Partie 2 - Le fonctionnement d'un programme - (1/2)
Le fonctionnement d’un programme - (1/2)
Préambule
Il existe différentes manières d’apprendre le reverse :
- Certains préconisent de commencer par l’assembleur (langage machine) afin de comprendre en détail comment cela fonctionne
- D’autres préfèrent allier théorie à pratique en analysant des exemples de programmes compilés et voir ce que cela produit en termes d’assembleur
En ce qui nous concerne, nous allons à la fois combiner la théorie et la pratique mais sans commencer directement par l’assembleur, ce serait beaucoup trop traumatisant 😅 !
En fait, nous aimerions que ce cours soit tel que l’on aurait aimé qu’il soit quand on a commencé le reverse. Voici les principaux inconvénients des cours les plus connus :
- principalement en anglais
- beaucoup trop de théorie 😴
- beaucoup trop de détails dans l’assembleur (exemple : les différences entre les compilateurs dans différentes architectures 🤯)
- parfois : manque de pédagogie
Evidemment, ce cours n’a pas la prétention de combler tous ces inconvénients ( qui, pour certains, n’en sont peut être pas). L’idée est simplement de proposer quelque chose de différent de ce qui a été réalisé jusqu’à présent.
Peut être que certains sont férus de théorie auquel cas le fameux cours de reverse de Dennis Yurichev leur conviendra très bien.
Rendons à César ce qui est à César
La pédagogie déployée dans ce cours, et plus généralement sur ce site, est très inspirée du Site du Zéro (désormais Openclassrooms). Vous faites peut être également partie de cette génération qui a appris à coder sur ce site. Personnellement, c’est mon cas et j’ai trouvé que la manière dont étaient présentées les choses était simple, efficace et concise.
On espère que ce cours sera donc agréable à lire et facile à comprendre !
Je ne suis pas forcément pour ou contre l’anglicisme tout azimuts mais, à défaut d’avoir trouvé un mot plus simple en français que “reverser” pour dire “analyser et comprendre un programme compilé”, on utilisera ce terme à l’avenir 😄.
Si vous avez des suggestions, je suis preneur !
Qu’est-ce qu’un programme ?
Normalement, si vous avez suivi les prérequis avant d’entamer ce cours, vous devriez savoir ce qu’est un programme : un bout de code transformé en un fichier exécutable par l’ordinateur.
C’est un bon début, mais évidemment cette définition n’est pas assez précise. Essayons l’affiner. Tout d’abord, voyons les principales étapes permettant d’obtenir un programme à partir de code :
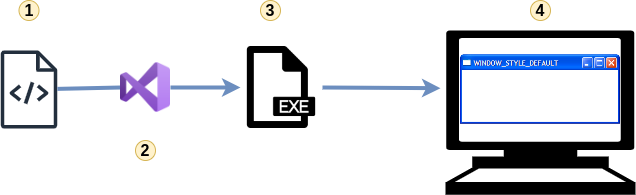
- Le développeur écrit le code qui devra s’exécuter (par exemple dans un fichier
main.c) - Une fois le développement terminé, il utilise un compilateur (Visual Studio, gcc, clang …) afin de produire un programme (par exemple
main.exe) - Enfin l’utilisateur double-clique sur l’exécutable afin de le lancer, il voit alors le résultat à l’écran de l’exécution du programme
Il y a évidemment pas mal d’étapes sous-jacentes qui ne sont pas citées (édition des liens, chargement dynamique des bibliothèques etc.) mais cela nous permet d’avoir un aperçu global pour mieux nous y intéresser en détail. Vous l’aurez compris, le rôle d’un reverser est de retrouver ce qui a été fait à l’étape 1 à partir des étapes 3 et 4.
L’étape 4 ne représente pas un programme à proprement parler mais plutôt un processus en cours d’exécution en mémoire. Il y a pas mal de différences entre un processus (étape 4) et un programme (étape 3) que nous verrons ultérieurement.
Etape 1️⃣ : La programmation
La première étape pour réaliser un programme est de … programmer (Merci Sherlock 🕵️♂️) !

Dans un programme, indépendamment du langage utilisé, on retrouve souvent les mêmes notions utilisées :
- les variables : ce sont des zones mémoires où seront stockées des données
- les fonctions : des bouts de code qui peuvent être appelés plusieurs fois
- les instructions de contrôle :
if,else,while,switchqui permettent d’exécuter du code de manière conditionnelle ou en bouclant dessus - les commentaires : osef en reverse de toute façon le compilateur ne les lit même pas 🥵
- les objets et structures : ce sont en quelque sorte des “super” variables
Chacun de ces éléments va être modélisé d’une certaine manière dans le programme final. Nous aurons le temps de voir comme tout cela est représenté dans un programme.
Langage interprété vs langage compilé
Langage interprété
Un code dont le langage est interprété (Python, PHP, Bash …) sera lu ligne par ligne par l’interpréteur. Cela signifie que l’interpréteur ne sait pas à l’avance tout ce qu’il est possible d’exécuter avec un tel code et si tout le code est correct.
C’est pourquoi en Python, tant que certaines fonctions ne sont pas appelées, on ne peut pas détecter certaines erreurs qu’elles contiennent.
Les programmes développés dans un langage interprété sont :
- souvent plus lents que les programmes compilés 🚜
- plus facilement utilisable car il suffit de disposer d’un interpréteur sur sa machine
- en termes de reverse, on peut accéder au code source (sous forme de script) plus facilement
Langage compilé
Les programmes développés en langage compilé (C, C++, Java, Kotlin …) sont quant à eux lus dans leur entièreté, qu’un bout de code soit appelé ou non. C’est pourquoi le compilateur risque de plus râler qu’un interpréteur : il a besoin que tout soit bien fonctionnel afin de générer l’exécutable final.
Cette manière de réaliser un exécutable implique plusieurs choses :
- un programme développé en langage compilé est souvent plus rapide qu’un langage interprété 🏎️
- moins accessibles car il faut généralement recompiler le programme pour chaque OS de destination ( distro Linux, Mac OS, Windows …)
- en termes de reverse, on perd pas mal d’informations lorsque l’on compile un programme (noms des fonctions, structures, objets, énumérations …), c’est donc plus complexe à analyser ( mais pas impossible 😄)
C’est d’ailleurs pourquoi vous avez généralement un makefile dans les projets GitHub développés en C, C++ etc. Cela vous permet de compiler le programme avec votre machine qui s’adapte à votre environnement. Ces projets ne sont donc pas utilisables tel quel car il est nécessaire de passer par l’étape de compilation.
Tandis que lorsque vous trouvez un projet GitHub développé en Python, vous pouvez directement l’utiliser via python script.py. Concernant l’aspect “reverse” des choses, quand on travaille dans le domaine de la rétro-ingénierie, on fait principalement face à des programmes compilés plutôt que des scripts (auquel cas cela reviendrait plus à faire de l’analyse de code).
De plus, sachant que nous sommes dans un cours de reverse, je vous propose de nous focaliser principalement sur les programmes compilés.
Etape 2️⃣ : La compilation
Nous n’allons pas nous intéresser à la manière dont est développé un compilateur et comment il fonctionne en détails, mais nous avons besoin de comprendre certaines notions avant d’aller plus loin.
Mais à quoi sert exactement un compilateur ? Pourquoi en ai-je besoin pour pouvoir lancer mes programmes développés en C, C++ etc. ?
Vous vous rappelez de l’analogie du reverse et de la cuisine ? En fait, la compilation correspondrait au fait de faire cuire le gâteau (compilation) dans le four (compilateur). En effet, tant que l’on ne cuit pas le gâteau, on ne pourra pas en manger 😋.
En fait, un code source C, C++ ou Rust n’est pas exécutable directement par l’ordinateur. Il faut lui mâcher le travail pour qu’il ait du code qu’il peut comprendre plus facilement : c’est l’assembleur.
Prenons par exemple le programme C suivant qui devrait parler à tout le monde :
1
2
3
4
5
6
#include "stdio.h"
int main()
{
puts("Hello world!\n");
}
Après compilation, la fonction main sera représentée par le code assembleur suivant :

Mais qu’est-ce que c’est ce truc encore, c’est immonde 😵💫 !
Si vous ne comprenez absolument rien au code assembleur, c’est tout à fait normal ! Nous y reviendrons plus tard, promis !
Bien que ce code assembleur ne soit pas destiné à être très compréhensible pour un humain, le processeur lui, il sait exactement ce que cela représente et saura l’exécuter sans aucun soucis 😎.
En fait, il faut voir le compilateur comme un traducteur d’un langage (exemple le C) vers un autre (par exemple de l’assembleur). Comme le processeur impose le langage machine utilisé, et bien en reverse on a pas tellement le choix, il est nécessaire de comprendre l’assembleur si on souhaite comprendre comment fonctionne un programme (même si j’avoue qu’il aurait pu faire un effort pour nous comprendre depuis le temps que l’on se connaît 😞) .
C’est d’ailleurs pourquoi les programmes compilés sont plus rapides : le processeur sait déjà quoi exécuter et comment le faire. Pas besoin de plus d’étapes intermédiaires.
Bien évidemment, tout le code source va être traité de cette manière. Ainsi, au final, toutes les fonctions, variables etc. seront transformées en code assembleur.
🚩 Résultat : Un programme exécutable
Une fois que l’étape de compilation est terminée, on obtient enfin le programme exécutable que l’on peut lancer en double cliquant dessus ou via ligne de commande ./mon_programme.
En fait, il faut savoir que le compilateur ne fait pas que traduire le code en langage machine. En effet, pour obtenir un programme qui puisse être exécuté correctement, il est nécessaire de bien structurer ce dernier.
De la même manière, quand vous mangez un gâteau, vous ne mangez pas d’abord tout le chocolat, puis les œufs, puis la farine etc. Pour un programme, c’est pareil, il faut bien le structurer pour que chaque chose ( et nous verrons quelles sont ces choses ) soit à sa place. Le processeur ne peut pas exécuter juste linéairement un programme, il a besoin que plusieurs zones mémoires soient agencées correctement.
Mais quelles sont ces différentes zones qui constituent un programme ?
Ça tombe bien c’est ce que nous allons voir de suite !