Partie 3 - Le fonctionnement d'un programme - (2/2)
Le fonctionnement d’un programme - (2/2)
Avant de nous attaquer à du reverse à proprement parler, il est nécessaire de bien comprendre de quoi est composé un programme et comment est représenté un processus en mémoire. Il y a plusieurs formats d’exécutables en fonction de l’OS que vous utilisez :
- ELF pour les distributions Linux
- Mach-O pour Mac OS (merci Sherlock 🕵️♂️) dont l’extension est souvent
.dmg - PE pour Windows dont l’extension est souvent
.exeou.dll
Je vous propose de nous intéresser au format ELF dans un premier temps. Il est plus accessible que le format PE bien que la logique derrière est similaire.
Un programme, des processus
Lorsqu’un programme est exécuté par l’OS, il devient ce que l’on appelle : un processus. C’est-à-dire que c’est un programme exécuté en mémoire. Pour bien comprendre la différence entre programme et processus je vous propose de réaliser une petit expérience ensemble.
Tout d’abord il faut que xclock soit installé sur votre machine. Si ce n’est pas le cas, vous pouvez l’installer via le paquet x11-apps. Sous une distro Debian-like : sudo apt install x11-apps.
Ensuite ouvrez un terminal et saisissez la commande suivante : xclock -bg blue&;xclock -bg white&;xclock -bg red&;. Cela va lancer en arrière-plan 3 instances (processus) du programme xclock avec des couleurs différentes.
Vous devriez obtenir quelque chose semblable à cela :
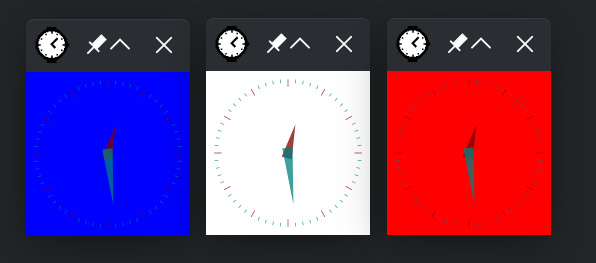
A ce stade là, ces 3 processus xclock tournent en mémoire. Maintenant, que se passe-t-il si on tente de supprimer le programme xclock ?
Pour cela, il faut d’abord trouver où il est installé avec which xclock. Par exemple /usr/bin/xclock. Ensuite, avant de supprimer le programme, faisons tout de même un copie avec cp /usr/bin/xclock /tmp/copie_de_xlcock.
Une fois que la copie est faite, supprimons le programme avec sudo rm /usr/bin/xclock. Maintenant pour vérifier que le programme a bien été supprimé, lançons xclock dans un terminal et là, on obtient l’erreur command not found: xclock.
Mais pourquoi les 3 instances de
xclocksont toujours en cours d’exécution alors que l’on a supprimé le programme ?
Justement ! Nous avons supprimé le programme qui était présent dans notre disque. Mais cela n’affecte pas les processus qui eux, sont exécutés indépendamment en mémoire. D’ailleurs si vous fermez un des trois processus, cela ne fermera pas les autres qui continueront de fonctionner.
Cela signifie donc que les instructions exécutées par le processeur lorsqu’un processus est lancé sont situées en mémoire.
N’oubliez pas de restaurer la copie de
xclockavecsudo cp /tmp/copie_de_xlcock /usr/bin/xclock
Le format ELF

Maintenant que l’on sait qu’un processus est totalement exécuté en mémoire, intéressons-nous aux différentes parties qui constituent un programme une fois exécuté en mémoire.
Evidemment, le format ELF doit permettre à la fois de contenir les instructions du programme compilé (les fonctions, variables …) mais aussi la manière dont doit être chargé le programme en mémoire afin qu’il devienne un processus : quelles bibliothèques sont à charger ? Comment doit être agencé le processus en mémoire ? …
Dans cette partie, on utilisera le terme ELF pour parler du programme compilé et vice versa.
Ainsi, le format ELF est constitué des principales parties suivantes :
- Un entête ELF : commence par les magic bytes
.ELFet qui contient les informations générales du programme sur l’architecture (32 ou 64 bits, compilé pour Intel ou ARM …) - Program header table : cette partie liste les segments du programmes
- Section header table : cette partie liste les sections du programmes
- Le reste : contient les instructions, les données …
Nous allons ci-dessous ce qu’est un segment et un section.
Concernant l’entête ELF, c’est ce que l’on voit quand on affiche les premiers octets du programme. Allez avouez, on a tous déjà essayé d’afficher un programme en faisant cat programme en pensant pouvoir directement lire le code avant de tomber sur un truc du genre :
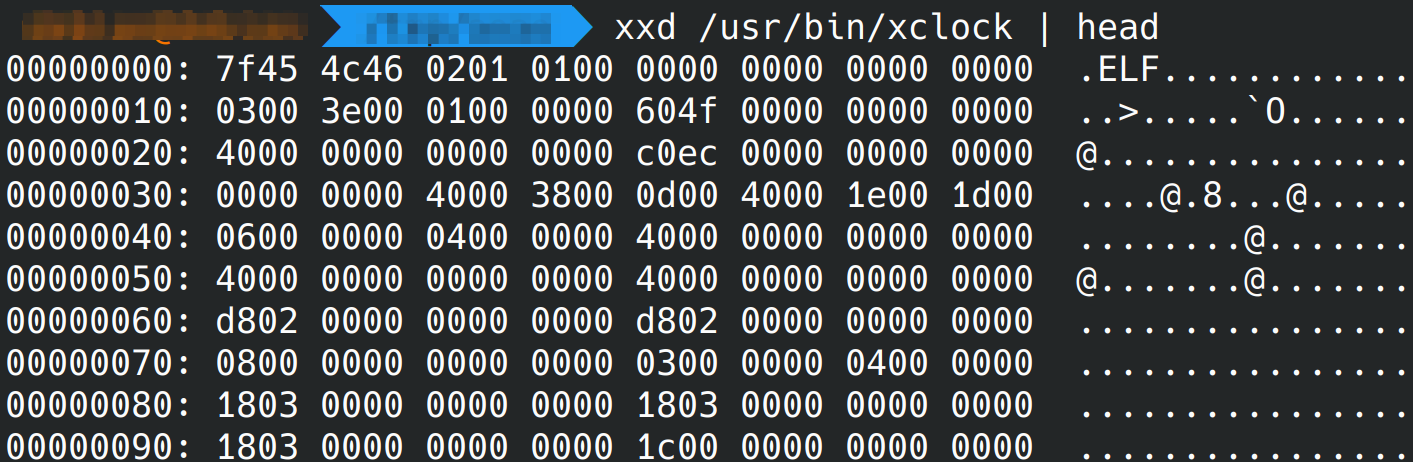
Les segments et sections
Désormais, voyons ce que sont les segments et sections. Je vous avoue qu’en commençant le reverse, je me suis arraché les cheveux car je n’arrivais pas à comprendre la différence entre les deux.
TL-DR : Un segment est une zone mémoire qui contient plusieurs sections qui ont les mêmes attributs (ex : Lecture seule, exécutable …)

En fait, en termes de processus, ce qui nous intéresse ce sont principalement les segments car les sections n’ont plus réellement d’utilité une fois que le programme est exécuté. Les sections ont du sens au moment où l’OS va devoir allouer les différentes zones mémoires du processus.
Par exemple, toutes les sections qui contiennent des instructions doivent bien au moins avoir les attributs de lecture et exécution, non ? De cette manière, la section d’initialisation .init, celle qui contient le code .text (celui de la fonction main et des autres) et la section de fin .fini seront dans un même segment qui aura les droits RX.
De la même manière, les sections qui contiennent des données modifiables telles que .bss (données initialisées à 0) et .data (données initialisés et modifiables. Ex : les variables globales, statiques …) seront dans un segment ayant les droits RW.
Par contre, la section .rodata qui ne contient que des données non modifiables (comme la string Hello world !\n ) sera dans un autre segment qui aura seulement l’attribut R.
Il y a plein d’autres sections dont je ne vais pas vous parler car elles ne sont pas forcément les plus intéressantes en reverse mais peuvent l’être pour de l’exploitation de binaires telles que .plt,.plt.got,.got etc.
Pour afficher les différents segments d’un programme ELF, on peut utiliser la commande readelf -l programme.
Vous pouvez faire un simple programme “Hello world” et le compiler afin de pouvoir lire les informations via
readelf.Si vous avez la flemme, vous pouvez tout simplement utiliser
readelfsur les programmes de base de votre distro commecat,lsetc. car ce sont aussi des fichiers ELF 😉.
Le nom des différents segments ne nous intéresse pas plus que ça. En fait ce sont surtout les segments suivants qui sont importants pour nous (ainsi que les sections qu’ils comportent) :

- le segment 🔴 contient du code exécutable et doit donc avoir les attributs de lecture et d’exécution
- le segment 🟣 contient des données qui ne sont qu’en lecture seule ( comme des chaînes de caractères qui n’ont pas besoin d’être modifiées)
- le segment 🟢 contient des données modifiables mais n’ayant pas besoin d’être exécutées : cette zone mémoire n’aura besoin que des droits de lecture et écriture
- le segment 🔵 contient la section
.dynamicet contiendra, comme son nom l’indique, les données allouées dynamiquement. Comme les allocations réalisées parmalloc. C’est ce que l’on appelle le tas (ou heap). - Le segment 🟡 contient la pile d’exécution appelée stack. C’est une zone mémoire qui contiendra notamment les variables locales et qui fonctionne, comme son nom l’indique, sous forme de pile : Premier arrivé, dernier servi.
La heap est désignées par “tas” en français mais cela n’a rien à voir avec la structure de données nommée tas. On l’appelle tas car il y a un tas de choses dedans allouées dynamiquement et qui sont souvent hétérogènes.
Mais comment savoir de quels attributs dispose un segment ?
Il y a différentes manière d’avoir cette information. La première est d’utiliser la commande précédente readelf -l programme. La première partie affichée est le nom des segments avec leurs attributs (E pour Execute au lieu de X). Nous verrons l’autre manière un peu plus tard via un débogueur.
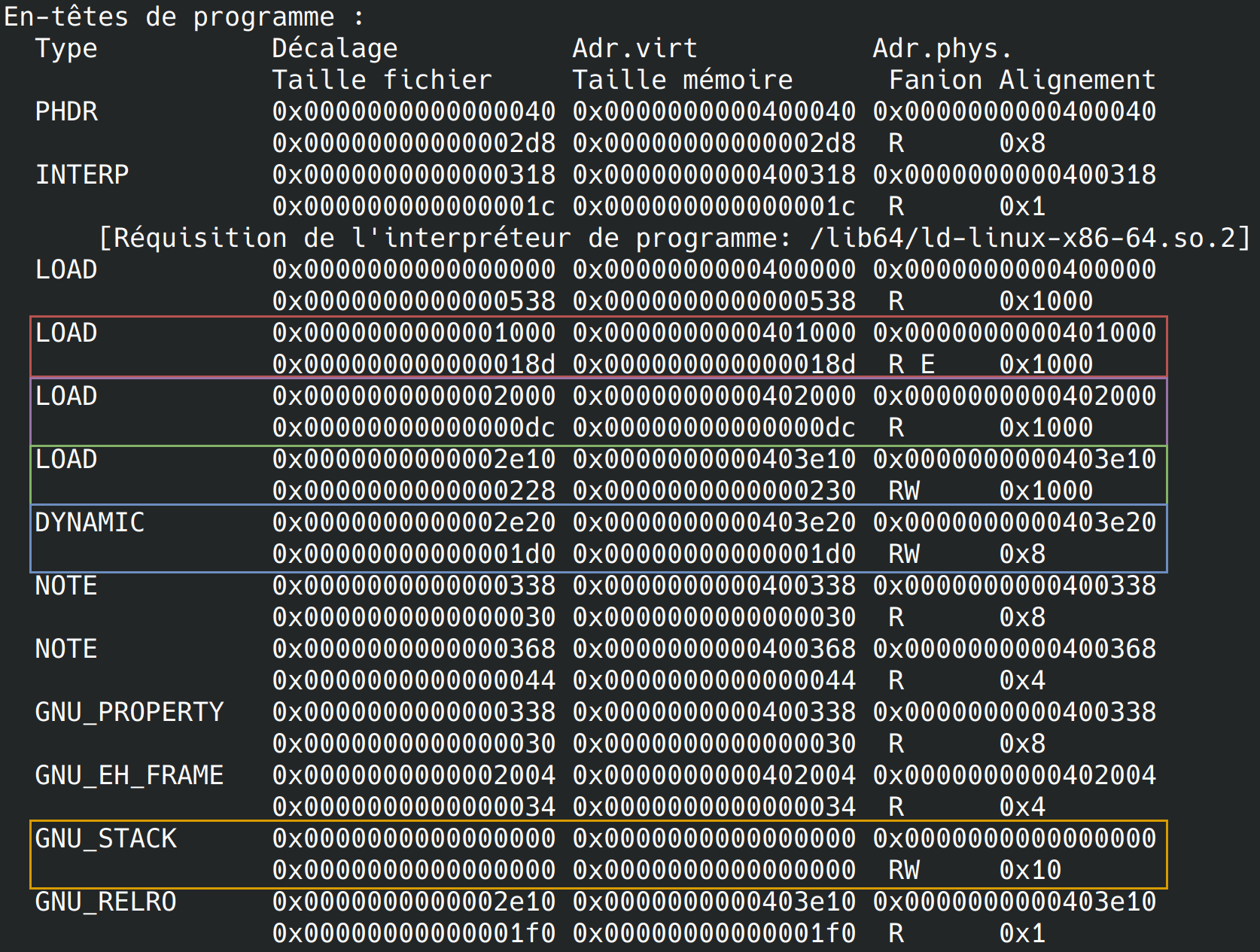
Agencement en mémoire
Bon j’avoue que ce sont pas mal d’informations qui ne sont pas forcément évidentes. Tous les détails ne sont pas cruciaux mais s’il y a une chose à retenir c’est la tête qu’a l’agencement final du processus une fois le programme en mémoire :
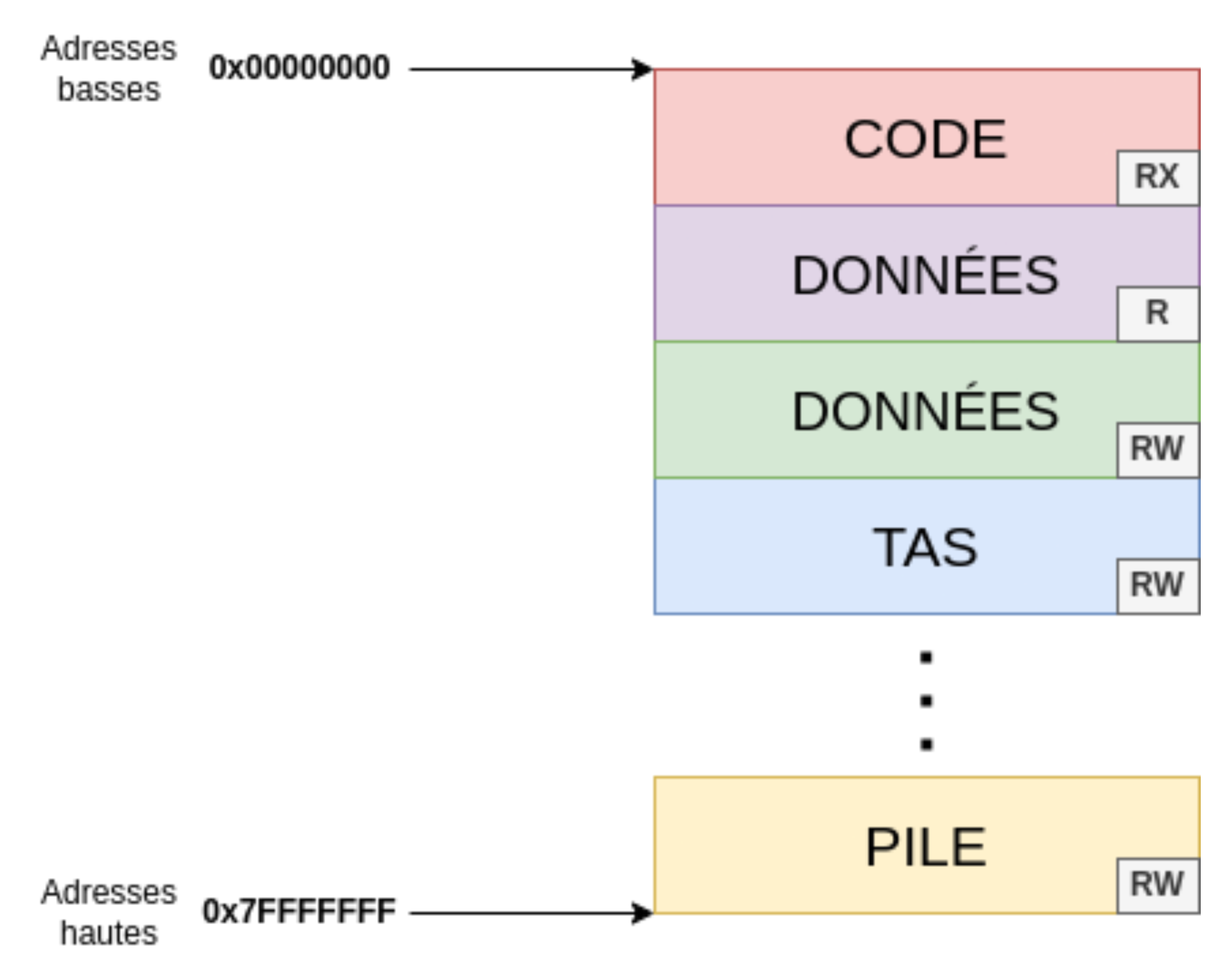
Etant donné que le tas est dédié à l’allocation dynamique de données, c’est un segment que l’on ne voit pas dans le programme tant qu’il n’est pas exécuté car cette zone mémoire est créée dynamiquement au lancement du programme.
Il en est de même pour la pile qui est une zone mémoire allouée lors du lancement du programme.
Ici l’adresse la plus basse
0x00000000a été mise tout en haut mais cela ne signifie pas qu’un processus est chargé à cette adresse. C’est d’ailleurs jamais le cas.L’adresse
0x00000000sur ce schéma permet juste de garder en tête que l’on représente les adresses basses vers le haut et les adresses hautes vers le bas.De la même manière, la pile d’exécution n’atteint pas l’adresse
0x7fffffff.
Voilà ! Vous savez désormais comment est agencé un processus en mémoire 😎. En effet, tout le processus est présent entre les zone mémoire 0x00000000 et 0x7FFFFFFF (sans pour autant remplir tout cet intervalle)
T’es sérieux ! Tu aurais pu juste nous résumer ça avec ce schéma au lieu de nous raconter tout ce charabia 🤯 !
En fait, bien que toutes les informations précédentes ne soient pas indispensables, il est tout de même nécessaire de savoir de quoi il s’agit quand on vous parle de .text ou .data, de la pile ou du tas par exemple.
Et pourquoi les adresses basses sont en haut au lieu d’être en bas 😓 ?!
Alors c’est l’une des choses les plus déroutantes en reverse ( voire informatique ) mais les adresses basses sont situés en haut alors que les adresse hautes en bas 😵💫. C’est une convention et je vous avoue que je ne sais pas pourquoi ni comment on en est arrivé là 😅.
Au début pour s’y faire, c’est un peu fastidieux, mais à force de faire du reverse vous allez finir par vous y habituer. Promis !
Liens avec la programmation
Ce que l’on a raconté ci-dessus peut vous paraître totalement abstrait alors essayons de voir quel lien il peut y avoir entre chaque zone mémoire et les divers éléments en programmation. Ainsi, voici ce que chaque segment contient :
- Dans la zone de code 🔴 ➡️ les instructions des différentes fonctions dont le
main - Dans la zone des données en lecture seule 🟣 ➡️ les données non modifiables telles que les chaînes de caractères présentes en tant qu’arguments pour les fonctions
puts,printf… Exemple :Hello world!\n - Dans la zone des données modifiables 🟢 ➡️ les variables globales (déclarées en dehors de toute fonction), les variables statiques (déclarée avec le mot clé
static) commestatic int var;… - Dans le tas 🔵 ➡️ les variables allouées dynamiquement avec
malloc(en C) ounew(en C++). Ce sont des variables dont on ne connaît pas la taille avant l’exécution du programme tel que le nom de l’utilisateur. Exemple :char *username = malloc(n); - Dans la pile 🟡 ➡️ les variables locales, c’est-à-dire la majorité des variables que l’on utilise. Il s’agit de celles qui ne sont pas allouées dynamiquement et sont déclarées au sein des fonctions sans le mot clé
static. Exemple :int a; int b = 0x213;…
Vous comprenez désormais pourquoi il est important de savoir distinguer ces différentes zones mémoire ? En fait elles contiennent chacune un certain type d’éléments issu de la programmation.
Ainsi, lors d’une analyse d’un programme, cela ne sert à rien de chercher du code dans la section de données ou tenter de modifier la valeur d’une variable globale depuis la section de code.
Autres formats
Nous n’allons pas nous attarder sur les détails des autres formats car si vous avez bien compris le principe du format ELF et que vous avez en tête le schéma de la représentation d’un processus en mémoire, vous ne devriez pas avoir de soucis avec le format PE (Windows) ni Mach-O (Mac OS).
Voici le format d’un programme PE :

Sous Windows, on parle de section plutôt que de segment pour désigner une zone mémoire de code, données etc.
Vous pouvez utilisez le package python
readpepour décortiquer le format PE. Si vous souhaitez une interface graphique, vous pouvez utiliser pe-bear.
Et celui d’un programme Mach-O :

Comme vous pouvez le constater, le principe général de ces formats est le même :
- Un entête propre à chaque OS
- La liste des segments
- Enfin, les segments avec leurs différentes sections
On remarque également qu’une certaine logique est présente dans les 3 formats : la zone mémoire de code est placée avant la zone mémoire de données. De cette manière vous ne devriez pas trop être dépaysés si vous basculez d’un format à un autre.
A partir de maintenant, si on utilise le terme section c’est pour parler d’une zone mémoire de manière générale, pas forcément en termes de “section ELF” ou “section PE”…