Partie 17 - Les programmes 64 bits
Les programmes 64 bits

Bon, c’est vrai que ça fait déjà pas mal de chapitres que l’on a faits ensemble, il est enfin temps d’en toucher quelques mots.
Les principales différences
Premièrement, voyons sont les principales différences entre un programme 32 bits (x86) et un programme 64 bits (dit x86_64, amd64 ou x64) :
- Il y a plus de registres :
- x86 :
eax,ebx,ecx,edx,esp,ebp,esi,edi,eip… - x86_64 :
rax,rbx,rcx,rdx,rsp,rbp,rsi,rdi,rip,r8,r9,r10,r11,r12,r13,r14,r15…
- x86 :
- La taille des registres en 64 bits est de … 64 bits (merci Sherlock 🕵️♂️). Les registres peuvent donc désormais contenir un
qword. - La taille des registres ayant augmenté, il est possible d’accéder à un espace mémoire bien plus élevé :
- x86 : 4Go (~ 4⁹ octets)
- x86_64 : 16Eo (~ 18¹⁸ octets 🥵)
- Les conventions d’appel sont différentes vu qu’en x86_64 il y a plus de registres disponibles :
- x86 : les arguments sont principalement passés via la pile
- x86_64 : les arguments sont principalement passés par les registres
- En raison de tailles de registres plus importantes, les programmes 64 bits sont souvent plus rapides que les programmes 32 bits.
- De nouvelles instructions ont été introduites en x86_64 telles que
movabsousyscall.
🤙 Les conventions d’appel
Les conventions de quoi 😳 ?
Les conventions d’appel sont les règles qui régissent les appels et retour de fonction. Elles stipulent notamment la manière dont les arguments sont passés (ex : par la pile).
Elle permet également de stipuler qui est en charge de “vider” la pile lorsqu’une fonction a fini son exécution : est-ce à la fonction appelante ou appelée de faire cela ?
⤴️ La valeur de retour
Commençons par le plus simple : où est stockée la valeur de retour ? C’est plutôt clair :
- x86 : la valeur de retour est stockée dans
eax - x86_64 : la valeur de retour est stockée dans
rax
Voilà 🤓 !
Le passage des arguments
En ce qui concerne le passage des arguments, cela s’opère différemment. En effet, le fait d’utiliser la pile s’est avéré utile car la logique derrière n’était pas très compliquée : on empile les arguments un à un et la fonction appelée sait exactement où les trouver (pour rappel : en dessous de l’adresse de retour).
Néanmoins le soucis d’utiliser le pile est que … celle-ci se trouve en mémoire. Cela signifie qu’à chaque fois que l’on souhaite appeler une fonction il faut :
- empiler les arguments, et donc écrire en mémoire
- récupérer les arguments, et donc lire en mémoire
Or, comme vous le savez, les accès mémoire pour le processeur sont bien plus lents que les accès aux registres situés dans le processeur. Ainsi, les nouvelles conventions d’appel 64 bits sont venues proposer une manière plus efficace de passer les arguments, tout simplement : utiliser les registres.
Cependant, il n’existe pas une seule manière de transmettre des arguments via des registres : cela dépend de l’architecture et du niveau de privilège (user land / kernel land).
Pour faire simple, la mémoire virtuelle d’un ordinateur est séparée en deux parties : le user land et le kernel land.
Le user land contient tous les processus “basiques” que l’on utilise tous les jours : le navigateur, vos programmes compilés, votre éditeur de texte …
Le kernel land, quant à lui, contient tous les processus nécessitant une exécution avec un niveau de privilège élevé. Cela inclut donc tous les programmes réalisant des actions sensibles comme la gestion de la mémoire, la lecture et écriture dans votre disque dur / ssd etc. De tels programmes sont appelés pilotes, drivers (Windows) ou modules kernel (Linux).
Evidemment, le kernel land contient également le noyau (kernel) de votre OS étant donné le niveau de privilège élevé requis d’un grand nombre d’actions réalisées par ce dernier.
Au sein d’une même architecture, il peut y avoir plusieurs conventions d’appel, c’est pour cela qu’elles ont un nom : cdecl, stdcall, fastcall. On comprend enfin ce que signifient ces mots clés dans IDA :
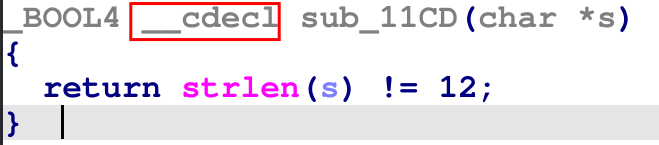
Les noms de ces conventions d’appel nous permettent de savoir, sans regarder l’assembleur, comment les arguments sont passés.
Listons ci-dessous les principales conventions d’appel.
Les registres sont affichés dans l’ordre des arguments : le premier registre correspond au premier paramètre et ainsi de suite.
Linux
| Architecture | Convention d’appel | Stockage des arguments | Qui rétablit la pile ? |
|---|---|---|---|
| x86 | cdecl | Pile | La fonction appelante |
| x86 | fastcall | ecx, edx puis la pile | La fonction appelée |
| x86 | stdcall | Pile | La fonction appelée |
| x86_64 | cdecl | rdi, rsi, rdx, rcx, r8, r9 puis la pile | La fonction appelante |
Windows
| Architecture | Convention d’appel | Stockage des arguments | Qui rétablit la pile ? |
|---|---|---|---|
| x86 | cdecl | Pile | La fonction appelante |
| x86 | stdcall | Pile | La fonction appelée |
| x86 | fastcall | ecx, edx puis la pile | La fonction appelée |
| x86 | thiscall (C++) | ecx (pour this) puis la pile | La fonction appelée |
| x86_64 | stdcall, thiscall, cdecl, et fastcall | rcx, rdx, r8, r9 puis la pile | La fonction appelante |
En mode 64 bits, que ce soit pour Linux ou Windows, la convention d’appel utilisée pour le user land est la même que celle utilisée en kernel land.
Comme vous pouvez le constater, sous Windows, plusieurs noms de conventions d’appel aboutissent au même résultat. En fait, en 64 bits, le compilateur ignore tout simplement ces mots-clés.
Généralement sous Linux, il n’ y a pas trop de soucis entre les conventions d’appel car il n’y en a pas tant que ça qui sont utilisées à part cdecl. Par contre, sous Windows en 32 bits, il faut rester vigilant sur la convention d’appel utilisée.
Pour rappel, IDA indique la convention d’appel utilisée dans la signature de la fonction.
Apprendre le tableau par cœur n’est pas indispensable mais il convient de se rappeler qu’en x86, c’est principalement la pile qui est utilisée contrairement aux programmes 64 bits.
Connaître les conventions d’appel
x86_64sous Linux et Windows peut être utile car on a tendance à s’emmêler les pinceaux d’une convention à l’autre.
Comparaison x86 et x86_64
Je vous propose d’utiliser le programme suivant pour analyser la manière dont les arguments sont transmis :
1
2
3
4
5
6
7
8
9
10
int fun(int a, int b, int c, int d)
{
return (a+b) - (c*d);
}
int main()
{
fun(0xa,0xb,0xc,0xd);
return 1;
}
Pour la compilation :
- en 32 bits :
gcc -m32 main.c -o exe_32 - en 64 bits :
gcc main.c -o exe_64
En ouvrant les deux programmes dans IDA, on obtient ceci :

Nous constatons deux différences :
- Evidemment, la transmission des arguments n’est pas effectuée de la même manière. En 32 bits, tout est en envoyé sur la pile. En 64 bits, comme nous sommes sous Linux, les registres utilisés sont :
edi,esi,edx,ecx. - Lorsque la pile a été utilisée, c’est la fonction appelante, ici
main, qui gère le rétablissement de la pile.
La différence de performances
Pour vous convaincre du gain de performance d’un programme 64 bits par rapport à un programme 32 bits, je vous propose de compiler et exécuter ce programme dans les deux versions :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
#include <time.h>
unsigned long long operation(unsigned long long a, unsigned long long b, unsigned long long c, unsigned long long d)
{
unsigned long long result = 0;
result += (a * b) + (c - d);
return result;
}
int main() {
clock_t start, end;
double cpu_time_used;
start = clock();
unsigned long long res = 0;
for (int i = 0; i < 1000000000; ++i)
{
res += operation(i, 10*i, 150*i+10, 2000*i+3);
}
end = clock();
cpu_time_used = ((double)(end - start)) / CLOCKS_PER_SEC;
printf("Temps CPU : %f secondes\n", cpu_time_used);
return 0;
}
Le temps d’exécution est de l’ordre d’une dizaine de secondes normalement.
En les compilant puis en les exécutant, on constate que le programme 64 bits a été deux fois plus rapide que le programme 32 bits 😎.