autres formes mais moins courantes. Ces quatre-là sont les principales, les autres étant des variations ou dérivées.
Vous pouvez avoir la liste de toute les formes ici (attention les yeux 🥶).
Résumé des différentes formes
Je sais, ça fait beaucoup d’informations d’un coup, voici ainsi un résumé avec un exemple pour chacun des 4 formes possibles. Supposons que dans les 4 cas l’état initial est le suivant :
Alors le résultat est :
Les valeurs en 🔴 sont celles qui ont changé lors de l’exécutions de l’instruction tandis que celles en ⚫ sont les valeurs à l’origine du changement.
Pour le coup, il est intéressant d’apprendre ces différentes formes car nous verrons par la suite de nouvelles instructions qui ont également différentes formes. Par exemple, pour comparer deux valeurs :
1
2
3
cmp ecx, 0x12
cmp rdi, rsi
cmp rax, [rbp + 8]
Normalement, si vous avez compris le principe avec mov, vous devriez comprendre quels sont à chaque fois les deux valeurs comparées dans ces 3 précédentes instructions.
L’instruction lea
J’ai choisi de mettre cette instruction dans ce chapitre car même si on ne l’a pas encore vue, elle peut être parfois mal comprise. De plus, elle ressemble en quelque sorte à un mov donc autant en parler dès à présent.
lea signifie Load Effective Address. Cette instruction est principalement utilisée pour charger des adresses, avec ou sans offset ajouté.
lea reg, [...]
Opérandes
reg: registre de destination[...]: valeur qui est souvent une adresse mémoire
Détails
Cette instruction a ainsi une seule forme où la première opérande est toujours un registre, la seconde opérande est une valeur qui est souvent une adresse vers une zone mémoire.
Ce que fait lea est tout simplement la copie de l’opérande de droite, sans la déréférencer, vers le registre de destination.
Voici quelques exemples :
1
2
3
lea eax, [0x400000] ; ici eax = 0x400000
lea edx, [ebp+8] ; ici edx = ebp +8
lea ecx, [ebx+eax] ; ici ecx = ebx+eax
Exemple
Comme
leane déréférence pas la seconde opérande, l’instructionlea eax, [0x400000]copie bien0x400000danseaxet non pas la valeur pointée par0x400000.
En fait, plus simplement, lea copie la valeur entre les crochets vers le registre de destination. En d’autres termes, lea reg, [...] est équivalente à mov reg, ....
J’en vois déjà certains froncer les sourcils 🤨.
Mais si cela est équivalent à faire un
mov, pourquoi se casser la tête avec une instruction en plus ?
En fait, contrairement à mov, l’instruction lea permet de faire de petites opérations au niveau de l’opérande de droite. Par exemple, si je souhaite affecter à ecx la somme de ebx et eax en utilisant mov, je suis obligé d’utiliser une instruction supplémentaire telle que add pour faire l’addition et ensuite stocker le résultat dans ecx avec mov.
Tandis qu’avec lea, je peux simplement faire : lea ecx, [ebx + eax]. Vous savez quoi ? On peut même faire lea ecx, [ebx + eax*2]😎.
Ainsi, lea permet de :
- Stocker le résultat de simples opérations en écrivant une seule instruction
- De manipuler des adresses en y ajoutant, ou non, un offset
S’il n’y avait qu’une seule chose à retenir de
lea: il s’agit d’unmovqui copie la “valeur entre crochets” vers la destination.