Partie 13 - La gestion des variables
La gestion des variables
Dans cette partie, nous allons nous intéresser à la manière dont sont gérées les variables en assembleur. Nous en avons déjà un peu parlé à plusieurs reprises lorsque nous avions parlé du fonctionnement de la pile ainsi que des différents segments mémoire (code, données, tas …) et ce qu’ils contenaient.
Ce sera aussi l’occasion de parler d’une chose que j’ai souhaité garder de côté pour l’instant 🫣.
Dans cette partie, nous allons beaucoup nous intéresser à des zones mémoire à partir d’offsets relatifs à
ebp.Il est vivement recommandé de se munir d’un ✏️ et d’une 🗒️ afin de représenter soi-même les variables en mémoire pour savoir comment elles seront agencées.
Les types de données
Les types de base
Tout d’abord, il serait pas mal de se rafraîchir la mémoire avec les types de base en C, voici un tableau synthétique de ces différents types avec leur taille.
Ce qu’il faut retenir avec les types de base est qu’ils ont des tailles variables (un int n’a pas la même taille qu’un char). Ainsi, si vous faites le reverse d’un programme et qu’IDA pense avoir trouvé un tableau de 10 int, il est possible que ce soit en réalité un tableau de 40 char.
Bon, et si on essayait de voir comment ces types sont représentés en mémoire avec un petit exemple ? Voici un petit programme qui fera l’affaire :
1
2
3
4
5
6
7
8
9
int main(int argc, char *argv[])
{
char chr = 'A';
int nombre = 0xdeadbeef;
unsigned short sh = 0xcafe;
unsigned long lg = 0xaabbccdd;
return 0;
}
Pour le compiler : gcc -m32 -fno-pie -fno-stack-protector main.c -o exe.
Comme d’hab’, on l’ouvre dans IDA :
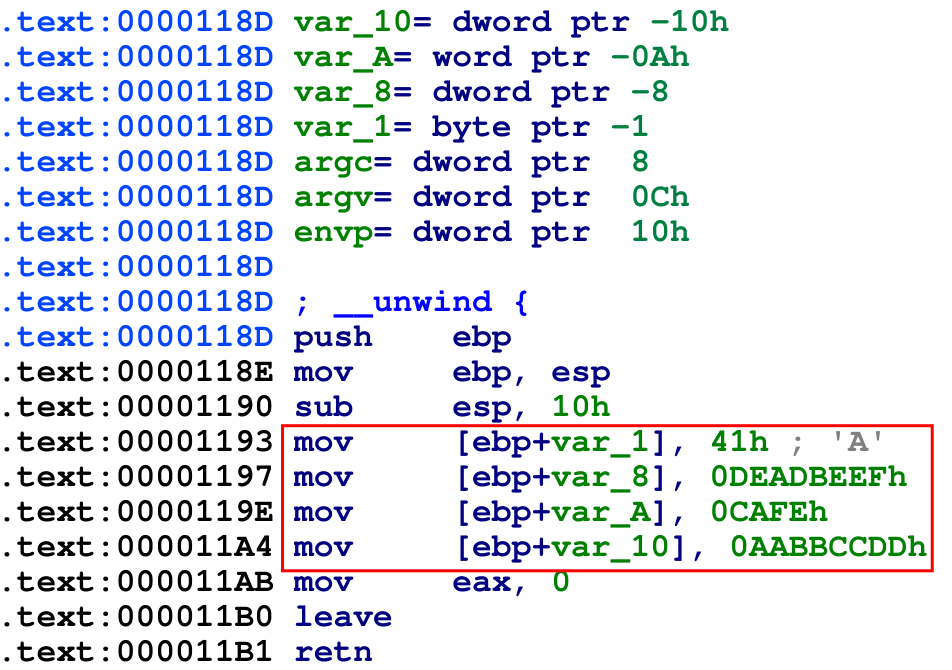
On constate que les variables locales sont bien sauvegardées dans la pile. Un bon exercice serait de faire un schéma de la pile avec ces différentes valeurs.
Vous pouvez comparer ensuite ce que vous avez trouvé avec le schéma suivant (état de la pile à 0x11ab):
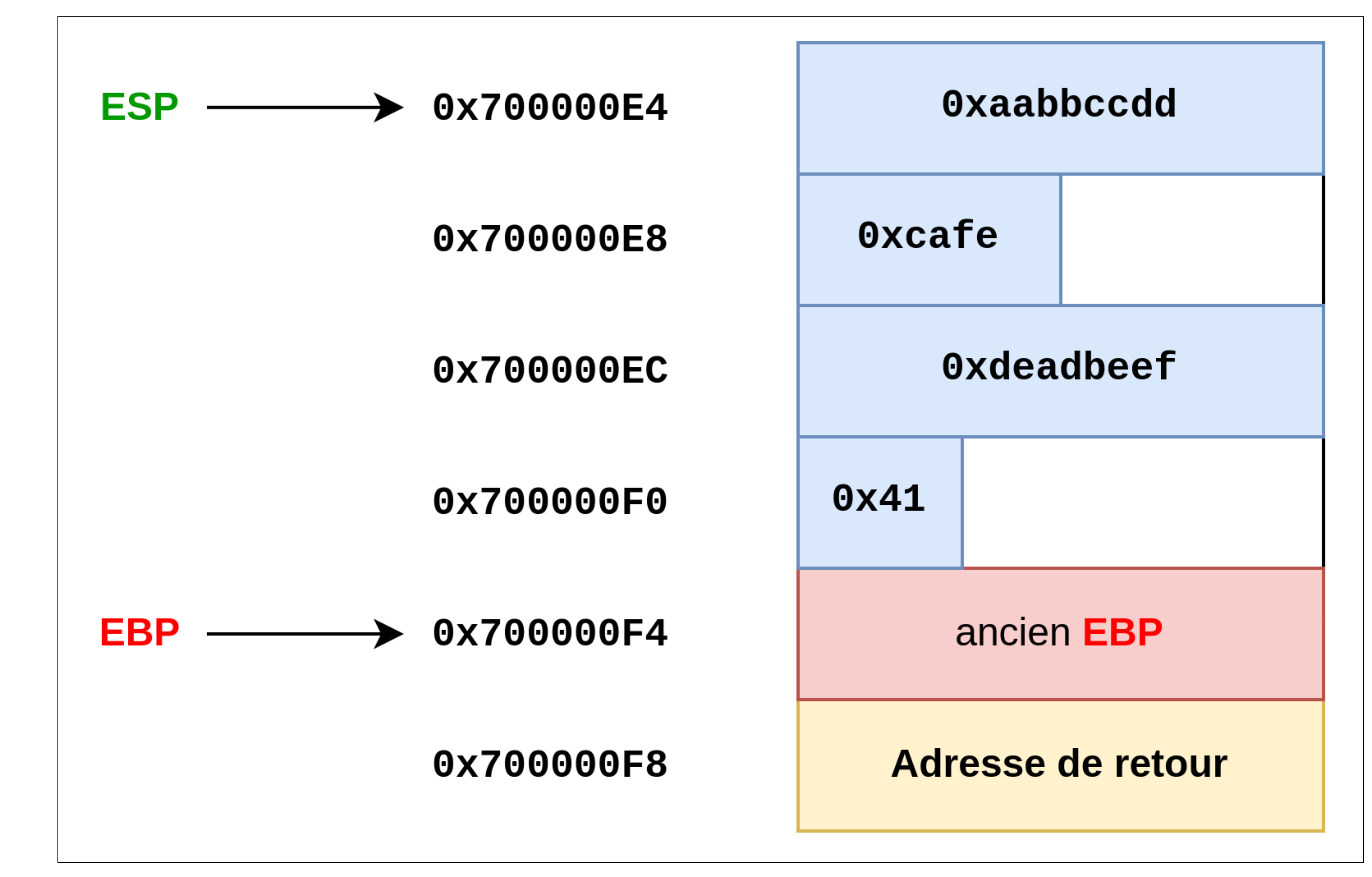
On constate plusieurs choses :
- les noms des variables locales ne sont pas gardées après la compilation, mais ça, on le savait déjà.
- Les variables dans la pile sont insérées de la première variable déclarée à la dernière en remontant dans la pile. Ainsi, lorsque l’on lit la pile de haut en bas, les valeurs sont affichées dans le sens inverse de leur déclaration dans le code C.
- il y a des trous (qui contiennent des valeurs quelconques, par forcément nulles) alors que l’on aurait pu faire tenir toutes les variables sur 11 octets au lieu de 16.
- que la variable soit signée ou non, le code assembleur n’a pas cette information sur chaque valeur. Ce qui va permettre de les différencier est les instructions (signées ou non) utilisées. Exemple :
jb(non signé) oujl(signé).
Concernant l’histoire des trous, il s’agit encore une fois d’une histoire d’alignement qui arrange le processeur lorsqu’il souhaite accéder à certaines valeurs.
L’encodage ASCII
Y a un truc que je comprends pas. Dans le code on a définit notre variable
char chr = 'A';, pourquoi cela a été remplacé par0x41?
Très bonne question ! C’est vrai que la première fois que l’on voit de l’ASCII on est un peu perdus …
En fait, les caractères n’ont pas réellement de sens pour un ordinateur. Ce qu’il sait traiter ce sont des bits. Ces bits peuvent ensuite être regroupés pour représenter des données, notamment des nombres.
Les nombres peuvent facilement être représentés en notation binaire ou hexadécimale, c’est pourquoi, par exemple, l’instruction mov reg, 0x213 a du sens pour le processeur.
Pour ce qui est des caractères, c’est pas évident. C’est pourquoi il a été convenu d’affecter un nombre à chaque caractère. Ainsi, lorsque l’on souhaite manipuler un caractère, il suffit de manipuler l’encodage (nombre) associé.
Voici ce que l’on appelle la table ASCII qui donne l’encodage de chaque caractère :
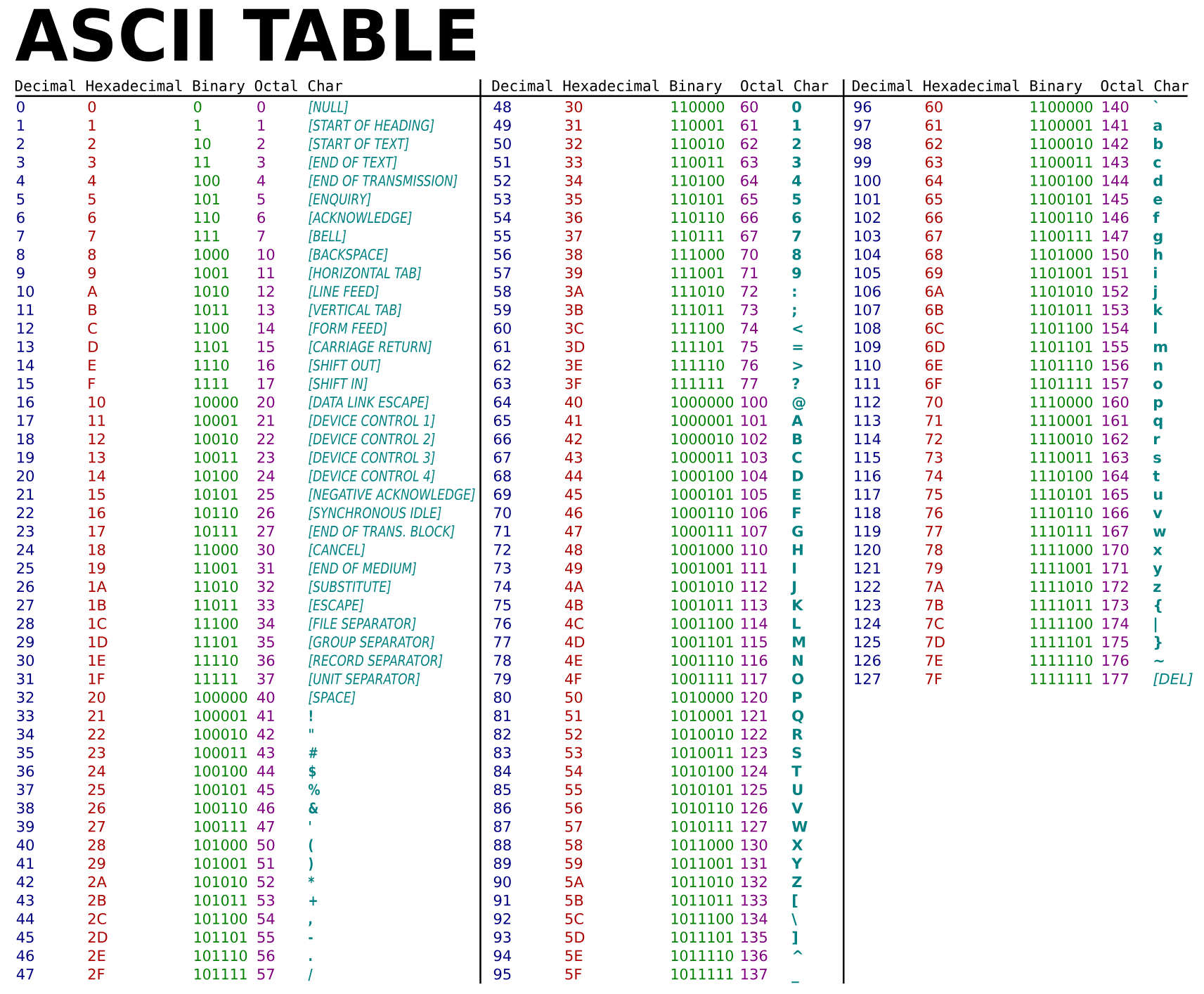
Ainsi, on constate bien que la caractère A est encodé 0x41.
Connaître par cœur ces valeurs n’a que très peu d’intérêt, par contre il est intéressant de savoir détecter des caractères ASCII lorsque l’on voit des nombre compris entre 0x20 et 0x7e. En effet, la beacoup de programmes (crackmes ou autre) encode leurs strings en ASCII.
Sous Windows, l’encodage principalement utilisé n’est pas ASCII mais l’UTF-16. Il s’agit d’un encodage différent de l’ASCII, notamment par le fait qu’il soit encodé sur deux octets (au lieu d’un).
Cela permet de pouvoir encoder bien plus de caractères, notamment ceux de langues non latines (arabe, chinois …).
Les structures et les tableaux
Considérées comme les ancêtres des classes (en C++), les structures permettent de regrouper plusieurs variables de types différents dans un seul type. Les tableaux, quant à eux, permettent de regrouper un certain nombre de variables de même type.
Voyons comment sont représentés en mémoire ces deux types de variable avec cet exemple :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
struct MaStructure
{
int nb;
char ch;
unsigned int u_nb;
unsigned char u_ch;
};
int main()
{
struct MaStructure ma_struct;
ma_struct.nb = 0xdeadbeef;
ma_struct.ch = 'a';
ma_struct.u_nb = 0xcafebabe;
ma_struct.u_ch = 'b';
int tab[5] = {0x10, 0x20, 0x30, 0x40, 0x50};
return 0;
}
En le compilant avec gcc -m32 -fno-pie -fno-stack-protector main.c -o exe, on obtient :
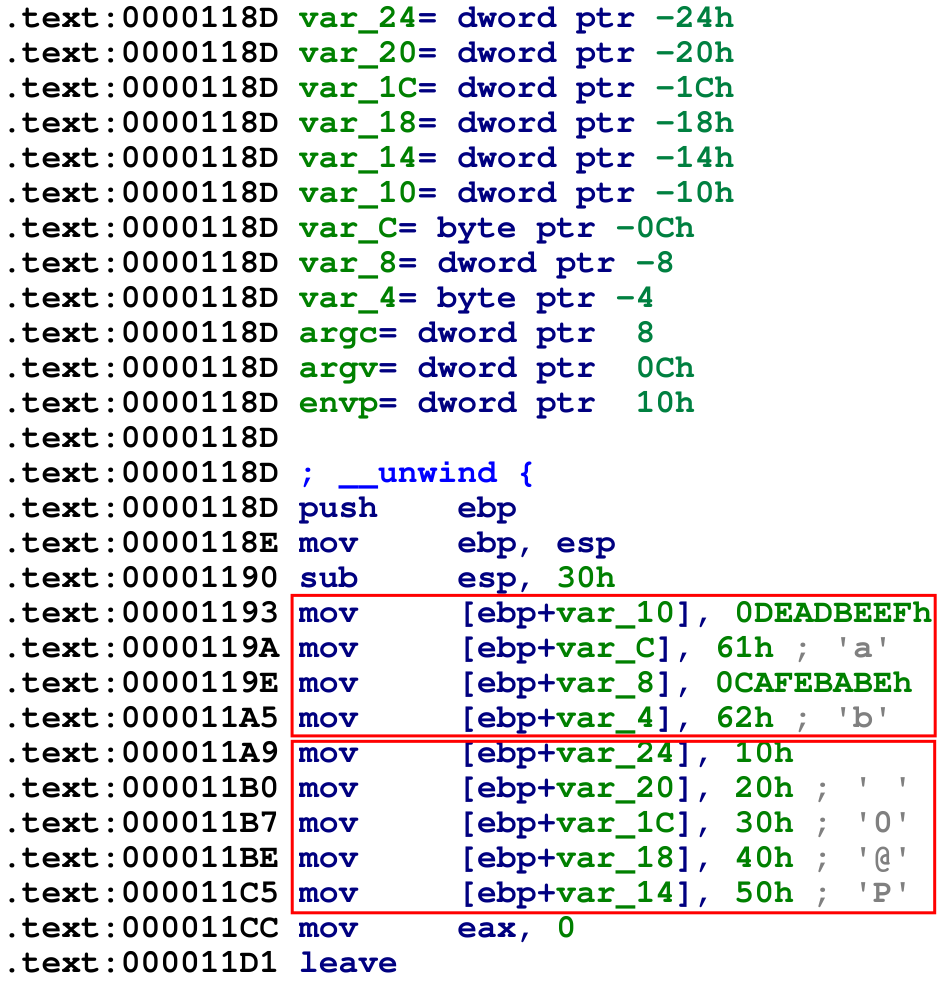
Lorsque le processeur arrivera à 0x11cc, la pile aura donc cette forme :
Finalement, il n’y a pas de grandes différences avec la gestion des types de base si ce n’est que :
- l’ordre des éléments du tableau et de la structure sont affichés dans le bon ordre lorsque l’on lit les valeurs de haut en bas (alors qu’avec les variables de base, c’était l’inverse)
- les
charne sont pas positionnés sur l’octet de poids fort mais sur l’octet de poids faible
Si on a choisi de parler des structure et des tableaux dans le même endroit, c’est parce qu’en termes d’assembleur il y a pas mal de similitudes entre les deux. D’ailleurs, il se peut parfois qu’IDA confonde une structure avec un tableau.
Par ailleurs, on remarque qu’il y a toujours un respect de l’alignement l’agencement en mémoire de la structure. C’est pourquoi il est important de faire attention à la manière dont on déclare une structure si on souhaite économiser de la mémoire en tant que développeur.
Voici un exemple pour illustrer ces propos où deux structures avec les mêmes éléments sont utilisées mais sont l’agencement des éléments (et donc en mémoire) est différent :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include <stdio.h>
struct MaStructure
{
int nb; // 4 octets
char ch; // 1 octet
unsigned int u_nb; // 4 octets
unsigned char u_ch; // 1 octet
};
struct MaStructure_bis
{
int nb; // 4 octets
unsigned int u_nb; // 4 octets
unsigned char u_ch;// 1 octet
char ch; // 1 octet
};
int main()
{
struct MaStructure ma_struct;
ma_struct.nb = 0xdeadbeef;
ma_struct.ch = 'a';
ma_struct.u_nb = 0xcafebabe;
ma_struct.u_ch = 'b';
struct MaStructure_bis ma_struct_bis;
ma_struct_bis.nb = 0xdeadbeef;
ma_struct_bis.ch = 'a';
ma_struct_bis.u_nb = 0xcafebabe;
ma_struct_bis.u_ch = 'b';
return 0;
}
En compilant le code, on s’aperçoit que ces deux structures sont agencées différemment en mémoire :
Comme vous pouvez le constater dans l’exemple précédent, ce n’est pas l’initialisation des variables qui compte mais leur ordre dans la déclaration de la structure et de ses éléments.
On aurait même pu ajouter 2 variables char dans ma_struct_bis, le résultat en mémoire aurait toujours été plus compact qu’avec ma_struct.
Les pointeurs
C’est une notion qui généralement est compliquée à appréhender lorsque l’on commence le C. En reverse c’est plus simple car on voit directement comment fonctionne un pointeur en mémoire : il s’agit d’une adresse qui pointe vers des données situées quelque part en mémoire.
Contrairement aux autre types de données, un pointeur a toujours la même taille :
- 32 bits (en x86)
- ou 64 bits (en x86_64, généralement en user land seuls 48 bits suffisent)
Généralement on les reconnaît assez facilement car leurs octets de poids fort identifient une base (ou début de zone mémoire) en particulier, par exemple :
- les adresses
0x400010,0x41a010et0x40ff1fcorrespondent à des pointeurs vers une zone mémoire du programme mappé en mémoire ( cela peut être la partiedata,code…) dont la base est `0x400000. - les adresses
0x7ffdd050,0x7ffdddd0ou0x7ffdf004correspondent à des adresses basses, qui pointent notamment vers la pile dont l’adresse de base ici est0x7ffdd000
Selon l’OS et la version du programme (32/64 bits), les adresses de base de la pile, du code, des données etc. ne sont pas les mêmes.
D’autant plus que les programmes sont désormais soumis à l’ASLR qui tend à rendre aléatoire certains octets (de poids fort) d’une adresse d’une exécution à une autre.
Concernant leur agencement en mémoire, il n’y a pas de soucis en particulier car que ce soit 4 octets ou 8 octets, les pointeurs seront alignés avec le reste des données.
Quid des chaînes de caractères ?
Il existe plusieurs manières de déclarer des chaînes de caractères en C qui, au final, reviennent toutes à deux formes :
- un tableau de caractères.
- Exemple :
char chaine[] = {'H', 'e', 'l', 'l', 'o', '\0'};
- Exemple :
- un pointeur vers un tableau de caractères
- Exemple :
char *chaine = malloc(taille_de_string);
- Exemple :
Les portées des variables
Nous avons vu ci-dessus comment sont stockées les différents types de variables sur la pile lorsqu’elles sont déclarées de manière locale, c’est-à-dire au sein d’une fonction (sans le mot clé static).
Toutefois, ce n’est pas la seule manière de déclarer une variable. Il est possible de déclarer des variables ayant différentes portées dans le code. Cela implique également une zone de stockage différente pour les variables selon leur déclaration et portée.
Intéressons-nous aux portées suivantes :
- 🟡 les variables locales : déclarées au sein d’une fonction (sans le mot clé
static) - 🟢 les variables globales : déclarées en dehors de toute fonction et ayant une portée plus globale dans le code
- 🟢 les variables statiques : déclarées dans une fonction avec le mot clé
static - 🔵 les variables dynamiques : elles peuvent être déclarées à divers endroits mais leur affectation est le résultat d’une allocation dynamique (avec
mallocet compagnie ounewen C++) - 🟣 les variables constantes : ces variables sont déclarées avec le mot clé
const
🟡 Les variables locales
A force de les avoir utilisées lors des divers exemples, on a pris l’habitude d’analyser ce type de variables. Bien que ces variables puissent avoir des types différents, elles ont toute un point commun : elles sont stockées dans la pile.
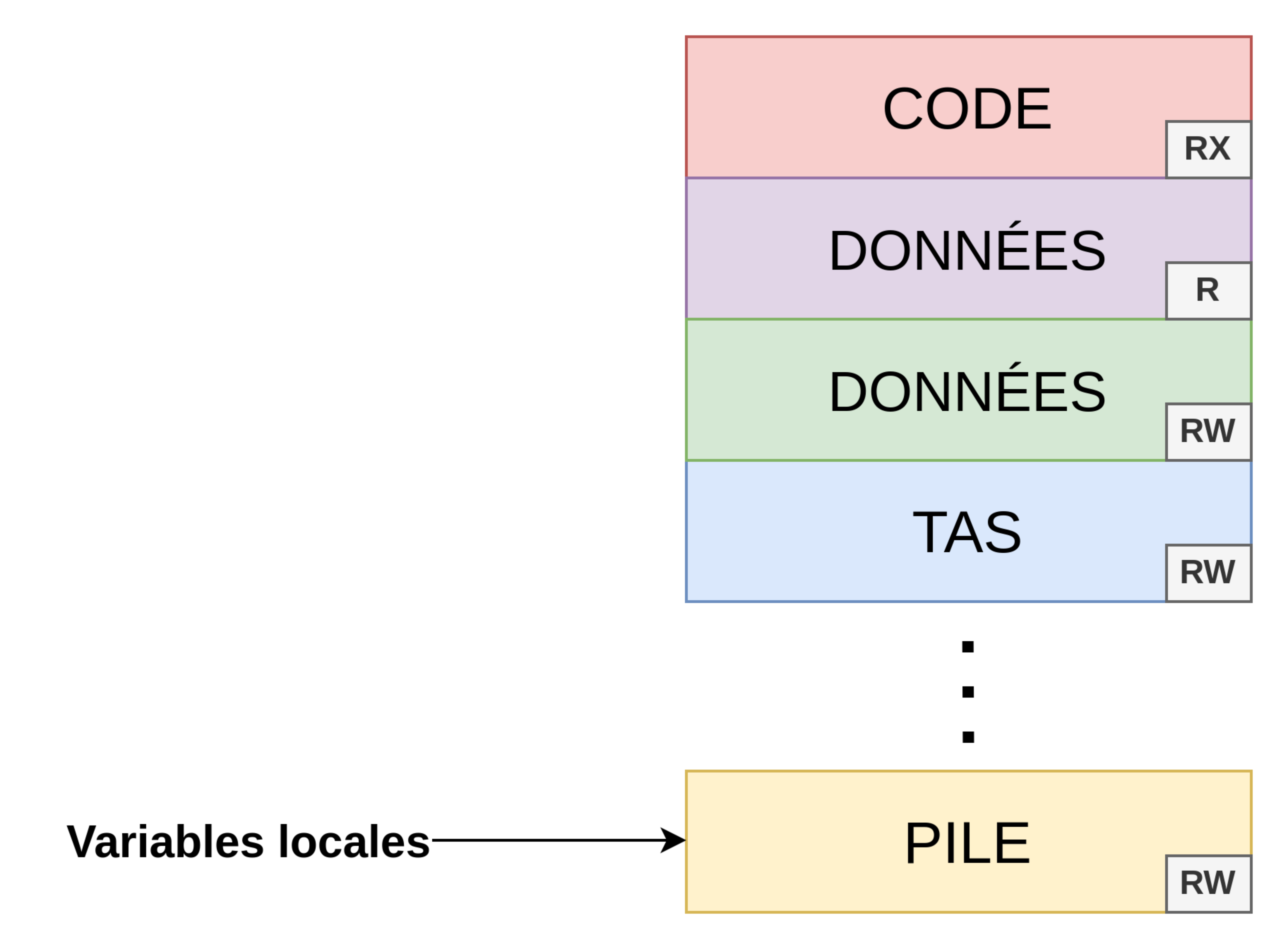
Exemple
1
2
3
4
5
int main()
{
int ma_var_locale = 10; // dans la pile
return 0;
}
🟢 Les variables globales et statiques
Nous allons nous intéresser à ces deux manières de déclarer une variable en même temps car elles sont stockées de la même manière en mémoire.
Nous allons distinguer deux cas :
- la variable n’est pas initialisée (ou initialisée à 0) : elle est stockée dans la section
.bss - la variable est initialisée à une valeur non nulle : elle est stockée dans la section
.data
.bss est .data sont deux sections du segments de données modifiable (RW). Leur point commun est qu’elles permettent de stocker des données qui peuvent être modifiées au cours de l’exécution.
Leur principale différence est que .bss contient des variables initialisées à 0 lors de l’exécution du programme tandis que .data contient des variables qui sont initialisés à une valeur non nulle lors de l’exécution du programme.
Exemple
1
2
3
4
5
6
7
8
9
10
int global_var; // dans .bss
int global_var_2 = 0; // dans .bss
int global_non_nulle = 0x10; // dans .data
int main()
{
static int stat ; // dans .bss
static int stat_non_nulle = 213; // dans .data
return 0;
}
🟣 Les variables constantes
Les variables déclarées avec le mot clé const ne doivent pas pouvoir être modifiées après leur déclaration.
Ainsi, elles se retrouveront dans les données en lecture seule, plus précisément dans la section .rodata.
Parfois, lorsque certaines variables ou valeurs sont constantes dans une fonction, le compilateur peut parfois les optimiser en les insérant leur valeur directement dans des instructions.
Par exemple, si je crée un variable
int x = 0x46;qui n’est jamais modifiée puis que je faisy = y + x;, l’instruction associée pourrait alors être :add eax, 0x46.
Exemple
1
2
3
4
5
6
7
8
#include <stdio.h>
int main()
{
const char *message = "Hello !"; // dans .rodata
printf("%s\n", message);
return 0;
}
🔵 Les variables dynamiques
Nous l’avons vu précédemment : les variables dynamiques sont des variables dont le contenu est alloué dynamiquement avec une fonction d’allocation (malloc, calloc, new …).
Mais concrètement, qu’est-ce cela implique sur ces variables ? Tout d’abord ces variables vont être stockées dans le tas (ou heap).
Encore une fois, le terme “tas” n’est pas à prendre au sens algorithmique mais plutôt dans le sens où il s’agit d’une zone mémoire qui regroupe un tas de variables.
Je vous propose d’analyser un petit exemple pour comprendre de quoi il s’agit :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char *falestine = malloc(20); // Alloue de l'espace pour 20 caractères
if (falestine == NULL ) {
printf("Allocation de mémoire échouée.\n");
return -1;
}
strcpy(falestine, "Toujours la !");
free(falestine); // ;)
return 0;
}
Comme son nom l’indique, les variables dynamiques sont … dynamiques ! (merci Sherlock 🕵️♂️). Ainsi nous n’allons pas pouvoir voir où elles sont stockées via une analyse statique.
Comme pour la pile, le tas n’est mappé en mémoire que lors de l’exécution du programme.
Bah on fait comment ?
Je sais, je sais, je ne vous ai pas encore dit ni expliqué comment utiliser un debugger mais ça arrive 😅 ! En attendant, je vais vous montrer ce qui se passe lorsque l’on débogue le programme.
Après compilation, lorsque l’on exécute le programme pas à pas jusqu’à arriver à l’appel de free : call free on obtient ceci :
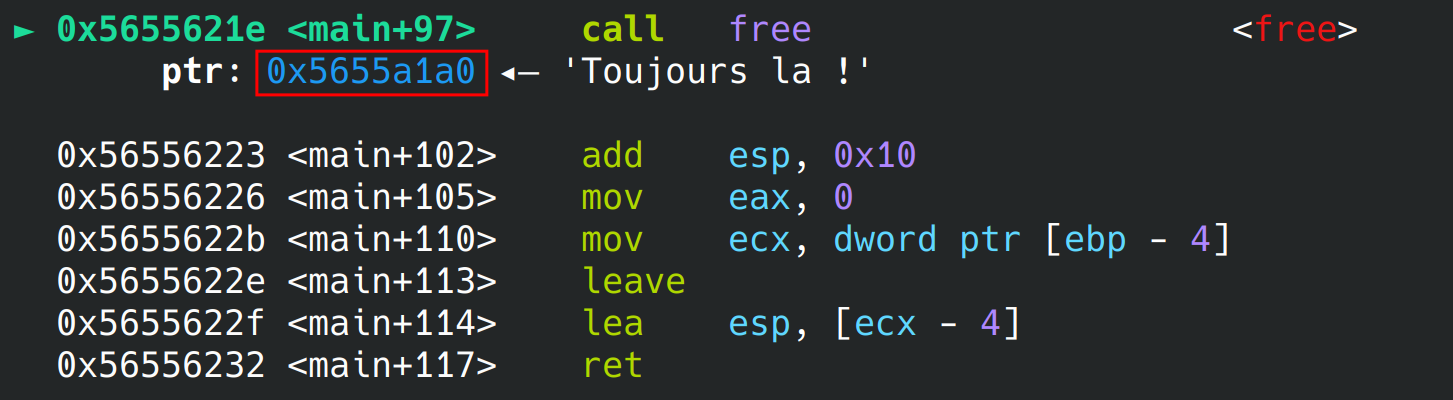
Dans le code, l’appel était le suivant free(falestine);. L’argument de free est donc ce qui doit être libéré … l’adresse de notre string. En l’occurrence il s’agit de l’adresse 0x5655a1a0.
Dans un debugger, on peut lister les différents segments du processus en cours d’exécution :
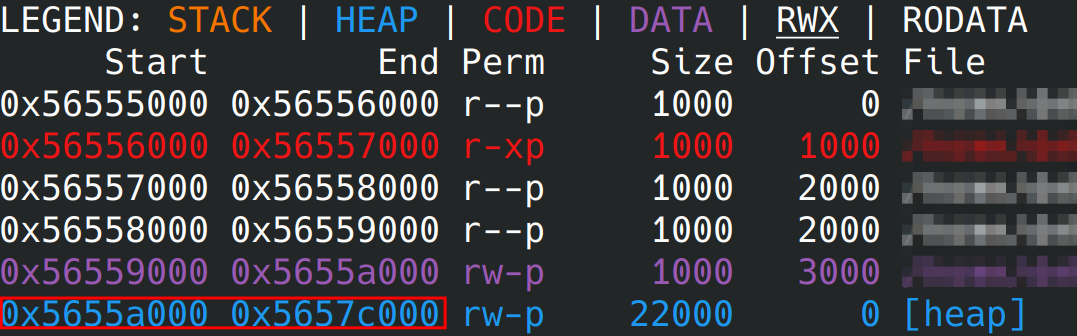
On constate qu’effectivement, l’adresse 0x5655a1a0 appartient à la heap et non aux autres segments mémoire.
Il y a tellement à dire concernant le tas, notamment du fait que les données soient stockées en suivant divers mécanismes et agencements (métadonnées, listes, listes doublement chaînées …).
En tant que reverser analysant du code, il n’y a pas de nécessité à comprendre en détail le fonctionnement de la heap. Cela est cependant très important lorsque l’on souhaite faire de la recherche de vulnérabilité, exploitation de binaires (pwn) …
📋 Synthèse
Voici une synthèse de la localisation des variables selon leur déclaration :