Partie 10 - Structures de contrôle - les comparaisons (1/3)
Structures de contrôle : les comparaisons
A ce stade, nous n’avons pas encore tous les éléments pour pouvoir nous attaquer à des programmes plus costauds ou même de simple crackmes. Nous allons donc continuer tranquillement à allier théorie et pratique pour en apprendre davantage sur les bases de l’assembleur, ce qui nous permettra d’analyser plus sereinement de nouveaux programmes.
L’idée n’est pas d’apprendre toutes les instructions assembleur, ce serait beaucoup trop ennuyant et pas la meilleure manière. Par contre, il y a des notions dont on ne peut pas faire abstraction car elles sont présentes dans presque tous les programmes.
Parmi ces notions, on peut citer les structures de contrôle telles que les boucles et les conditions.
Au fur et à mesure que l’on avance en reverse, nous allons découvrir de plus en plus d’instructions. Afin de ne pas alourdir le cours en insérant des instructions dans tous les sens, celles-ci seront présentes en bas de page dans la section
Instructions mentionnées.Il est important de bien prendre le temps de comprendre le fonctionnement des diverses instructions que l’on découvre ensemble.
Le programme de test
Comme d’habitude, je vous propose de réaliser un petit programme que nous compilerons et analyserons. Pour l’instant, nous allons continuer en analyse statique. Nous commencerons à utiliser un debugger une fois que nous serons solides sur nos appuis 💪.
Voici le programme que je vous propose d’étudier :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
#include <stdio.h>
#include <stdlib.h>
void printBin(int nombre)
{
if (nombre < 0)
{
printf("Le nombre doit être un entier positif.\n");
return;
}
unsigned char bits[32];
int i = 0;
while (nombre > 0)
{
bits[i] = nombre % 2;
nombre /= 2;
i++;
}
printf("Représentation binaire : ");
for (int j = i - 1; j >= 0; j--)
{
printf("%d", bits[j]);
}
printf("\n");
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
printf("Utilisation: %s <nombre>\n", argv[0]);
return 1;
}
int nombre = atoi(argv[1]);
printBin(nombre);
return 0;
}
Nous allons le compiler avec les options suivantes : gcc -m32 -fno-stack-protector -fno-pie main.c -o decimal_to_binaire.
Concernant les options :
-fno-pie: nous l’avions déjà utilisé auparavant. Cela permet de faire en sorte que, lors de l’exécution, le programme (les instructions notamment) seront toujours chargées au même endroit. Etant donné que nous allons réaliser une analyse statique, nous ne verrons pas de différence. Néanmoins, en utilisant cette option, cela supprime quelques instructions (pas forcément compliquées), ce qui rend le code assembleur plus clean.-fno-stack-protector: cela permet de supprimer les canaris (ou stack cookies). Il s’agit d’une protection permettant de limiter les vulnérabilités liées aux buffer overflow (dépassement de mémoire tampon). En la supprimant cela supprime quelques instructions et, ainsi, surchargera moins le code assembleur.
Vous pouvez également télécharger le programme ici : decimal_to_binaire.
N’hésitez pas à prendre quelques minutes pour bien comprendre comment fonctionne le programme (ce qu’il prend en entrée, ce qu’il génère en sortie et la manière dont c’est fait).
C’est bon, on peut y aller ? Let’s go !
La fonction main
Je vous propose d’ouvrir le programme compilé decimal_to_binaire avec IDA. Si vous le souhaitez, vous pouvez afficher les adresse dans Options -> General -> Line prefixes.
Ensuite, allez dans la fonction main en double cliquant sur son nom dans la liste des fonctions.
Comme nous avons déjà vu comment fonctionne le prologue ainsi que certaines instructions, nous n’allons pas nous arrêter à chaque instruction, sauf si cela est nécessaire, ou nouveau.
Si vous avez des lacunes, et ça arrive, n’hésitez pas à revenir aux précédents chapitres 😉.
Je vous conseille également d’avoir un petit cahier de brouillon à côté de vous, cela permet de faire des schémas des différents états de la pile et des registres. C’est toujours plus commode que de tout imaginer 😄.
Prologue
Les premières instructions du main sont les suivantes :

Toutes ces instructions correspondent au prologue. Les trois premières instructions permettent de sauvegarder sur la pile la valeur de esp avant de l’aligner via and esp, 0xFFFFFFF01. Cela permettra, à la fin de la fonction main de récupérer la valeur de esp tel qu’il était au moment de rentrer dans le main.
On reconnaît ensuite le fameux push ebp; mov ebp, esp.
A partir de là nous avons une instruction psuh ecx. Alors là il va falloir se concentrer pour bien comprendre ce que contient ecx à ce stade. De l’adresse 0x127D à l’adresse 0x128A, ecx garde toujours la même valeur. Cette valeur est esp + 4 où esp est évidemment la valeur de ce registre lors de l’instruction lea ecx, [esp + 4] et non pas après alignement.
Or, lorsque l’on est au niveau de cette instruction, la stack a cette forme :
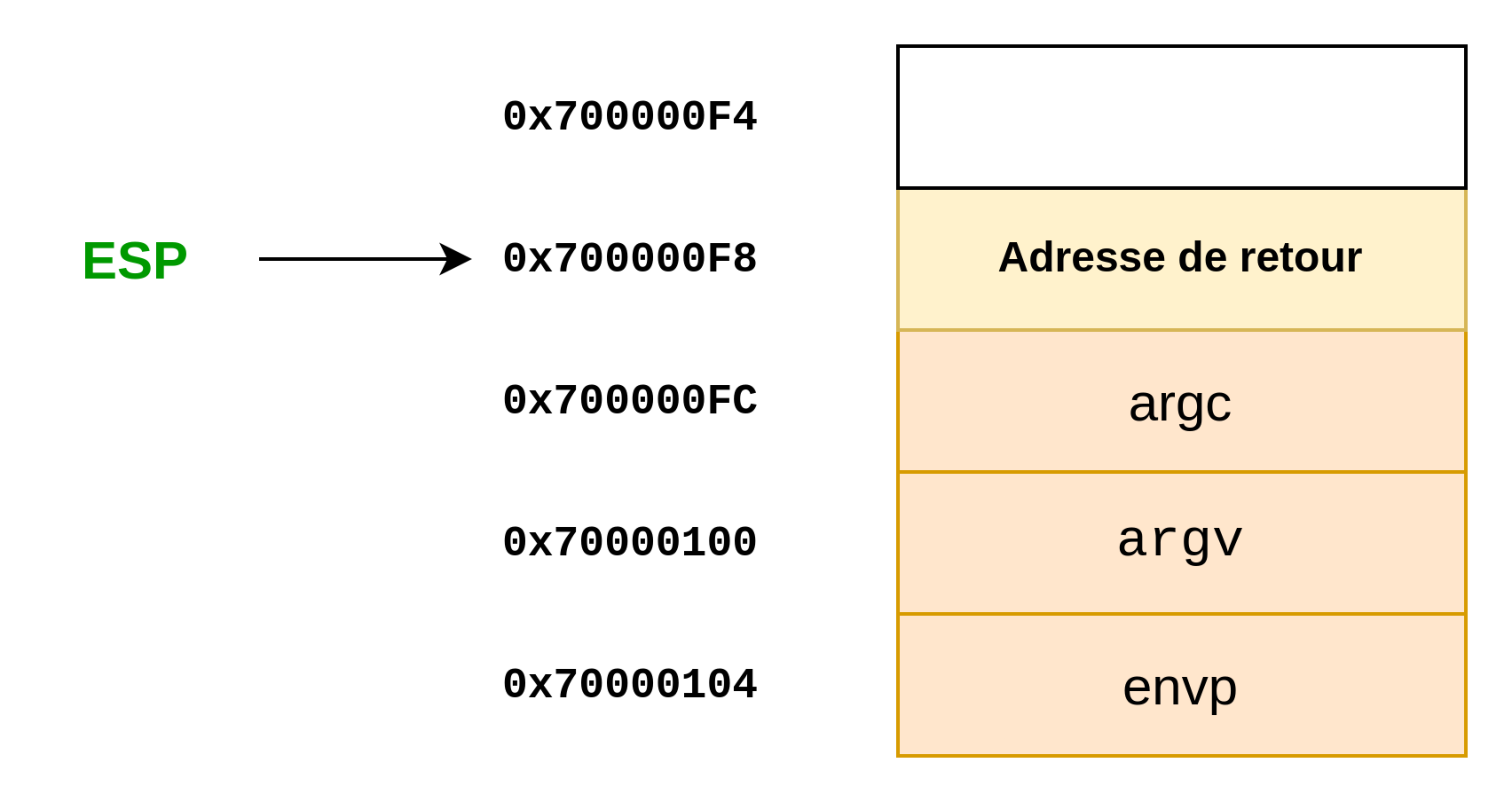
Ainsi, vous l’avez compris, la valeur de ecx qui est mise sur la pile avec push ecx est … l’adresse (ou pointeur vers) le premier argument : argc. En réalité, il n’était pas nécessaire d’empiler ecx car cela n’a pas tellement d’utilité en l’occurrence.
Par contre, il arrive souvent qu’à la fin du prologue, il y ait un certain nombre de
push regde réalisé et qu’à la fin de la fonction, le même nombre depop regsoit réalisé.Cela permet de pouvoir sauvegarder l’ancienne valeur d’un registre, de l’utiliser dans une fonction, puis de restaurer son ancienne valeur avant de quitter la fonction.
Cette méthode est notamment utilisée pour préserver certains registres (ex:
rbx,r12,r13…) qui doivent être conservées selon les règles des conventions d’appel en x86_64.
Enfin, le sub esp, 0x142 permet d’allouer de l’espace dans la stack frame de la fonction main.
Le corps de la fonction main
Les instructions qui suivent immédiatement le prologue sont :

Comme ecx contient l’adresse de argc, après le mov, eax contiendra également l’adresse de argc.
Intéressons-nous à l’instruction cmp dword ptr [eax], 2. Avant de comprendre comment fonctionne cmp, je vois la question venir, prenons le temps de comprendre ce que signifie dword ptr.
Les tailles de données
Vous avez déjà programmé en C. Vous savez donc que, selon le programme et l’utilisation des variables, vous utiliserez des types de variables différents.
Vous savez qu’un char vaut un octet, de même qu’un unsigned char. un int vaut (généralement) 4 octets, de même qu’un unsigned int, un long et unsigned long.
Ainsi, pour une taille donnée, il existe plusieurs types de variables qui ont ladite taille. Etant donné que l’assembleur est situé au plus bas niveau, nous n’avons pas réellement besoin de savoir si un nombre est signé, s’il s’agit d’un int ou long.
En fait, lors de la compilation ces informations sont d’ores et déjà transmises lors de la génération des instructions assembleur correspondantes. Par exemple, si une variable var_a est de type char, elle sera stockée, par exemple, dans ax alors que s’il s’agit d’un int, elle sera stockée dans eax et s’il s’agit d’un long long dans rax.
De même, si la variable est signée, des instructions prenant en compte le signe seront utilisée, le cas échéant, les instructions qui ne tiennent pas compte du signe seront utilisées.
Ainsi, une fois que le programme est compilé, que les bonnes tailles de registres sont choisies et que les bonnes instructions sont choisies, les types des variables ne sont plus d’aucune utilité pour l’exécution du programme.
De cette manière, en assembleur, ce qui nous intéresse lorsque l’on parle d’une donnée ou d’une variable n’est pas son type mais sa taille.
Ces différentes tailles sont les suivante :
byte: 1️⃣ octet, donc 8 bits. Il s’agit de la plus petite taille manipulée. Ainsi vous ne verrez pas d’opérandes qui ont une taille plus petite qu’un octet. Exemple :0xef.word: 2️⃣ octets. Exemple :0xbeef.dword: 4️⃣ octets. “double word” : il a donc deux fois la taille qu’a unword(merci Sherlock 🕵️). Exemple :0xdeadbeef.qword: 8️⃣ octets. “quad word” : il a donc deux fois la taille qu’a undword(disponible seulement en x86_64). Exemple :0xcafebabedeadbeef.
Voici un schéma des différentes tailles à partir d’un pointeur vers l’adresse 0x400010 :

Mais pourquoi ces tailles ne sont visibles que lorsque l’on manipule des pointeurs ? Par exemple :
dword ptr [eax]
En fait lorsqu’un instruction manipule le contenu des registres, tout le contenu du registre est utilisé. Ainsi, si on veut adapter la taille de l’opération, il suffit d’adapter directement la taille du registre en question. Par exemple, si je veux déplacer seulement les 2 octets (un word donc) de eax vers edx, on peut simplement faire mov edx, ax.
La raison pour laquelle, lorsque l’on manipule des pointeurs, il est nécessaire de spécifier la taille à traiter est qu’une adresse mémoire est toujours sur 4 octets ( en 32 bits) ou 8 octets (en 64 bits même si tous les octets ne sont pas utilisés).
Imaginons que nous ayons ces deux variables (pointeurs en l’occurrence) :
1
2
char *un_caractere ; // pointeur vers un char (1 octet)
int *age; // pointeur vers un int (4 octets)
La taille de ces pointeurs (l’adresse pointée) est la même, pourtant les données pointées sont de tailles différentes. Ainsi, les instructions n’agirons pas sur la même taille de données :
- pour
un_caractère, on aura une instruction de ce type ➡️mov reg_d, byte ptr [...] - pour
age, on aura une instruction de ce type ➡️mov reg_d, dword ptr [...]
Un octet en anglais se dit byte. Attention à ne pas confondre avec bit !
En effet, le bit est la plus petite unité manipulable alors qu’un octet/byte est composé de 8 bits !
D’ailleurs, en informatique, on préfère parler en octets/bytes plutôt que bit, c’est plus commode.
Les comparaisons
L’instruction cmp dword ptr [eax], 2 compare les 4 octets pointés par eax avec 2, ou plus précisément 0x000000002. Il existe deux instructions utilisées pour réaliser des comparaisons : cmp et test.
La principale différence entre les deux est la suivante :
cmp3 réalise une soustraction des deux termes (comme avecsubmais sans stocker le résultat)test4 réalise un “et logique”andentre les deux termes sans stocker le résultat
Comme eax contenait un pointeur vers argc, alors cmp dword ptr [eax], 2 compare argc et 2.
J’ai bien pris le temps de comprendre comment fonctionne
cmpettestmais je ne comprends pas comment elles sont utilisées avec les sauts en assembleur ?
Ça tombe bien, nous allons voir cela tout de suite !
ℹ️ Instructions mentionnées
1️⃣ L’instruction and ope_d, ope_s
Opérandes
ope_d: opérande de destination. Peut être :- un registre
- un pointeur
ope_s: opérande source. Peut être- une valeur immédiate
- un registre
- un pointeur (vers une zone mémoire)
Détails
L’instruction and réalise un “et logique” entre les bits des deux opérandes. Le résultat est ensuite sauvegardé dans la première opérande (qui ne peut donc pas être une valeur immédiate).
Exemple
1
2
3
4
mov eax, 0xff00ff00
mov ebx, 0xabcdef12
and eax, ebx ; eax = 0xab00ef00
Équivalent en C
1
2
3
4
int a = 0xff00ff00;
int b = 0xabcdef12;
a = a & b;
Autres formes
Il existe d’autres formes en fonction du type d’opérandes mais le principe est toujours le même.
2️⃣ L’instruction sub ope_d, ope_s
Opérandes
ope_d: opérande de destination. Peut être :- un registre
- un pointeur
ope_s: opérande source. Valeur soustraite. Peut être- une valeur immédiate
- un registre
- un pointeur
Détails
“Sub” provient de “substract” qui signifie soustraire.
Cette instruction réalise ainsi deux actions :
- soustraction de l’opérande source avec l’opérande de destination
ope_d - ope_s. - stockage du résultat (la différence) dans l’opérande de destination
C’est de cette manière que sont réalisées les soustractions.
Contrairement à
add, l’ordre des opérandes est important danssub. En effet, en inversant les opérandes, on inverse le signe du résultat.
Exemple
Faisons la différence de 0xf0000034 avec 0x10000034 :
1
2
3
4
mov eax, 0xf0000034
mov ebx, 0x10000034
sub eax, ebx ; eax = 0xe0000000
Équivalent en C
1
2
3
4
int a = 0xf0000034;
int b = 0x10000034;
a = a - b;
Autres formes
Il existe d’autres formes mais le principe est toujours le même.
3️⃣ L’instruction cmp ope_d, ope_s
Opérandes
ope_d: opérande de destination. Peut être :- un registre
- un pointeur
ope_s: opérande source. Peut être :- une valeur immédiate
- un registre
- un pointeur
Détails
La comparaison avec cmp est effectuée d’une manière qui peut nous paraître bizarre. En effet, cmp effectue la soustraction suivante sub ope_d, ope_s mais sans stocker le résultat. Ainsi le contenu des opérandes restent inchangées.
Par contre, quelques flags parmi les EFLAGS vont être changés en fonction des valeurs des opérandes et du résultat. C’est à partir de ces EFLAGS que l’on saura si les opérandes sont égales ou s’il y en a une plus grande/petite que l’autre etc.
Il est important que vous ayez en tête la manière dont les entiers sont représentés en informatique, notamment les entiers signés avec le complément à deux.
Plus précisément, ce sont les flags ZF, SF, CF et OF qui nous intéressent principalement (et dans une moindre mesure PF). Nous les avions déjà vus brièvement précédemment, profitons-en pour nous rafraîchir la mémoire et rentrer plus dans les détails.
ZF(Zero Flag) :- 1 si les deux opérandes sont égales. La différence des deux termes vaut donc 0.
- 0 si les deux opérandes sont différentes.
SF(Sign Flag) :- 1 si le bit de poids fort du résultat est non nul. Dans le cas d’une opération signée cela implique qu’il est négatif. Dans le cas où elle est non signé, ce flag n’a pas d’importance.
- 0 si le bit de poids fort du résultat est nul
- Exemple : Prenons la soustraction signée suivante :
0x5 - 0x20 = -0x1b. Le résultat étant négatif, le complément à deux de0x1best0xe5qui s’écrit sur 8 bits en binaire0b11100101. Le bit de poids fort étant à1,SFl’est également. Etant donné qu’il s’agit d’une opération signéeSFnous permet de savoir que le résultat est négatif.
CF(Carry Flag) :- 1 si le résultat possède une retenue.
- 0 si le résultat ne possède pas de retenue
- Exemple : Par exemple, pour l’instruction
add al, blsur 8 bits oùalvaut0xFFetblvaut0x01, le résultat est0xFF + 0x01 = 0x100qui ne tient pas sur les 8 bit deal. Cela génère donc une retenue. Lors d’une soustractiona - b, une retenue est générée lorsquebest plus grand quea.
OF(Overflow Flag) :- 1 si un débordement a lieu avec des valeurs signées. Par exemple, cela peut avoir lieu lorsqu’il y a un résultat négatif d’opérandes positifs et inversement. Ce bit n’a pas d’importance lorsque l’on manipule des valeurs non signées.
- 0 s’il n’y a pas eu de débordement
- Exemple : Prenons l’addition signée suivante :
0x7F + 0x8 = 0x87. Ici, le bit de poids fort de0x87est à1: il s’agit donc d’un résultat négatif (-121). Pourtant, les deux termes sont strictement positifs. Il y a donc eu un débordement (overflow).
PF(Parity Flag) :1si le nombre de bits su résultat est pair0sinon
N’hésitez pas à utiliser asmdebugger pour faire quelques tests. Les 4
flagsétudiés sont affichés sur le site lors de l’exécution des instructions.En effet, si l’utilisation de ces flags vous paraît difficile, sachez que c’est normal car cela fait intervenir des notions que l’on utilise pas, en tant qu’humain, tous les jours comme le complément à deux pour représenter des nombres négatifs.
Lors d’une comparaison avec cmp, le processeur ne sait pas si les opérandes sont signées ou non. En fait, il s’en moque à ce stade. C’est pourquoi il va modifier, si besoin est, ces 4 flags bien que certains soient plutôt utilisés lors d’opérations signées (SF et OF) ou non signées (CF).
Exemples
Voici quelques exemples :
| Instruction | ZF | SF | CF | OF |
|---|---|---|---|---|
cmp 1, 5 | ✅ | ✅ | ||
cmp 5, 1 | ||||
cmp 5, 5 | ✅ | |||
cmp 4, 255 | ✅ | |||
cmp 127, 129 | ✅ | ✅ | ✅ |
Je vous conseille de représenter les entiers sous forme binaire et de faire attention à la représentation du complément à deux. En effet, 129 s’il n’est pas signé vaut 129 mais s’il est signé, il vaut -127.
Équivalent en C
Pour l’instruction cmp, il n’y a pas réellement d’équivalent en C. En fait, cmp n’est jamais (sauf exceptions) utilisées autrement qu’avec des sauts. Ainsi, représenter cmp tout seul dans du code C n’a pas de sens. Par contre, dans toutes les conditions du type if, else vous y trouverez un cmp (ou test) dans le code assembleur associé.
4️⃣ L’instruction test ope_d, ope_s
Opérandes
ope_d: opérande de destination. Peut être :- un registre
- un pointeur
ope_s: opérande source. Peut être :- une valeur immédiate
- un registre
Détails
Cette instruction est également utilisée pour réaliser des comparaisons mais son fonctionnement sous-jacent est différent de cmp.
test va exécuter l’instruction and ope_d, ope_s sans stocker le résultat mais en mettant à jour des flags suivants : SF, ZF et PF. test est souvent utilisé pour savoir si un registre est nul ou non.
Exemple
L’instruction test eax, eax permet de voir si eax est nul ou non. En effet, lors de l’exécution de cette instruction, si ZF == 1, c’est que eax est nul. Sinon, cela signifie qu’il est non nul.
Équivalent en C
Même remarque que pour cmp : il n’y a pas réellement d’équivalent direct en C.