Partie 15 - Le décompilateur - les principaux raccourcis et fonctionnalités (2/3)
Le décompilateur : les principaux raccourcis et fonctionnalités
Avant de vous partager un petit challenge de reverse, je vous propose de voir ensemble les principaux raccourcis et fonctionnalités que l’on peut utiliser dans le décompilateur d’IDA.
Il ne va pas être possible de maîtriser lors de ce petit cours toutes les fonctionnalités d’IDA mais au moins d’être capable de modifier au mieux une fonction décompilée pour en comprendre le fonctionnement.
Si vous ne vous souvenez plus de l’utilité et du fonctionnement des différents onglets dans IDA, n’hésitez pas à vous rafraîchir la mémoire dans le chapitre “Analyse statique d’un mini-programme : introduction”.
Le programme utilisé
Voici le programme de test que je vous propose d’utiliser :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
#include <stdio.h>
#include <stdlib.h>
// Enum pour les opérations
enum Operations {
ENCRYPT,
DECRYPT,
INVALID_1,
INVALID_2,
INVALID_3
};
// Structure pour stocker les données à chiffrer
struct Data {
int value;
char name[20];
};
// Fonction de chiffrement
void encryptData(struct Data *data) {
data->value *= 2;
printf("Données chiffrées : value = %d, name = %s\n", data->value, data->name);
}
// Fonction de déchiffrement
void decryptData(struct Data *data) {
data->value /= 2;
printf("Données déchiffrées : value = %d, name = %s\n", data->value, data->name);
}
// Fonction principale
int main(int argc, char **argv) {
struct Data myData = {10, "Secret"};
enum Operations operation = atoi(argv[1]) % 5;
switch (operation) {
case ENCRYPT:
encryptData(&myData);
break;
case DECRYPT:
decryptData(&myData);
break;
case INVALID_1:
puts("Ce cas est invalide !");
break;
case INVALID_2:
puts("Ce cas est aussi invalide !");
break;
case INVALID_3:
puts("Encore invalide !");
break;
default:
printf("Opération invalide !\n");
break;
}
return 0;
}
Le programme est assez débile, généré évidemment par sheikh GPT 🤖, mais contient assez d’éléments pour voir quelques raccourcis que l’on utilise très souvent sous IDA.
Pour le compiler, comme d’hab gcc -m32 -fno-pie -fno-stack-protector main.c -o cipher. Je vous conseille de faire une copie du programme nommée cipher_strip afin de stripper le programme avec strip. Enfin, ouvrez le programme cipher_strip.
Si vous souhaitez avoir la même version du programme que celle du cours, vous pouvez la télécharger ici : cipher_strip.
🔬 L’analyse
🔎 Trouver le main
Comme le programme est strippé, il va falloir trouver quelle fonction correspond au main. Normalement, en allant dans start et en décompilant la fonction, vous devriez trouver la fonction main. Nous avons fait cela au précédent chapitre.
Du travail encore du travail …
Voici à quoi elle ressemble (il peut y avoir des différences en fonction du compilateur et options de compilations que vous avez utilisées) :
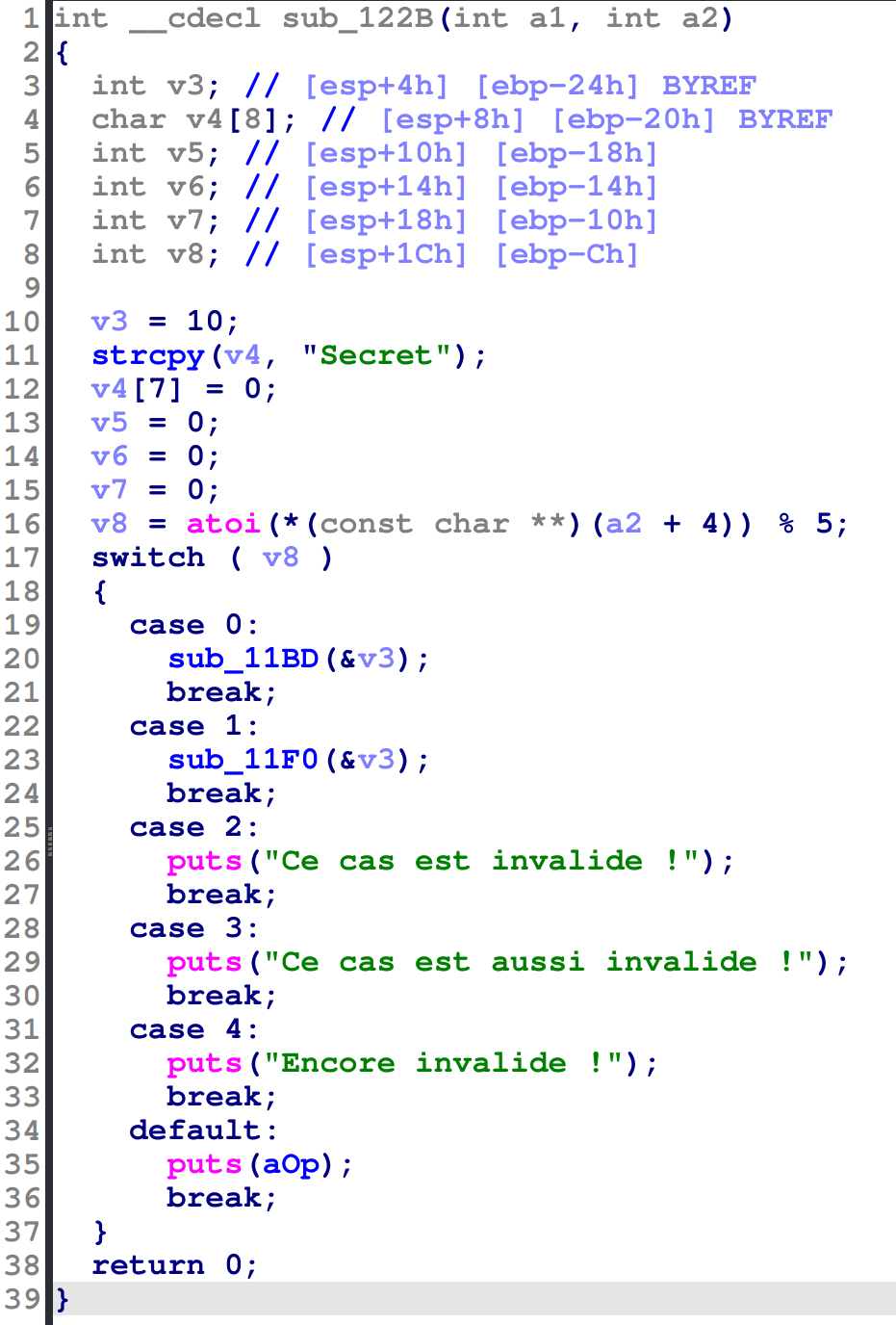
Pas besoin d’être un génie du reverse pour s’y retrouver par rapport au code source utilisé en constatant tout de même quelques différences :
- les noms des fonctions internes ont disparu
- les noms des variables sont perdus
- la forme de notre structure semble inexistante
char **argvest devenu … unint! Je vous ai dit qu’IDA fait parfois d’énormes raccourcis, même Google Maps aurait pas osé …

🔠 Renommage des fonctions et variables
Les fonctions
Tout d’abord commençons par renommer les fonctions vu que l’on sait à quoi elle correspondent. Commençons par renommer sub_122B en main
Astuce IDA : Vous pouvez utiliser le raccourcis
Npour renommer une fonction ou une variable en ayant préalablement cliqué dessus avant de la renommer.
Vous devriez avoir quelque chose comme :
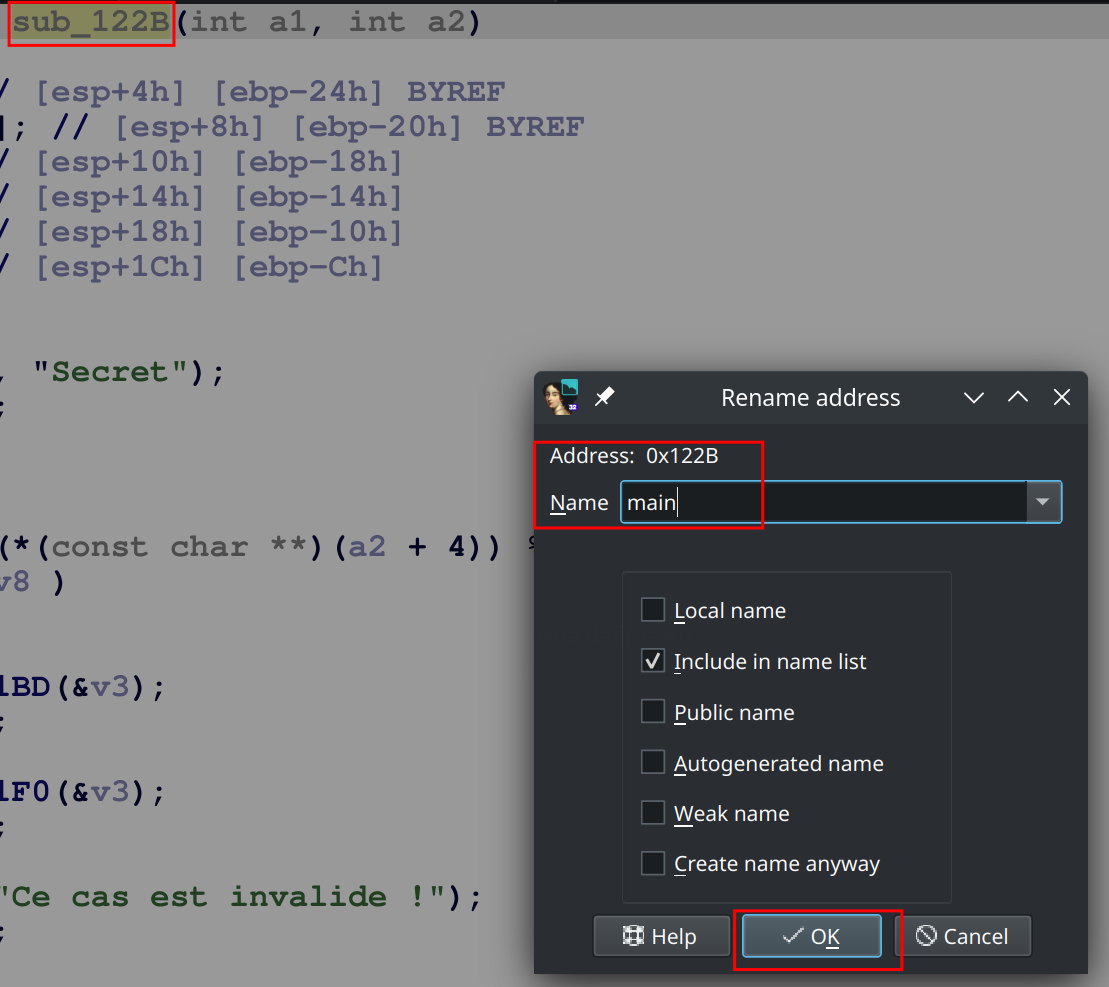
Je ne sais pas pourquoi mais parfois, même après avoir modifié le nom d’une fonction, IDA lui redonne le nom initial. Cela peut arriver lorsque l’on quitte la fonction puis que l’on revient dessus.
Il suffit de relancer la décompilation avec
F5pour que le changement soit affiché.
Vous pouvez également renommer les deux premières fonctions du switch en respectivement f_encryptData et f_decryptData.
Personnellement j’aime bien renommer les fonctions décompilées du programme en les préfixant avec
f_. Cela permet ensuite de retrouver plus facilement celles qui ont été renommées par rapport à celles qui étaient déjà bien nommées.Ce n’est pas une convention stricte, d’autres utilisent le préfixe
mw_lorsqu’ils reverse des fonctions d’un malware, vous avez le choix ! L’idée est simplement de s’y retrouver et facilement distinguer ce qui a été modifié ou non.
Les variables
Astuce IDA : Les variables nommées
v1,v2etc. correspondent à des variables locales d’une fonction tandis que les variablesa1,a2etc. correspondent aux arguments de la fonction.
Normalement, toutes les fonctions appelées par le main ont été renommées, on peut alors s’attaquer aux variables.
Le raccourcis pour modifier le nom d’une variable est le même que pour celui d’une fonction : N. Vous ne pouvez pas donner le même nom de variable à deux variables différentes dans une même fonction mais IDA vous propose alors d’ajouter un suffixe automatiquement pour les distinguer.
J’ai voulu renommer les variables
a1eta2enargcetargvmais IDA l’a déjà fait, comment 🤯 ?
En fait, lorsque l’on a renommé la fonction sub_122B en main, IDA s’est rattrapé et a corrigé la signature de la fonction qui devient alors : int __cdecl main(int argc, const char **argv, const char **envp), tant mieux ! Mais il nous reste du boulot avec les variables locales restantes.
On peut d’ores et déjà renommer la variable v4 appelée via f_encryptData(&v4) qui correspond à myData. Le soucis est que, même après renommage, myData n’a pas le bon type comme vous pouvez le constater :

Pour rappel notre structure de base était :
1
2
3
4
struct Data {
int value;
char name[20];
};
Or IDA considère notre structure de 24 octets en plusieurs variables. Il va donc falloir modifier le type de la variable.
Astuce IDA : Pour modifier le type d’une fonction ou d’une variable, il suffit de cliquer dessus et d’appuyer sur
Y.
Je ne sais pas si cela a été patché depuis mais modifier le nom d’une variable avec
Yen même temps que le type ne fonctionne pas et n’aura aucun effet sur le nom de la variable.Il faut donc modifier le type de la variable dans un premier temps puis modifier son nom dans un second temps 😴.
La création de structure
Avant de pouvoir modifier le type de la variable myData, il est nécessaire de créer la structure idoine. Pour y parvenir, deux choix s’offrent à vous :
- utiliser l’onglet
Structures(View➡️Open subviews➡️Structures) - utiliser l’onglet
Local types(View➡️Open subviews➡️Local types)
Personnellement je trouve l’onglet Local types bien plus facile à manipuler : on peut directement entrer la structure au format C. Dans Structures nous pouvons soit utiliser des structures existantes (peut être très utile !) soit en créer mais il faut bien gérer tous les offsets de la structure.
Je vous proposer de le faire avec Local types. En allant dans cet onglet, utilisez le raccourcis Inser pour copier / coller notre structure comme ceci :
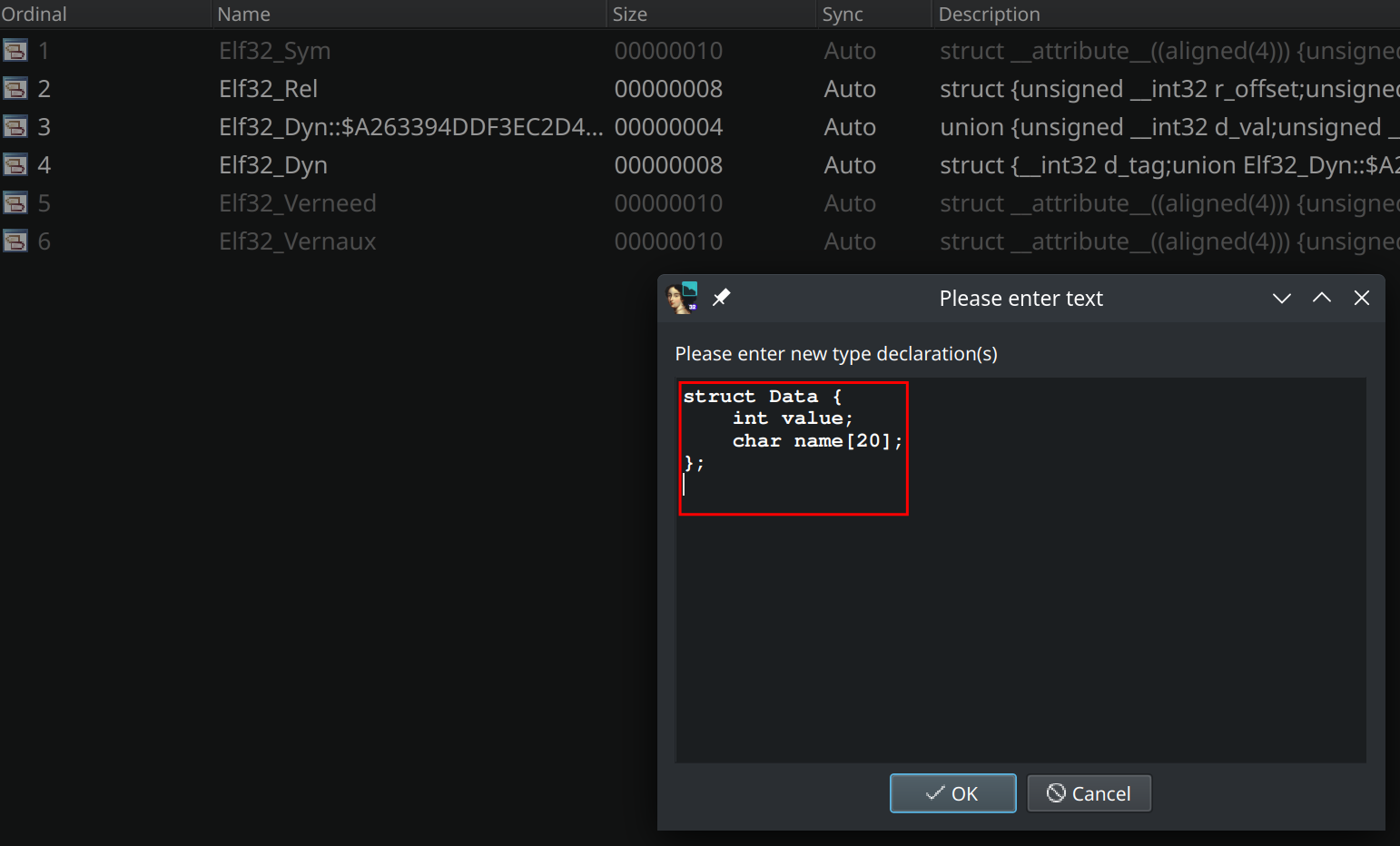
Lorsque l’on appuie sur Ok, on voit bien que notre structure a été ajoutée dans l’onglet. On peut alors retourner dans l’onglet de décompilation Pseudocode-A. Cliquez sur myData puis Y pour modifier son type en struct Data myData puis confirmez. IDA nous affiche alors ce message :
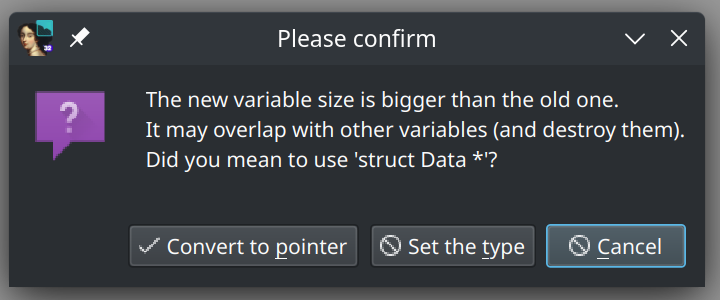
Cela peut faire peur mais IDA veut simplement souligner que le nouveau type de myData (struct Data) est plus grand en termes de taille que l’ancien type int, ainsi, cela risque d’écraser les variables qui la suivent immédiatement.
En ce qui nous concerne, comme notre structure myData a bien été stockée en tant que variable locale, vous pouvez cliquer sur Set the type.
Toutefois, de manière générale, lorsque vous verrez ce message posez-vous la question suivante : est-ce qu’il s’agit d’une structure stockée en tant que variable locale dans la pile ou est-ce finalement un pointeur vers une structure stockée ailleurs ?
Généralement, la réponse est affirmative à la seconde question car on a tendance à utiliser les structures avec des pointeurs vers les structures lorsque l’on les manipule.
A ce stade, en termes de renommage, il ne nous reste plus qu’à renommer la dernière variable non renommée : la valeur de retour de atoi qui est operation.
Mais pourquoi on a les deux fonctions
strcpyetmemsetdans le code décompilé alors que l’on a jamais appelé ces fonctions dans le code source ?

Bien vu Watson ! Vous remarquerez que ces le nom de ces fonctions est en bleu contrairement aux autres fonctions de la libc qui est en rose. De plus, en double cliquant dessus, aucune fenêtre vers ces fonctions ne s’ouvre …
En fait, il s’agit tout simplement de la façon dont IDA voit le stockage de cette string :
1
2
struct Data myData = {10, "Secret"};
// ^^^^^^
IDA a traduit les instructions assembleur qui correspondent au chargement de "Secret" sur la pile comme si strcpy était appelée puis memset pour mettre à 0 le reste. C’est assez cool car cela permet de comprendre facilement en C via le code décompilé ce qu’il se passe en assembleur.
La gestion des énumérations
A ce stade vous devriez avoir quelque chose proche de ceci :
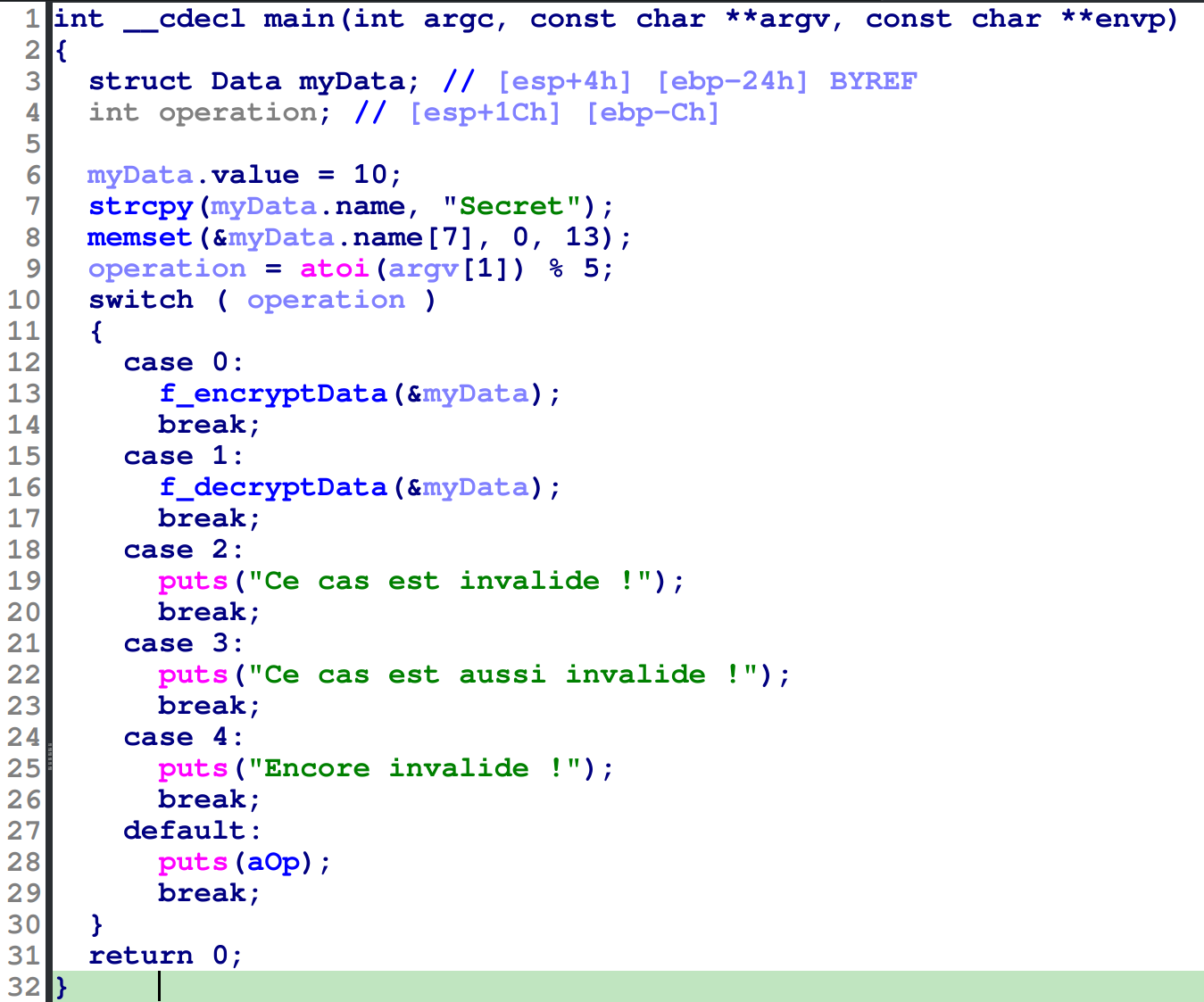
Pour faciliter la compréhension du code, que diriez-vous de remplacer les case 0, case 1 etc. par des enums ?
Là encore vous avez deux choix possibles :
- utiliser l’onglet
Enums(View➡️Open subviews➡️Enumerations) - utiliser l’onglet
Local types(View➡️Open subviews➡️Local types)
Pour les mêmes raison que précédemment, je préfère utiliser l’onglet Local types pour pouvoir copier/coller le code de l’enum sans devoir ajouter les différentes valeurs de l’énumération une à une ni me casser la tête.
Comme tout-à-l’heure, aller dans Local types, saisir le raccourcis Inser et copier/coller l’enum puis valider :
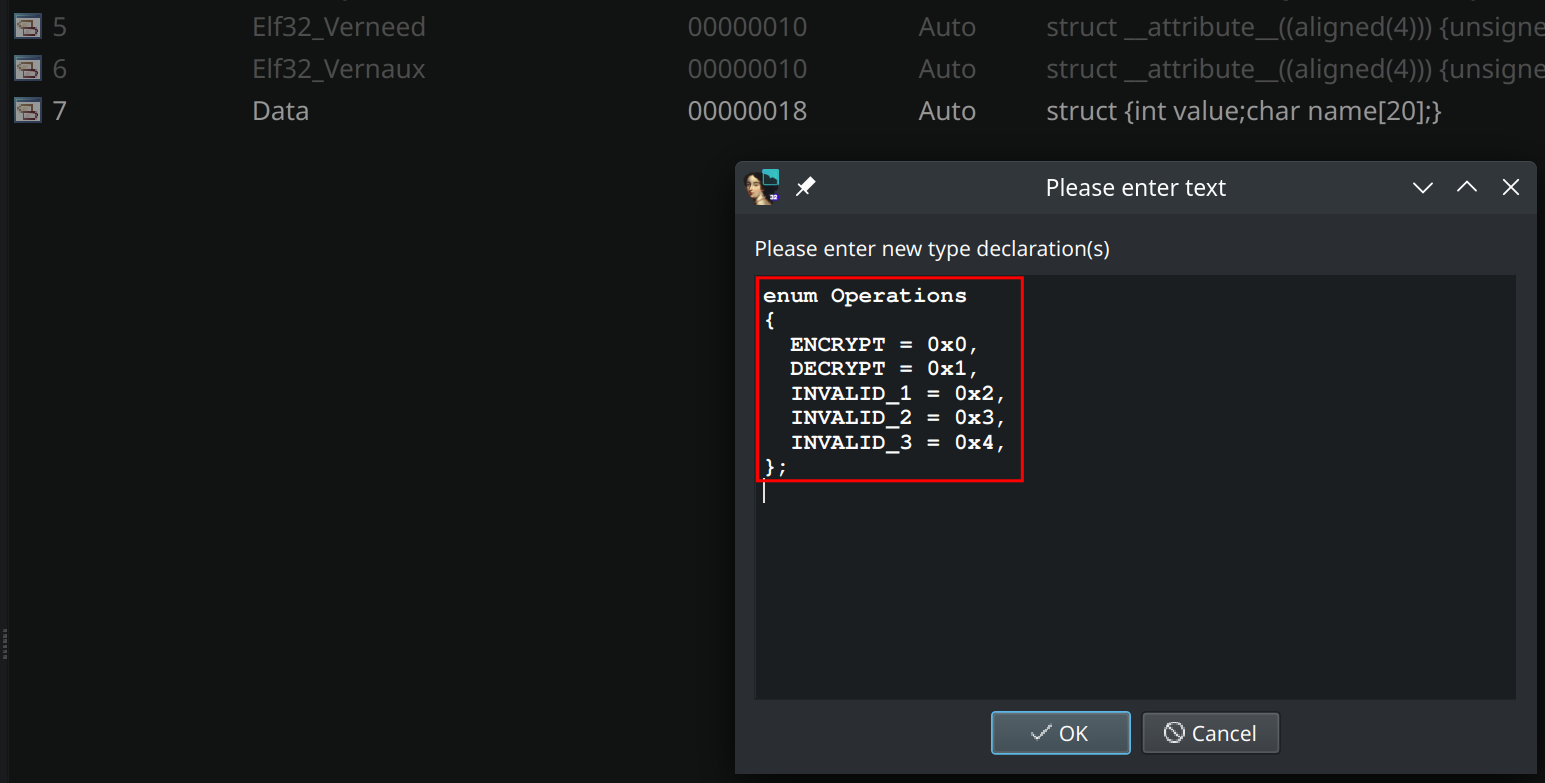
L’énumération est créée, on peut retourner à notre fonction main.
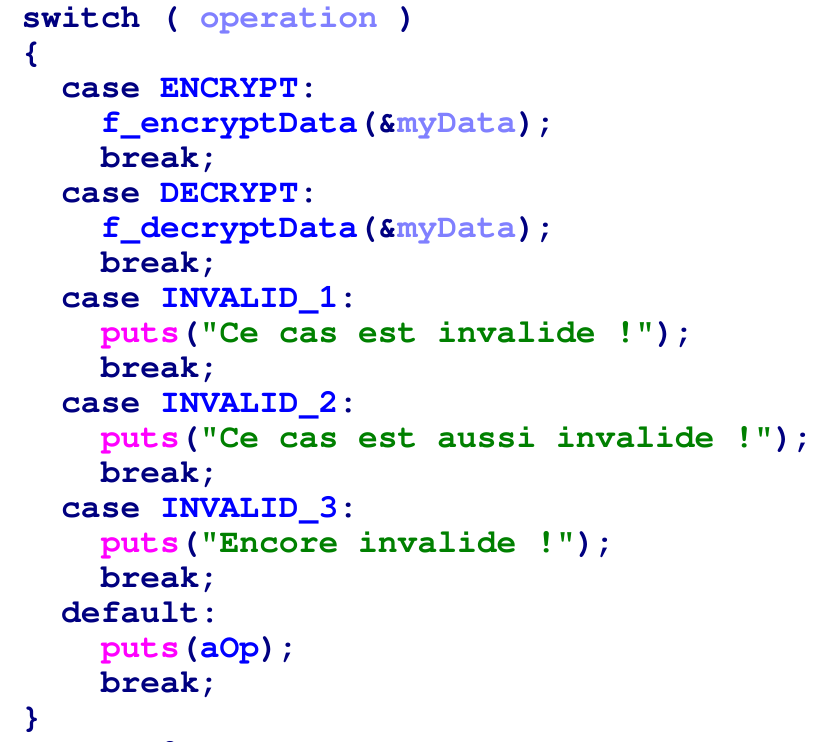
Cliquez sur le chiffre 0 dans case 0 puis appuyer sur M.
Astuce IDA : Le raccourcis permettant d’assigner à des constantes des énumérations est
M.
Ensuite sélectionnez l’enum que l’on vient d’ajouter :
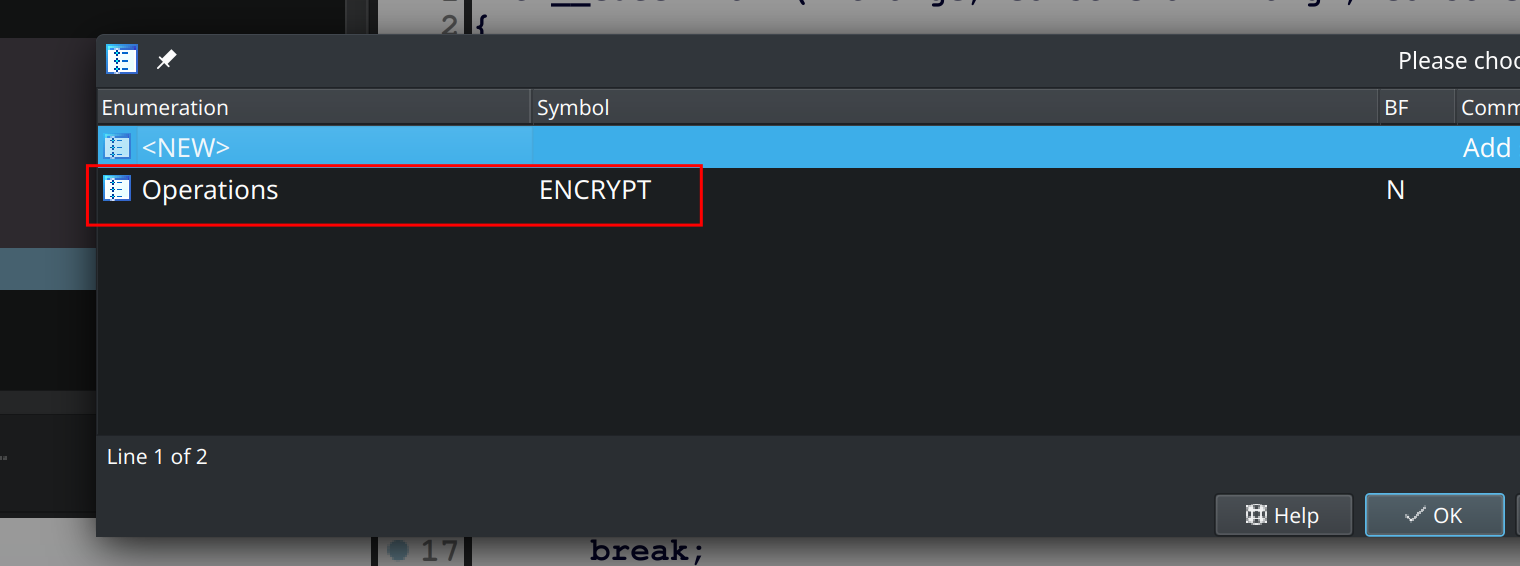
En confirmant, le tour est joué et on a le résultat attendu :
Les commentaires
On aurait pu tout simplement s’arrêter là en ce qui concerne l’analyse statique de cette fonction : elle est assez courte et maintenant que les variables et fonctions sont renommées, on sait exactement ce qu’elle fait.
Toutefois, cela nous permettra de voir les raccourcis permettant d’insérer un commentaire et les différents types de commentaires utilisables.
Tout d’abord, commençons par les commentaires en fin d’instruction.
Astuce IDA : Il est possible de mettre un commentaire sur la même ligne que l’instruction sélectionnée dans la fenêtre de décompilation avec le raccourcis
/.Dans la fenêtre du code désassemblé, cela est possible avec
:ou;.
Exemple (code décompilé) :

Exemple (code désassemblé) :

Il est également possible de mettre des commentaires avant l’instruction.
Astuce IDA : Vous pouvez utiliser le raccourcis
Inserpour saisir un commentaire avant l’instruction sélectionnée.
Astuce IDA : En utilisant la touche
Entrée, vous pouvez ajouter des sauts de lignes, pratique lorsque l’on souhaite espacer le code.
J’ai essayé de sauter des lignes mais j’arrive plus à les supprimer !
En fait les sauts de lignes sont simplement des commentaires précédent une instruction mais qui ne sont constitués que de sauts de lignes. Vous pouvez donc modifier le commentaire pour supprimer les sauts de lignes ajoutés.
Exemple :

✨ Résultat final
Et si on comparait le programme avant et après reverse ?
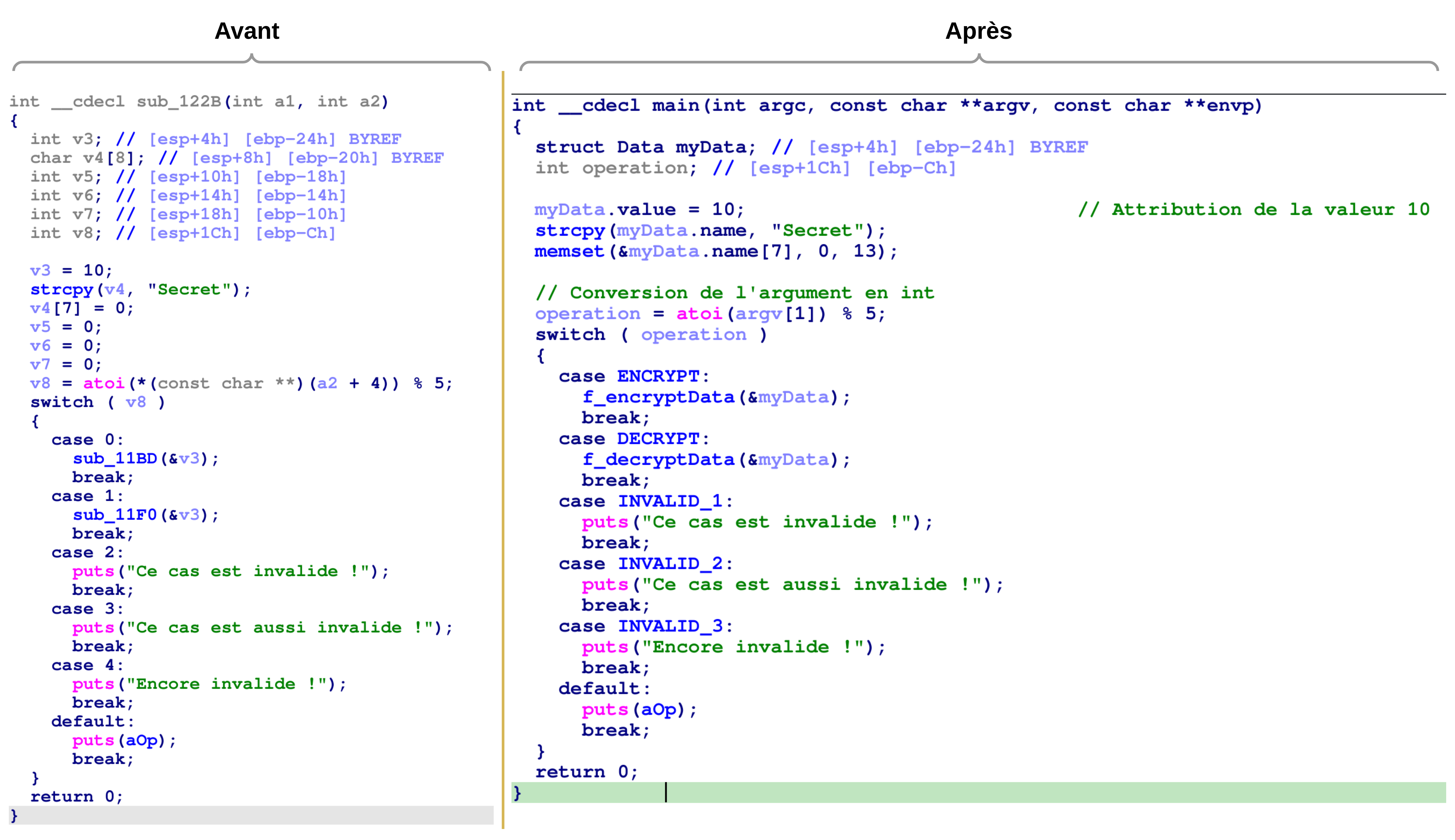
Vous voyez la différence ? Lorsque tout est bien renommé et mis à sa place, la compréhension de la fonction coule de (code) source 😊. On comprend alors plus aisément pourquoi le renommage de fonctions, de variables, l’écriture de commentaires etc. sont importants en analyse statique : cela simplifie et fluidifie la compréhension du code.
Bon, on va pas se mentir, on avait le code source avec nous c’était assez facile 😆 ! Mais sans code source, aurions-nous réussi le reverse aussi facilement 😢 ?
On a même pas eu besoin de lire de l’assembleur grâce à la décompilation. De toute façon, une fois que l’on goûte à la décompilation, difficile d’y résister 🥰!

D’autres outils de décompilation
Pour rappel, on a choisi d’utiliser IDA car désormais, il est possible d’utiliser le décompilateur dans la version Freeware et il est plus ergonomique. M’enfin, ce n’est que mon humble avis 😊.
Evidemment, comme certains pourraient ne pas être d’accord et voudraient utiliser d’autres outils, en voici quelques-uns :
- 🐉 Ghidra : Initialement développé par la NSA et devenu open source. Très pratique pour le reverse d’architecture différentes de x86 (même s’il fait le travail). Pour reverser des programmes Windows, il semble être moins adapté … Quant à son UI, soit on aime soit on aime pas 😅.
- 🥷 Binary Ninja : Outil développé plus récemment et qui est payant. Une version gratuite sur le cloud est cependant proposée.
- ⏪ Cutter : Outil open source basé sur Rizin.
Encore une fois, l’idée n’est pas de se focaliser que sur un seul outil mais de connaître les forces et faiblesses de chacun de ces outils pour savoir quand les utiliser à bon escient.
📋 Résumé
Pour résumer, voici les principaux points évoqués (sans être exhaustif) :
- Il est nécessaire d’adopter une méthodologie et une stratégie d’analyse pour reverser un programme : il n’est souvent pas nécessaire ni pertinent d’analyser toutes les fonctions d’un programme en profondeur
- Connaître sur les bout des doigts les principaux raccourcis d’IDA permet d’avancer bien plus vite
- Du code décompilé dont les variables et fonctions appelées sont renommées est bien plus lisible et plus facilement compréhensible
- On passe pas mal de temps à renommer, renommer et renommer