Partie 4 - L'assembleur
L’assembleur
Introduction
On peut enfin commencer à faire de l’assembleur ouuu 🙄 ?
Nous y voilà ! Dans ce long chapitre nous allons aborder l’assembleur sous divers aspects. Tout d’abord, nous n’allons pas voir directement toutes les instructions assembleur existantes et imaginables mais nous allons poursuivre notre lancée afin de continuer à faire des liens entre reverse et fonctionnement d’un programme.
Ainsi, nous allons nous intéresser dans un premier temps à la représentation assembleur des principaux éléments d’un programme, par exemple :
- les fonctions
- les variables (locales, dynamiques, globales, statiques …)
- les structures, tableaux et objets
- le passage des arguments
- la récupération de la valeur de retour
- les boucles
- les conditions
- etc.
Je vous propose également de nous intéresser dans ce chapitre et les suivants aux outils que l’on utilise quasi-systématiquement en reverse comme les désassembleurs, décompilateurs et débogueurs.
En fait c’est à partir de ce chapitre que l’on entre de plus en plus dans le monde de la rétro-ingénierie. C’est vrai que de prime abord les notions que nous allons voir vont paraître complexes voire bizarres. Mais au fur et à mesure que nous avançons vous allez vous y habituer et, je l’espère 😅, trouver ça intéressant et amusant 🤩🥳 !
Qu’est-ce que l’assembleur ?
L’assembleur ou langage machine, est le langage le plus bas niveau qu’il puisse y avoir. Par “plus bas niveau” on entend qu’il s’agit d’un langage compris directement par l’ordinateur et plus précisément par le processeur.
En fait, c’est le processeur qui se charge d’exécuter toutes les instructions assembleur. Que ce soit les accès en mémoire vive (RAM), les calculs, les appels de fonctions, bref, c’est lui LE cerveau de l’ordinateur.
Avant de pouvoir coder dans des langages plutôt facilement compréhensible par des humains, les programmes étaient développés en assembleur, ce qui permettait de faire exécuter le processeur les instructions que l’on voulait.
De nos jours, les développeurs privilégient des langages plus haut niveau qui offrent de nouveaux paradigmes de programmation comme la programmation orientée objet (ou POO), la programmation parallèle et concurrente …
Ainsi, l’assembleur est beaucoup moins utilisé en tant que langage de programmation qu’il ne l’était auparavant. Si, en tant que reverser, on s’embête à apprendre l’assembleur c’est parce que l’on doit pouvoir comprendre, en mettant la main dans le cambouis, ce que fait un programme compilé lorsque les outils de reverse ne nous permettent pas d’aller plus loin. Cela arrive notamment avec les programmes fortement obfusqués (ou protégés).
Cependant, l’assembleur étant le langage le plus bas niveau, il est utilisé dans les projets où il est nécessaire d’être le plus performant possible en termes d’opérations, calculs etc. Exemple : les projets orientés “temps réel” ou les projets liés au décodage d’audio/vidéo.
A titre d’exemple, le récent projet dav1d qui est un décodeur du codec AV1 dispose de plus de 200 000 lignes d’assembleur 🤯 !

Sur l’émission Underscore_ de Micode, ils expliquent que ce choix leur permet d’atteindre un facteur x10 en termes de rapidité.
Comme quoi, l’assembleur a de beaux jours devant lui 😎 !
🔢 Une assemblée d’assembleurs
Etant donné que l’assembleur est le langage machine exécutée directement par le processeur, il faut que le processeur puisse le comprendre. On pourrait donc penser qu’il n’y a qu’un seul type d’assembleur mais ce n’est pas aussi simple que cela.
En effet, de la même manière qu’il y a différents carburants (diesel, essence, kérosène …) pour les moteurs, il existe différents langages assembleur (x86, ARM, MIPS, RISC-V …) selon le processeur. Pour pousser l’analogie un peu plus loin, il faut voir un langage assembleur un peu comme un carburant.
C’est-à-dire que c’est une source que l’on donne en entrée au moteur (processeur) afin qu’il puisse fonctionner. De manière générale, on sait qu’un carburant est brûlé afin de produire des explosions qui font tourner le moteur.
Il peut y avoir tout de même de petites différences : un moteur diesel est plus “long à la détente” qu’un moteur essence qui est plus nerveux. Un moteur essence allumé a encore besoin d’utiliser les bougies pour provoquer des explosions alors que le moteur diesel peut provoquer les explosions qu’avec des compressions.
Ainsi, d’un point de vu “macro”, il n’ y a pas tellement de différence entre un programme compilé pour x86 ( processeurs utilisés par AMD et Intel) ou ARM (processeurs utilisés sur la majorité des smartphones, Mac …) du point de vue d’un programmeur ou de l’utilisateur (quoique peut être la taille de l’exécutable final).
Mais en termes d’exécution, à l’œil nu, personne ne pourrait savoir de quel processeur il s’agit. Par contre, si on fait le reverse 🧐 de deux applications , l’une compilé en x86 et l’autre en ARM, nous verrons que l’assembleur utilisé n’est pas le même !
Pour vous illustrer ces propos, prenons l’exemple d’une fonction très simple qui ne fait que retourner 0 :
1
2
3
4
int rien()
{
return 0;
}
Voici comment va être compilée cette fonction selon différents langages assembleurs (vous pouvez essayer aussi sur ce site) :
- x86_64 :
1 2 3 4 5
push rbp mov rbp, rsp mov eax, 0 pop rbp ret
- ARM :
1 2
mov w0, 0 ret
- MIPS :
1 2 3 4 5 6 7 8 9
addiu $sp,$sp,-8 sw $fp,4($sp) move $fp,$sp move $2,$0 move $sp,$fp lw $fp,4($sp) addiu $sp,$sp,8 jr $31 nop
- RISC-V :
1 2 3 4 5 6 7 8
addi sp,sp,-16 sd s0,8(sp) addi s0,sp,16 li a5,0 mv a0,a5 ld s0,8(sp) addi sp,sp,16 jr ra
Ce sont les 4 langages d’assembleur les plus utilisés. Il y en a plein d’autres mais qui ne sont pas forcément encore très utilisés, autant ne pas nous y attarder (exemple : l’assembleur de votre TI-82 🤓).
On parle également de d’architectures pour parler des différents langages d’assembleur.
Comme vous pouvez le constater, certains assembleurs sont plus verbeux que d’autres 😅. Nous aurons l’occasion de comprendre pourquoi il y a de telles différences.
Vous pouvez voir quelle est l’architecture de votre PC en utilisant les commandes :
lscpu | grep Archsous Linux$env:PROCESSOR_ARCHITECTUREdans Power Shell sous Windows
Une question de taille
Comme s’il n’y avait pas déjà assez de soucis comme ça, sachez qu’il y a également au sein d’une même architecture différentes versions notamment liées à la taille des données que le processeur peut traiter directement.
Par exemple l’assembleur x86 d’Intel et AMD est une version 32 bits alors que la version x86_64 est une version 64 bits.
On appelle souvent l’architecture x86_64 : AMD64 (même s’il s’agit d’un processeur Intel)
Quelles est la différence entre de l’assembleur 32 bits et 64 bits ?
La principale différence est qu’un processeur va pouvoir directement traiter des données de 64 bits d’un coup, là où un processeur 32 bits va devoir traiter 32 bits par 32 bits.
En effet un processeur dispose de registres qui sont en quelque sorte de petites zones mémoire dans le processeur. Cela lui permet de faire certaines opérations (calculs, déplacement de valeurs, stockage …) sans avoir à passer par la RAM qui se situe plus loin, ce qui implique des performances moins élevées dans le cas où la mémoire serait utilisée.
L’avantage de ces registres est qu’ils permettent au processeur d’être plus performant. Leur principale inconvénient est qu’il n’y en a pas beaucoup, de l’ordre de la dizaine voire vingtaine.
Les constructeurs ne savaient pas réaliser des registres de 64 bits à l’époque, c’est pourquoi les anciens processeurs utilisent 32 bits alors que les plus récents utilisent 64 bits car leurs registres sont désormais de 64 bits.
C’est un peu comme la différence entre un moteur essence V8 et un moteur essence V12. Certes le carburant peut être plus ou moins le même mais les performances ne seront pas pareilles.
C’est pourquoi de nos jours nous avons des OS 64 bits et des applications 64 bits : c’est plus rapide 🚀 ! De plus, un OS 64 bits est rétrocompatible. Cela signifie qu’il pourra exécuter des programmes compilés en assembleur 32 bits. Evidemment l’inverse n’est pas possible.
Ainsi, les principales différences qu’il est possible de constater entre deux assembleurs de tailles différentes est la taille des registres utilisés.
Voici quelques exemples :
- Différences entre x86 (32 bits) et x86_64 (64 bits) :
- x86 :
1 2 3 4 5
push ebp mov ebp, esp xor eax, eax pop ebp ret
- x86_64 :
1 2 3 4 5
push rbp mov rbp, rsp xor rax, rax pop rbp ret
- x86 :
- Différences entre ARM 32 et ARM 64 :
- ARM 32 :
1 2 3 4 5 6 7
push {r7} add r7, sp, #0 movs r3, #0 mov r0, r3 mov sp, r7 ldr r7, [sp], #4 bx lr
- ARM 64 :
1 2
mov x0, 0 ret
- ARM 32 :
- Différences entre RISC-V 32 et RISC-V 64 :
- RISC-V 32 :
1 2 3 4 5 6 7 8
addi sp,sp,-16 sw s0,12(sp) addi s0,sp,16 li a5,0 mv a0,a5 lw s0,12(sp) addi sp,sp,16 jr ra
- RISC-V 64 :
1 2 3 4 5 6 7 8
addi sp,sp,-16 sd s0,8(sp) addi s0,sp,16 li a5,0 mv a0,a5 ld s0,8(sp) addi sp,sp,16 jr ra
Finalement, on remarque que les principales différences subsistent dans les noms des registres utilisés :
eax/rax,r0/x0où le registre de gauche est de 32 bits alors que celui de droite est de 64 bits.
- RISC-V 32 :
La version ARM 64 a effectivement effectué pas mal d’optimisations pour en arriver à limiter drastiquement le nombre d’instructions nécessaires pour une tâche donnée.
CISC vs RISC
Toutes ces architectures peuvent être classées en deux catégories :
- CISC (Complex Instruction Set Computer) : Microprocesseur à jeu d’instruction étendu. Cela signifie que le nombre d’octets pour représenter une instruction n’est pas fixe. Cela peut être 1 octets, 3 octets voire 15 octets
- RISC (Reduced Instruction Set Computer) : Microprocesseur à jeu d’instructions réduit. Cela signifie que le nombre d’octets pour représenter une instruction est fixe. Par exemple pour :
- ARM : 2 ou 4 octets
- RISC-V : 4, 8 ou 16 octets
Je ne comprends pas ce que veut dire “le nombre d’octets pour représenter une instruction”. C’est quoi la taille d’une instruction ? Le nombre de caractères dans
push rbppar exemple 🤔 ?
En fait, il faut que vous sachiez une chose. Quand on dit que l’assembleur est un langage machine ce n’est pas totalement vrai. En réalité, le processeur ne va pas exécuter une instruction qui lui dit de mettre la valeur 0 dans le registre eax avec mov eax, 0 : il ne sait ni ce qu’est mov, ni ce que l’on appelle eax.
Par contre, si le processeur reçoit les 5 octets suivants b8 00 00 00 00, eh bien il saura directement qu’il doit mettre la valeur 0 dans un certain registre (que nous appelons, nous humains, eax).
Vous vous demandez sûrement d’où sort cette suite de 5 octets. Je ne l’ai pas sortie de mon chapeau. En effet, le code d’opération de l’instruction mov eax, 0 est b8 00 00 00 00. Ces octets, c’est ce que l’on appelle les opcodes. Ce sont les données que le processeur va réellement exécuter. Vous vous souvenez, quand vous étiez petits, on vous disait “l’ordinateur ne comprend que les suites de 0 et de 1”.
Ça tombe bien ! b8 00 00 00 00 est la suite de 0 et de 1 suivante : 10111000 00000000 00000000 00000000 00000000. En tant qu’humain, on préfère évidemment que cela reste affiché en hexadécimal et même sous la forme mov eax, 0 🤗.

Pour revenir à la notion de RISC et CISC, prenons l’exemple d’une fonction main (qui ne fait que retourner 0) compilée pour x86_64 et ARM 32.
- x86_64 :

- ARM 32 :
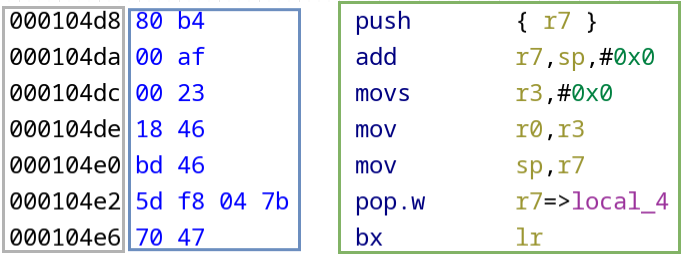
- ⚪ : adresses
- 🔵 : opcodes
- 🟢 : instructions
Ce qui est encadré en bleu représente les opcodes générés après compilation. Afin d’obtenir du code compréhensible pour un humain, une étape de désassemblage est réalisée. On obtient alors le code encadré en vert.
Le désassemblage est l’étape qui consiste à passer des opcodes aux instructions assembleur associées, compréhensibles par des humains.
Enfin, les adresses des instructions en mémoire sont encadrées en gris.
Finalement, ce que reçoit réellement un processeur n’est pas ce qui est encadré en vert mais plutôt ce qui l’est en bleu ! Ainsi, afin d’exécuter la fonction main, un processeur x86 exécutera la suite d’octets suivante : f3 0f 1e fa 55 48 89 e5 b8 00 00 00 00 5d c3.
On remarque également la différence entre le type CISC de x86 et RISC d’ARM : les instructions en ARM sont soit codées sur 2 ou 4 octets, ni plus ni moins alors qu’en x86, il n’y a, presque, pas de contraintes !
Le fait d’utiliser des tailles d’instructions qui varient dans les architectures CISC comme x86 permet d’utiliser des opcodes plus petits pour les instructions les plus courantes.
Par exemple, les instructions
push rbp,pop rbpetretsont présentes dans quasiment toutes les fonctions d’un programme C / C++. Elles sont donc représentées avec un opcode d’un seul octet, ce qui permet de réduire la taille du programme.En effet, une conséquence d’utiliser un jeu d’instruction réduit dans RISC est qu’il faudra plus d’instructions pour réaliser une tâche. Qui dit plus d’instructions dit plus d’opcodes et donc dit un programme (légèrement) plus volumineux.
C’est pourquoi dans les précédents exemples, ARM, MIPS et RISC-V semblaient plus verbeux.
Le boutisme
Le boutisme (ou endianness 🇬🇧) est une manière de représenter les données en mémoire. En fait, quand on se penche sur la question du stockage de données en mémoire, on fait rapidement face à un problème.
Le problème : J’ai l’entier de 4 octets (32 bits donc) suivant 0xaabbccdd que je souhaite stocker dans la zone mémoire suivante constituée seulement de 4 octets :
1
2
3
4
5
6
Mémoire :
[0] -> ?
[1] -> ?
[2] -> ?
[3] -> ?
La question que l’on peut légitimement se poser est : quel est l’indice 0 dans 0xaabbccdd, '0xaa' ou '0xdd' ?
En gros, par quel bout commence-t-on ? Par l’octet de poids fort 0xaa, de gauche à droite ? Ou l’octet de poids faible 0xdd de droite à gauche ?
Il y a ainsi deux manières de faire. Ceux qui ont répondu 0xaa à la précédente question vont stocker la string en mémoire de cette manière :
1
2
3
4
5
6
BE -> Big Endian
[0] -> 0xaa
[1] -> 0xbb
[2] -> 0xcc
[3] -> 0xdd
La seconde manière, pour ceux qui ont répondu 0xdd est :
1
2
3
4
5
6
LE -> Little Endian
[0] -> 0xdd
[1] -> 0xcc
[2] -> 0xbb
[3] -> 0xaa
La première méthode est le Big Endian (Grand Boutiste 🇫🇷) abrégé en BE. La seconde méthode est le Little Endian (Petit Boutiste 🇫🇷) abrégé en LE.
Il faut savoir que c’est le Little Endian qui est le plus utilisé (en ARM, x86, MIPSel, …) bien que la valeur affichée en mémoire semble être “à l’envers” contrairement au Big Endian.
Alors là, je suis perdu !
On parlait d’assembleur il y a quelques instants et d’un coup, on parle de big indien et petit bouddhiste 🤨
Vous en faites pas, c’est normal si vous n’êtes pas encore totalement à l’aise avec le boutisme ! Il s’agit d’une notion qu’il faut garder dans un coin de la tête afin de ne pas s’étonner que certaines valeurs soient stockées “à l’envers” en mémoire.
C’est à force d’utiliser un debugger et de décortiquer la mémoire d’un programme que l’on s’y habitue petit à petit.
Résumé de chaque architecture
Après avoir réalisé ces différentes comparaisons, voici un petit résumé des spécificités et différences entre les différentes architectures.
x86
- Principales évolutions : x86 (version 32 bits), x87 (permet le calcul en virgule flottante) et x86_64 (version 64 bits)
- Jeu d’instructions : CISC
- Taille des opcodes : Variable. De 1 à 15 octets
- Boutisme : Little Endian (LE)
- Spécificités : Utilisé par Intel et AMD
- Noms des principaux registres : En version 32 bits :
eax,ebx,ecx,edx,edi,esi,eip,esp,ebp… Remplacer leedu début du nom du registre par unrpour avoir la version 64 bits (ex :rax) - Utilisé dans : la majorité des PC, serveurs et stations de travail
ARM
- Principales évolutions : ARMv1 à ARMv7 (versions 32 bits) puis ARMv8 (versions 64 bits)
- Jeu d’instructions : RISC
- Taille des opcodes : 2 ou 4 octets
- Boutisme : Little Endian (LE)
- Spécificités : Un mode “Thumb” qui peut être activé et désactivé à tout moment. Il s’agit d’un mode qui utilise des instructions de plus petite taille (2 octets). Il est initialement utilisé pour des appareils dont l’espace mémoire est limité (ex: IoT).
- Noms des principaux registres : En version 32 bits :
r0,r1,r2,r3,sp,lr,pc… Remplacer lerde début des noms de registres parxpour avoir la version 64 bits - Utilisé dans : les smartphones, tablettes, IoT, Macbook, iMac …
MIPS
- Principales évolutions : MIPS I à MIPS V, MIPS32, MIPS64 …
- Jeu d’instructions : RISC
- Taille des opcodes : 4 octets
- Boutisme : MIPSel Little Endian (LE) ou Big Endian (BE)
- Noms des principaux registres : 1.
$zero,$at,$v0-$v1,$a0-$a3,$t0-$t9,$s0-$s7,$t8-$t9,$k0-$k1,$gp,$sp,$fp - Utilisé dans : Consoles (Playstation 1 et 2, Nintendo 64 …), routeurs, systèmes embarqués
- Spécificités : Branch delay: les instructions de sauts sont exécutées avec l’instruction située immédiatement après (en-dessous) du saut.
Par exemple, si on se situe dans une zone de code A et qu’il y a un saut vers une zone de code B, en ARM ou x86, lorsque le saut est effectué, la prochaine instruction exécutée est dans la zone B.
Tandis qu’en MIPS, sachant qu’il y a une sorte de “retard” lors d’un saut, la prochaine instruction exécutée après le saut est celle qui était en dessous de l’instruction de saut dans la zone A.
Prenons l’exemple suivant (même si on ne sait pas ce que fait chacune de ces instructions) :
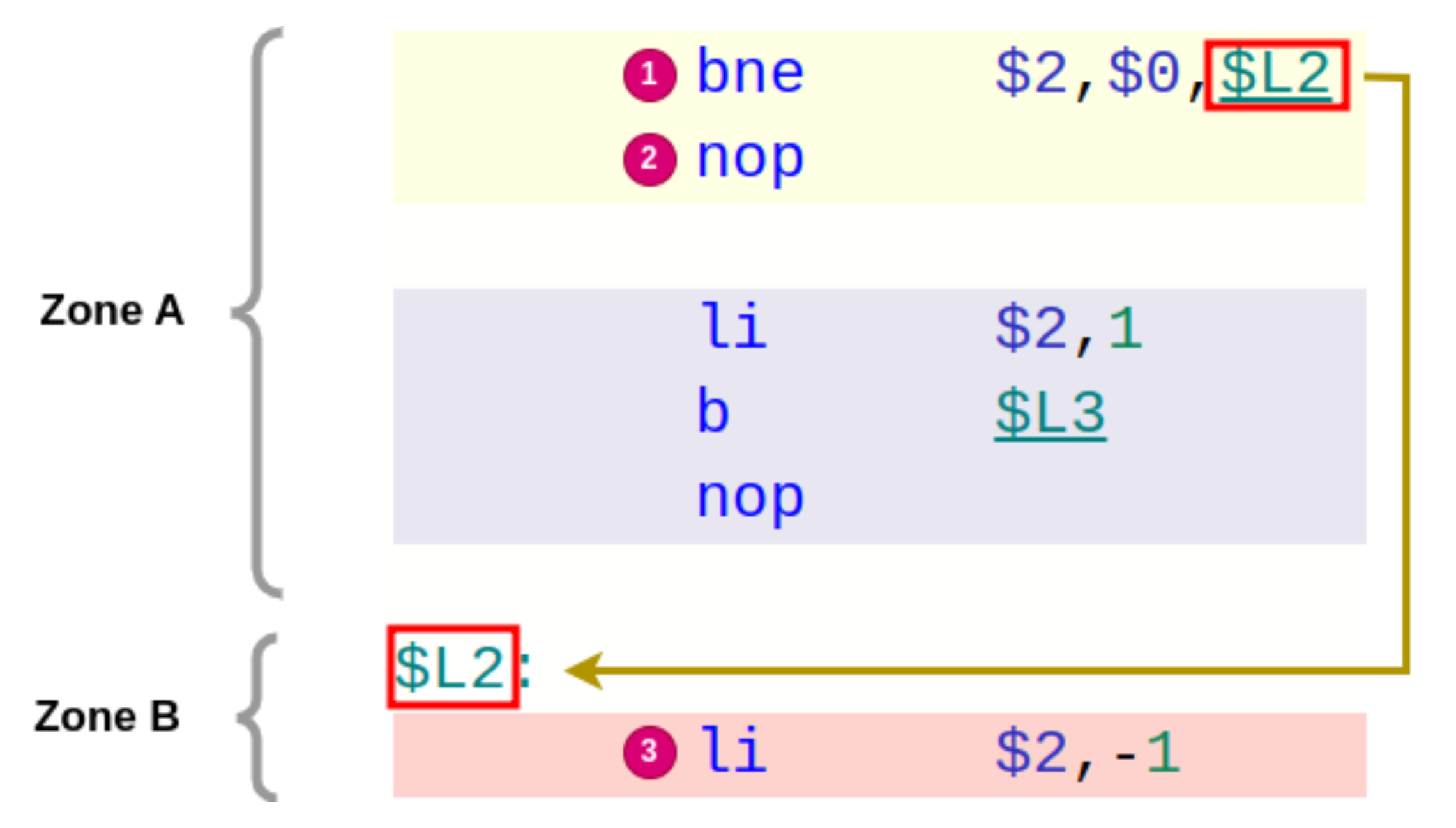
Dans cet exemple, lors du saut (ou branchement) bne, l’instruction nop est exécutée avant li. Alors que dans les autres architectures (ARM, x86 …), les instructions exécutées seraient tout simplement bne puis li.
Pour résumer, en MIPS, à chaque fois qu’un branchement est réalisé, l’instruction située immédiatement après l’instruction de saut est d’abord exécutée avant l’instruction “de destination”.
RISC-V
- Jeu d’instructions : RISC (merci Sherlock 🕵️♂️ !)
- Taille des opcodes : 4, 8 ou 16 octets
- Boutisme : Little Endian (LE)
- Spécificités : Open source. Assez récent (2014).
- Noms des principaux registres :
x0-x31 - Utilisé dans : de plus en plus d’appareils même si la part du marché représentée est, à ce jour, encore très faible face à ARM ou x86
📋 Synthèse
- L’assembleur est le langage le plus bas niveau permettant de donner des instructions au processeur afin qu’il les exécute
- Il existe plusieurs assembleurs (ou architectures) en fonction du processeur utilisé
- Plusieurs évolutions ont eu lieu dont l’augmentation de tailles des données manipulées (32, 64 bits …)
- Le processeur n’exécute “réellement” que les opcodes qui sont des valeurs souvent représentées en hexadécimal
- La taille des opcodes peut être fixe (RISC) ou variable (CISC)
- Il existe différentes manières de représenter des données en mémoire, en commençant par l’octet de poids faible, c’est le Little Endian, le plus utilisé. Ou en commençant par l’octet de poids fort, c’est le Big Endian.